Capítulo 6 Manipulação dos dados
Neste capítulo, vamos utilizar o R Commander e quatro conjuntos de dados: juul2, stroke e heart.rate do pacote ISwR (GPL-2 | GPL-3) e Melanoma do pacote MASS (GPL-2 | GPL-3). Diversas funções estão disponíveis para manipular as variáveis de um conjunto de dados, bem como o próprio conjunto de dados.
Inicialmente, vamos carregar os pacotes ISwR e MASS e os conjuntos de dados Melanoma e juul2, nessa ordem.
A função abaixo exibe os 10 primeiros registros do conjunto de dados juul2.
## age height menarche sex igf1 tanner testvol weight
## 1 NA NA NA NA 90 NA NA NA
## 2 NA NA NA NA 88 NA NA NA
## 3 NA NA NA NA 164 NA NA NA
## 4 NA NA NA NA 166 NA NA NA
## 5 NA NA NA NA 131 NA NA NA
## 6 0.17 NA NA 1 101 1 NA NA
## 7 0.17 NA NA 1 97 1 NA NA
## 8 0.17 NA NA 1 106 1 NA NA
## 9 0.17 NA NA 1 111 1 NA NA
## 10 0.17 NA NA 1 79 1 NA NAÉ possível observar que algumas variáveis são categóricas, mas as categorias são expressas como números e seriam tratadas pelo R como numéricas. Consultando a descrição das variáveis do arquivo juul2 (figura 4.22), as categorias das variáveis sex, menarche e tanner têm o significado dado abaixo:
sex:
1 – masculino, 2 – feminino
menarche:
1 – sim, 2 – não
tanner:
estágios de puberdade, codificados de 1 a 5, seguindo a escala de Tanner.
A escala de Tanner (também conhecida como estágios de Tanner) é uma escala do desenvolvimento físico de crianças, adolescente e adultos. A escala define medidas físicas de desenvolvimento baseadas em características externas primárias e secundárias, tais como tamanho da mama, genitais, volume testicular e desenvolvimento de pelos púbicos. A escala foi identificada primeiramente por James Tanner, um pediatra britânico, daí o seu nome (wikipedia).
6.1 Manipulação de variáveis
Com o conjunto de dados juul2 ativo (ele deve aparecer ao lado do rótulo Conjunto de dados ativo abaixo da barra de menus do R Commander), o submenu com as opções de manipulação de variáveis pode ser acessado da seguinte forma:
\[\text{Dados} \Rightarrow \text{Modificação de variáveis no conjunto de dados...}\]
A figura 6.1 mostra a lista de opções para a manipulação de variáveis no R Commander. A opção Definir constrastes para um fator não será discutida neste texto. As demais serão apresentadas a seguir.

Figura 6.1: Recursos disponíveis para a manipulação de variáveis no conjunto de dados ativo.
6.1.1 Recodificar variáveis
O conteúdo desta seção pode ser visualizado neste vídeo.
A operação de recodificação é utilizada para alterar ou agrupar os códigos de uma variável categórica ou numérica inteira. Na mesma operação, podemos definir a variável que recebe a recodificação como da classe factor.
Vamos ilustrar essa operação com dois exemplos.
No primeiro exemplo, vamos recodificar a variável sex de juul2, substituindo o valor 1 por “masculino” e o valor 2 por “feminino”.
A operação de recodificação de variáveis é acessada no R Commander da seguinte forma:
\[\text{Dados} \Rightarrow \text{Modificação de variáveis no conjunto de dados...} \Rightarrow \text{Recodificar variáveis…}\]
A figura 6.2 mostra a caixa de diálogo do R Commander para recodificarmos uma ou mais variáveis. Para especificarmos a recodificação da variável sex, selecionamos a variável sex e escrevemos o nome da variável que será criada após a recodificação no campo Novo nome de variável para recodificação múltipla. Nesse exemplo, colocamos o nome sexo_cat. Caso usássemos o mesmo nome da variável que será recodificada, os valores da variável sex seriam substituídos pelos valores recodificados.
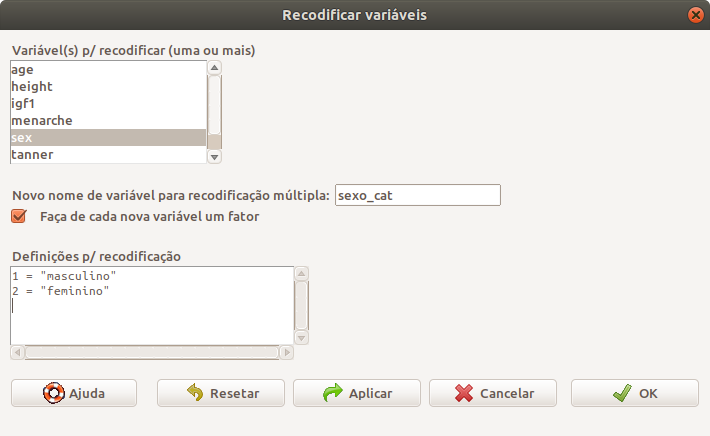
Figura 6.2: Caixa de diálogo para especificarmos a recodificação de uma variável.
Na caixa de texto Definições p/recodificação, escrevemos em cada linha as recodificações. Por exemplo, a primeira linha na figura especifica que o valor 1 será substituído por masculino, a segunda linha especifica que o valor 2 será substituído por feminino. Se marcarmos a opção Faça de cada nova variável um fator, a nova variável será da classe factor. Em muitas situações, isso é o desejado. Ao pressionarmos o botão OK, o comando abaixo é executado:
juul2 <- within(juul2, {
sexo_cat <- Recode(sex, '1 = "masculino"; 2 = "feminino"', as.factor=TRUE)
})Na expressão de recodificação na figura 6.2, a palavra masculino está entre aspas, porque valores de uma variável que são caracteres devem ser expressos entre aspas. Já o valor que será recodificado (1) não aparece entre aspas, porque é um número, não um caracter.
A variável sexo_cat é criada a partir da recodificação da variável sex e é incorporada ao conjunto de dados juul2 como fator. Observem os registros do conjunto de dados após a recodificação e a classe da variável sexo_cat.
## age height menarche sex igf1 tanner testvol weight sexo_cat
## 1 NA NA NA NA 90 NA NA NA <NA>
## 2 NA NA NA NA 88 NA NA NA <NA>
## 3 NA NA NA NA 164 NA NA NA <NA>
## 4 NA NA NA NA 166 NA NA NA <NA>
## 5 NA NA NA NA 131 NA NA NA <NA>
## 6 0.17 NA NA 1 101 1 NA NA masculino## [1] "factor"Vamos entender como essa recodificação foi efetuada. A função utilizada para recodificação é chamada Recode, disponível do pacote car. O primeiro argumento é a variável que será recodificada. O segundo argumento é uma string que especifica as recodificações que serão realizadas, separadas por “;”. O terceiro argumento informa se a variável a ser criada será convertida para fator ou não.
A função Recode vai retornar um vetor com todos os valores da variável sex recodificados. Esse vetor será armazenado na variável sexo_cat. A função within nesse exemplo possui dois argumentos: o conjunto de dados juul2 e a expressão que será executada no primeiro argumento. Essa expressão aparece entre {}. Assim a função Recode vai operar sobre variáveis do conjunto de dados juul2 e gerar um outro data frame com a nova variável recodificada.
Finalmente o data frame juul2 será substituído pelo data frame criado pela função within: juul2 <- within(…)
A operação de recodificação acima poderia também ser realizada da seguinte forma:
Lembremos que, para acessar os valores de uma variável de um data frame, precisamos de usar o $ separando o data frame do nome da variável. A vantagem da função within é que podemos referenciar as variáveis diretamente pelo nome, porque o data frame que contém as variáveis já foi especificado no primeiro argumento.
Para ilustrar um outro exemplo de recodificação, vamos supor que desejemos criar uma outra variável que irá agrupar as categorias I, II e III de Tanner em uma única categoria e as categorias IV e V numa segunda categoria. A figura 6.3 mostra como configurar essa recodificação por meio do R Commander. Observem as diversas maneiras de especificarmos os valores a serem recodificados.
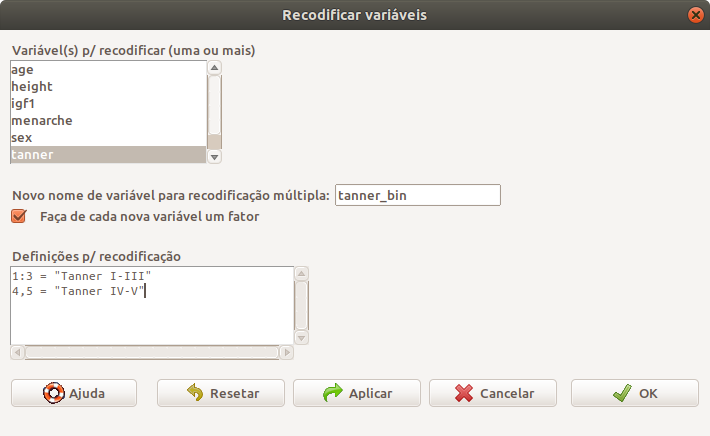
Figura 6.3: Caixa de diálogo para especificarmos uma possível recodificação da variável tanner.
O comando a seguir realiza essa recodificação:
juul2 <- within(juul2, {
tanner_bin <- Recode(tanner, '1:3 = "Tanner I-III";c(4,5) = "Tanner IV-V"',
as.factor=TRUE)
})A função Recode permite a recodificação de variáveis das classes integer, numeric, character, factor e logical. Na recodificação, a nova variável pode ser criada como factor ou não.
A seção seguinte mostra uma opção no menu do R Commander que pode ser utilizada para converter uma variável da classe numeric para factor.
6.1.2 Converter variável numérica para fator
O conteúdo desta seção pode ser visualizado neste vídeo.
Para analisar e visualizar as variáveis categóricas corretamente no R, temos que transformá-las em fatores, outro nome utilizado em análises estatísticas para variáveis categóricas. Para realizarmos a conversão de uma variável em fator no R Commander, selecionamos a opção:
\[\text{Dados} \Rightarrow \text{Modificação var. no conjunto de dados...} \Rightarrow \text{Converter var. numérica para fator...}\]
Na caixa de diálogo que Converter Variáveis Numéricas p/ Fator (figura 6.4), selecionamos a variável que será convertida e escolhemos uma das opções: manter as categorias expressas como números ou fornecer nomes às categorias. Vamos dar nomes às categorias nesse exemplo. No campo Novo nome de variável ou prefixo para múltiplas variáveis, digitamos o nome da variável que será criada. Se não for especificado nenhum nome nesse campo, os nomes das categorias serão sobrescritos aos valores numéricos na própria variável que será convertida e não será criada uma nova variável.
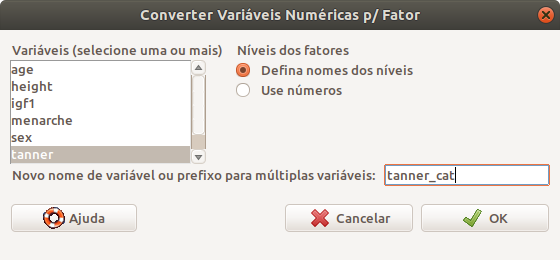
Figura 6.4: Passos para criar as categorias de uma variável: selecionamos a variável na lista da esquerda, escolhemos se as categorias serão dadas como texto e fornecemos o nome da nova variável. Clicamos em OK.
Como selecionamos a opção de fornecer os nomes para as categorias, ao clicarmos em OK na figura 6.4, uma nova caixa de diálogo aparece para darmos os nomes das categorias para cada valor numérico (figura 6.5). Finalmente, ao clicarmos em OK, a nova variável, tanner_cat, será criada com as categorias apropriadas.
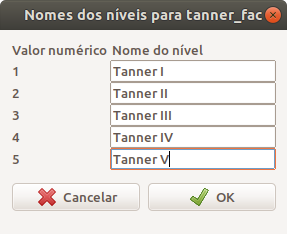
Figura 6.5: Especificação das categorias para a variável tanner.
O comando executado é mostrado abaixo:
juul2 <- within(juul2, {
tanner_cat <- factor(tanner,
labels=c('Tanner I','Tanner II','Tanner III','Tanner IV','Tanner V'))
})Observamos que foi utilizada a função factor, mostrada na seção 3.8. A única diferença é que aqui foi usado o argumento labels e não levels. Nesse caso, o efeito é o mesmo.
Repitam o procedimento para a variável menarche, criando um nova variável menarca_cat.
Lembremos que também criamos uma variável, sexo_cat, da classe factor na seção 6.1.1, a partir da recodificação da variável sex, fazendo o argumento as.factor da função igual a TRUE.
6.1.3 Reordenar os níveis dos fatores
O conteúdo desta seção pode ser visualizado neste vídeo.
Em diversas situações, por exemplo, ao montar uma tabela de contingência, poderíamos desejar alterar a ordem com que os níveis de um fator são apresentados nessa tabela.
Nesta seção, vamos utilizar o conjunto de dados stroke do pacote ISwR (GPL-2 | GPL-3).
Esse conjunto de dados contém todos os casos de AVC (acidente vascular cerebral) in Tartu na Estônia, durante o período de 1991 a 1993, com acompanhamento até 1 jan 1996.
Há várias variáveis nesse conjunto de dados, mas, nesse caso, estamos interessados nas variáveis dead e minf.
A variável dead é uma variável lógica que indica se a pessoa morreu ou não durante o estudo. A variável minf é um fator que indica se a pessoa possui ou não histórico de infarto do miocárdio.
Vamos supor que queiramos calcular o risco relativo de morte para pessoas com AVC e histórico ou não de infarto do miocárdio.
Esse risco é obtido dividindo-se o risco de morte para aqueles com histórico de infarto do miocárdio pelo risco de morte para aqueles sem histórico de infarto do miocárdio.
Então vamos verificar a associação entre as variáveis minf e dead.
Recordando, para abrirmos o conjunto de dados ISwR via R Commander, executamos a função
na área de script do R commander e, em seguida, selecionamos o conjunto stroke via:
\[\text{Dados} \Rightarrow \text{Conjunto de dados em pacotes} \Rightarrow \text{Ler dados de pacotes 'atachados'...}\]
Em seguida, selecionamos o conjunto de dados stroke no pacote ISwR (figura 6.6).
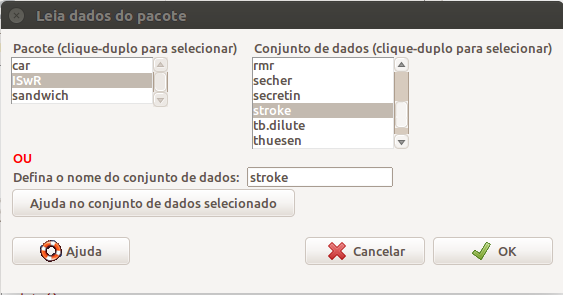
Figura 6.6: Tela para a leitura do conjunto de dados stroke do pacote ISwR via R Commander.
As tabelas que mostram a contagem para cada combinação das categorias das variáveis categóricas são também chamadas tabelas de contingência. Quando há duas variáveis categóricas binárias, a tabela de contingência também é chamada tabela de dupla entrada ou tabela 2x2.
Vamos montar uma tabela 2x2 no R Commander. Selecionamos a opção:
\[\text{Estatísticas} \Rightarrow \text{Tabelas de contingência} \Rightarrow \text{Tabela de dupla entrada...}\]
Na tela de configuração do comando para analisar uma tabela 2x2, é preciso selecionar a variável cujas categorias aparecerão nas linhas da tabela (minf) e a outra variável cujas categorias comporão as colunas da tabela (dead) (figura 6.7).
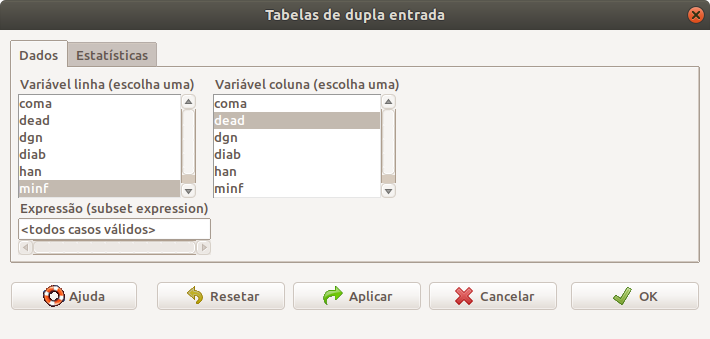
Figura 6.7: Selecionando as variáveis da tabela tabela 2x2.
Os resultados são mostrados na figura 6.8. As frequências da tabela 2x2 são mostradas na primeira tabela. Observem que os valores das variáveis nas colunas e linhas são ordenados, por padrão, em ordem alfabética. Vemos que a tabela foi construída com o nível No de história de infarto do miocárdio na primeira linha e Yes na segunda linha. O nível FALSE da variável dead aparece na primeira coluna e TRUE na segunda.
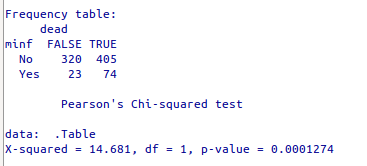
Figura 6.8: Resultado da análise da tabela de contingência 2x2 por meio do R Commander.
Para calcularmos o risco relativo corretamente, será necessário invertermos a ordem tanto das linhas quanto das colunas, já que o nível de referência do fator de risco é sem histórico de infarto de miocárdio e o risco que queremos estimar é o de morrer e não o de sobreviver.
Então precisamos inverter a ordem com que os níveis das variáveis minf e dead são apresentados. Para alterarmos a ordem dos níveis da variável minf, vamos em:
\[\text{Dados} \Rightarrow \text{Modificação de var. no conjunto de dados...} \Rightarrow \text{Reordenar níveis dos fatores…}\]
Na caixa de diálogo Reordene Níveis do Fator (figura 6.9), selecionamos a variável minf. Se selecionarmos a opção Faça fator ordenado, iremos fazer com que a variável passe a ser uma variável categórica ordinal. Como a variável minf é dicotômica, não vamos marcar essa opção.
Podemos ou não criar uma nova variável. Se utilizarmos a mesma variável, uma tela irá solicitar a confirmação se desejamos sobrescrever a variável. Nesse exemplo, vamos sobrescrever a variável minf, por isso não vamos alterar o conteúdo do campo Nome do Fator.
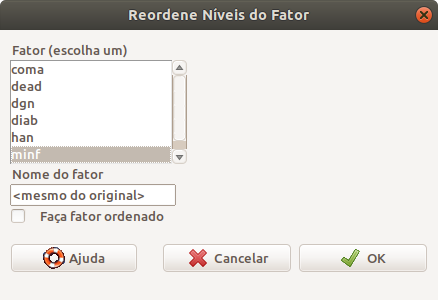
Figura 6.9: Caixa de diálogo para selecionar a variável minf cujos níveis serão reordenados.
Ao clicarmos em OK, uma nova caixa de diálogo nos permite especificar a nova ordem dos níveis (figura 6.10).
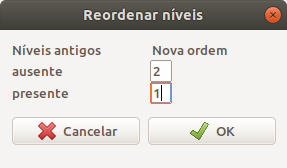
Figura 6.10: Caixa de diálogo para especificarmos como os níveis da variável minf serão ordenados.
O comando executado é mostrado abaixo. Observem que os níveis da variável minf foram colocados na ordem desejada.
A função factor vai reordenar os níveis de minf de acordo com a ordem especificada no argumento levels e o resultado vai ser gravado na própria variável minf. Observem o $ usado para separar a variável minf do conjunto de dados stroke, já que stroke é um data.frame, portanto as suas variáveis são referenciadas como elementos de uma lista.
Se tentássemos fazer a mesma coisa com a variável dead, não conseguiríamos, porque essa variável não é da classe factor. Nesse caso, podemos recorrer à função Recode (seção 6.1.1), ou usar a linha de comando, como mostrado a seguir.
Podemos copiar e colar o comando anterior e substituir a variável minf pela variável dead e os níveis de minf pelos níveis de dead na ordem desejada: TRUE e FALSE, como mostrado no comando abaixo:
Agora a classe da variável dead passa a ser da classe factor.
Ao executarmos o comando anterior e novamente montarmos a tabela 2x2, relacionando as variáveis minf e dead, obtemos o resultado mostrado na figura 6.11. Agora o nível de referência da variável história de infarto do miocárdio está na linha de baixo e a primeira coluna mostra o número de mortes para os que possuem ou não histórico de infarto do miocárdio.
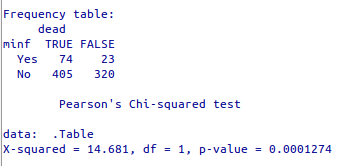
Figura 6.11: Análise da tabela 2 x 2 (minf x dead) após a reordenação dos níveis dos fatores.
Os dois comandos a seguir mostram que os nívels de minf e dead estão agora na ordem desejada.
## [1] "Yes" "No"## [1] "TRUE" "FALSE"6.1.4 Computar nova variável
O conteúdo desta seção pode ser visualizado neste vídeo.
Vamos supor que desejamos calcular o índice de massa corporal (IMC) para as observações do conjunto de dados juul2. Para isso, utilizamos a seguinte opção no R Commander:
\[\text{Dados} \Rightarrow \text{Modificação de variáveis no conjunto de dados...} \Rightarrow \text{Computar nova variável…}\]
A figura 6.12 mostra a caixa de diálogo para computar o IMC a partir das variáveis weight e height. A variável height foi dividida por 100, porque ela está em cm.
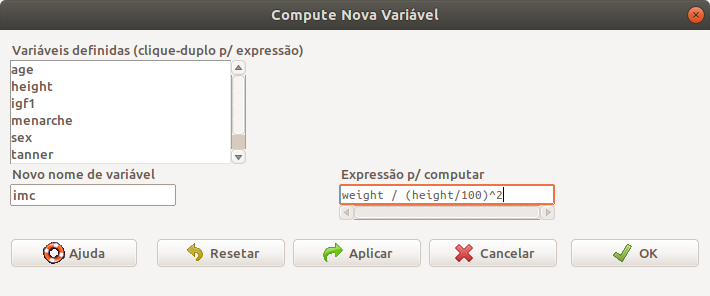
Figura 6.12: Caixa de diálogo para especificarmos o cálculo do IMC.
O comando executado é mostrado abaixo:
A função with aqui funciona de maneira semelhante à função within, porém ela não gera um novo data frame. Nesse exemplo, o resultado é um vetor com os valores de imc para cada registro de juul2.
Vejamos os últimos 6 valores das variáveis weight, height e imc no conjunto de dados juul2:
## weight height imc
## 1334 52.5 164.4 19.42476
## 1335 70.5 168.9 24.71325
## 1336 NA NA NA
## 1337 NA NA NA
## 1338 NA NA NA
## 1339 68.0 168.0 24.09297Essa operação também poderia ser realizada da seguinte forma:
Vamos ver um outro exemplo. Vamos supor que queiramos criar uma variável binária que indique se cada pessoa é menor ou maior de 18 anos. Novamente, vamos em:
\[\text{Dados} \Rightarrow \text{Modificação de variáveis no conjunto de dados...} \Rightarrow \text{Computar nova variável…}\]
A figura 6.13 mostra a caixa de diálogo para computar uma variável binária que indica se a pessoa é maior de idade ou não.
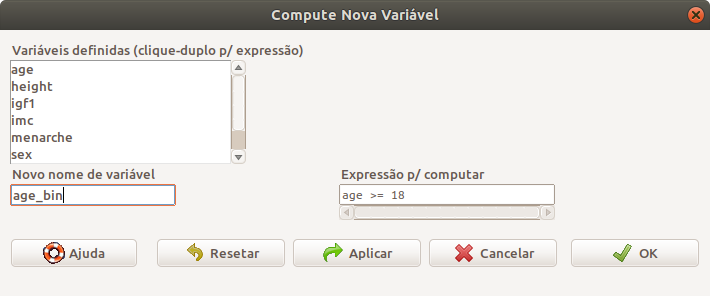
Figura 6.13: Caixa de diálogo para computar uma variável binária que indica se a pessoa é maior de idade ou não.
Ao clicarmos em OK, o comando executado é mostrado a seguir:
Vejamos os últimos 6 valores das variáveis age e age_bin no conjunto de dados juul2:
## age age_bin
## 1334 58.95 TRUE
## 1335 60.99 TRUE
## 1336 62.73 TRUE
## 1337 65.00 TRUE
## 1338 67.88 TRUE
## 1339 75.12 TRUEObservem que a nova variável é uma variável lógica, assumindo os valores TRUE para aqueles maiores de 18 anos e FALSE para os menores de 18 anos.
6.1.5 Agrupar em classes uma variável numérica
O conteúdo desta seção pode ser visualizado neste vídeo.
Frequentemente é necessário agrupar os valores de uma variável numérica em classes (ou faixas de valores). Um caso clássico é o de agrupar os valores de idade em faixas etárias. Para realizarmos um agrupamento em classes no R Commander, usamos a opção:
\[\text{Dados} \Rightarrow \text{Modificação var. no conjunto de dados...} \Rightarrow \text{Agrupar em classes var. numérica…}\]
A figura 6.14 mostra a caixa de diálogo para especificarmos como será realizado o agrupamento. É preciso escolher a variável a ser agrupada, o nome para a variável que será criada, o número de classes a serem utilizadas, como serão nomeadas as classes e como será realizado o agrupamento. Nesse exemplo, foi escolhida a variável age, a variável a ser criada será faixa_etaria, o número de classes é 10, cada classe será identificada pelo intervalo de valores e cada classe terá a mesma largura.
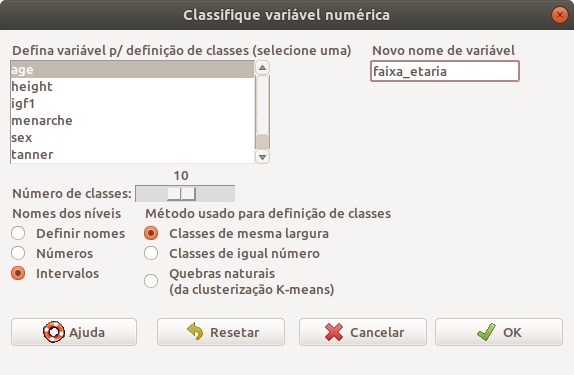
Figura 6.14: Caixa de diálogo para especificarmos como uma variável numérica será agrupada em faixas.
O comando executado é mostrado abaixo. A função binVariable do pacote RcmdrMisc foi utilizada para realizar o agrupamento.
Vejamos os últimos 6 valores das variáveis age e faixa_etaria no conjunto de dados juul2:
## age faixa_etaria
## 1334 58.95 (58.2,66.4]
## 1335 60.99 (58.2,66.4]
## 1336 62.73 (58.2,66.4]
## 1337 65.00 (58.2,66.4]
## 1338 67.88 (66.4,74.7]
## 1339 75.12 (74.7,83.1]Como a variável criada, faixa_etaria, é um fator, podemos ver as classes que foram criadas por meio da função levels.
Como nesse agrupamento selecionamos a opção intervalos para os nomes dos níveis (classes), o argumento labels na função binVariable deve ser NULL. Se tivéssemos escolhido a opção Definir nomes para os níveis, uma nova tela iria aparecer para especificarmos os nomes, e o argumento labels conteria um vetor com os nomes especificados. Caso a opção para os níveis fosse Números, o argumento labels seria igual a FALSE, e cada classe receberia um número inteiro correspondente à ordem da classe.
Nesse exemplo, criamos classes de mesma largura. Outra opção seria criar classes com tamanhos diferentes, mas que contivessem aproximadamente o mesmo número de observações. Finalmente, seria possível realizar uma análise de cluster para definir o agrupamento.
Observamos que as faixas criadas são um tanto artificiais. Se quisermos definir as faixas etárias de acordo com os padrões utilizados para faixas etárias, teremos que recorrer a outras funções. Uma função mais flexível para transformar uma variável numérica em categórica é a função cut. Vamos supor que desejamos criar as seguintes faixas etárias:
- crianças: 0 até 10 anos;
- adolescentes: acima de 10 até 20 anos;
- adultos: acima de 20 até 60 anos;
- idosos: acima de 60 anos.
O comando abaixo mostra como usar a função cut para realizar essa estratificação:
juul2$faixa_etaria2 <- with(juul2, cut(x = age,
breaks = c (0,10, 20, 60, Inf),
labels=c('(0,10]','(10-20]','(20-60]','>60'),
ordered_result = TRUE, right = TRUE))Vejamos os últimos 6 valores das variáveis age e faixa_etaria2 no conjunto de dados juul2:
## age faixa_etaria2
## 1334 58.95 (20-60]
## 1335 60.99 >60
## 1336 62.73 >60
## 1337 65.00 >60
## 1338 67.88 >60
## 1339 75.12 >60Vamos entender os argumentos da função cut:
1) o argumento x especifica que variável será transformada;
2) o argumento breaks especifica os limites de cada categoria (intervalo) que será criada;
3) o argumento labels especifica os rótulos que serão atribuídos a cada categoria. Se o argumento labels não for especificado, os rótulos serão criados automaticamente, de acordo com os limites especificados pelo argumento breaks e como os limites dos intervalos serão tratados (argumento right);
4) o argumento ordered_result especifica se as categorias criadas serão ordenadas ou não. Nesse caso, a variável criada será ordinal;
5) se o argumento right for TRUE, os intervalos criados serão fechados à direita e abertos à esquerda; se for FALSE, os intervalos criados serão abertos à direita e fechados à esquerda.
6.1.6 Padronizar variáveis
O conteúdo desta seção pode ser visualizado neste vídeo.
Em diversas situações, pode ser necessário realizar a padronização de variáveis numéricas. Em geral a padronização de uma variável X cria uma outra variável Y, por meio da seguinte operação:
\[ Y = \frac{X-\mu}{\sigma}\] onde \(\mu\) é a média e \(\sigma\) é o desvio padrão da variável X.
Para realizarmos a padronização de variáveis no R Commander, selecionamos a opção:
\[\text{Dados} \Rightarrow \text{Modificação de variáveis no conjunto de dados...} \Rightarrow \text{Padronizar variáveis...}\]
Na caixa de diálogo Padronize Variáveis (figura 6.15), selecionamos as variáveis a serem padronizadas e pressionamos o botão OK.
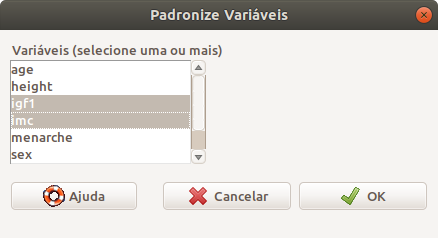
Figura 6.15: Caixa de diálogo para selecionarmos as variáveis que serão padronizadas.
O comando executado pelo R Commander é mostrado abaixo:
juul2 <- local({
.Z <- scale(juul2[,c("igf1","imc")])
within(juul2, {
Z.imc <- .Z[,2]
Z.igf1 <- .Z[,1]
})
})Vamos entender esse comando. A função scale faz a padronização das variáveis especificadas em seu argumento. Nesse exemplo, foram especificadas duas variáveis de juul2: igf1 e imc. O resultado da padronização é armazenado no objeto .Z, que é uma matriz com duas colunas, onde a primeira coluna contém os valores padronizados de igf1 e a segunda coluna os valores padronizados de imc. Novamente a função within é utilizada para criar um data frame a partir de juul2, acrescentando duas variáveis, Z.imc e Z.igf1, que contêm respectivamente a segunda e primeira coluna de .Z. Finalmente juul2 é substituído por esse novo data frame.
Se observarmos atentamente o comando acima, verificamos que o objeto .Z foi criado apenas para realizar a padronização das variáveis. Após as duas padronizações serem armazenadas em variáveis do juul2, o objeto .Z não é mais necessário. A função local evita que o objeto .Z seja armazenado no sistema; ele é descartado após a execução do comando. A função local não é necessária para realizar a operação. Caso ela não fosse utilizada, o objeto .Z continuaria a existir na memória.
As variáveis Z.imc e Z.igf1 são adicionadas ao data frame:
## imc Z.imc igf1 Z.igf1
## 1334 19.42476 0.2618718 218 -0.7142839
## 1335 24.71325 2.0078782 226 -0.6675100
## 1336 NA NA NA NA
## 1337 NA NA 106 -1.3691183
## 1338 NA NA 217 -0.7201306
## 1339 24.09297 1.8030923 135 -1.19956306.1.7 Remover variáveis de um conjunto de dados
Os conteúdos desta seção e das seções 6.1.8 e 6.1.9 podem ser visualizados neste vídeo.
Ao trabalharmos com um conjunto de dados, frequentemente criamos diversas variáveis que, mais tarde, podem não ser mais necessárias. Por exemplo, em seções anteriores, convertemos as variáveis sex, tanner e menarche do conjunto de dados juul2 para fator, gerando as variáveis sexo_cat, tanner_cat e menarca_cat, respectivamente. Após essas conversões, as variáveis sex, tanner e menarche não são mais necessárias e poderiam ser excluídas.
Para remover variáveis de um conjunto de dados que não são mais necessárias no R Commander, usamos a opção:
\[\text{Dados} \Rightarrow \text{Modificação var. no conjunto de dados...} \Rightarrow \text{Apagar var. de conjunto de dados…}\]
Na caixa de diálogo Eliminar Variáveis (figura 6.16), selecionamos as variáveis que desejamos remover. Vamos excluir as variáveis sex, tanner e menarche.
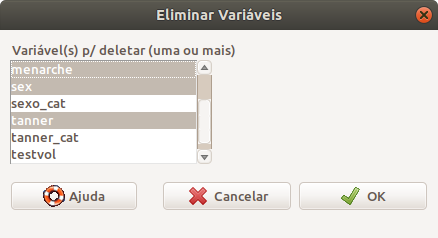
Figura 6.16: Caixa de diálogo para especificarmos que variáveis serão eliminadas do conjunto de dados.
Ao pressionarmos o botão OK e, após a tela de confirmação, o comando abaixo será executado. Para removermos uma variável de um conjunto de dados, basta atribuirmos NULL a ela.
6.1.8 Renomear variáveis
Após removermos as antigas variáveis sex, tanner e menarche do conjunto de dados juul2, vamos alterar os nomes das variáveis sexo_cat, tanner_cat e menarca_cat para sexo, tanner e menarca respectivamente. Para renomear variáveis no R Commander, utilizamos a opção:
\[\text{Dados} \Rightarrow \text{Modificação de variáveis no conjunto de dados...} \Rightarrow \text{Renomear variáveis…}\]
A caixa de diálogo da figura 6.17 permite a seleção das variáveis que serão renomeadas.
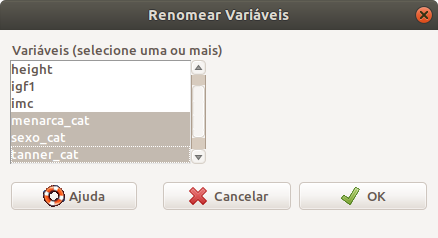
Figura 6.17: Caixa de diálogo para selecionar as variáveis que serão renomeadas.
Ao pressionarmos o botão OK, especificamos os novos nomes das variáveis na tela Nomes das Variáveis (figura 6.18).
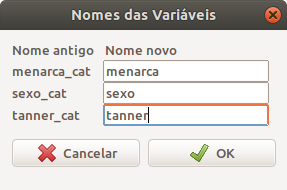
Figura 6.18: Caixa de diálogo para especificarmos os novos nomes das variáveis selecionadas.
Após pressionarmos o botão OK, o comando abaixo será executado. Para alterarmos o nome de uma variável, basta alterar o seu nome na posição correspondente da variável no vetor names(conjunto de dados). Nesse exemplo, as três variáveis ocupam as 9a, 6a e 8a posições, respectivamente, no conjunto de dados juul2.
6.1.9 Adição do número de observações aos dados
A opção abaixo simplesmente adiciona mais uma variável ao conjunto de dados, onde cada valor indica o número da linha no conjunto de dados.
\[\text{Dados} \Rightarrow \text{Modif. de var. no conj. de dados...} \Rightarrow \text{Adicionar número da obs. nos dados…}\]
Observem no comando gerado que foi criada uma variável (ObsNumber) que contém a sequência de números inteiros de 1 a 1339 (o número de registros em juul2)
## igf1 sexo
## 1 90 <NA>
## 2 88 <NA>
## 3 164 <NA>
## 4 166 <NA>
## 5 131 <NA>
## 6 101 masculinoSalvem o conjunto de dados juul2 após a conversão das variáveis sex, menarche e tanner para fator em um arquivo de dados no seu computador para que não tenham que repetir essas transformações a cada vez que forem utilizar esse conjunto de dados.
6.1.10 Converter variáveis do tipo character para fatores
Para realizarmos a conversão de uma variável do tipo character para fator, utilizamos a opção:
\[\text{Dados} \Rightarrow \text{Modif. de var. no conj. de dados...} \Rightarrow \text{Convert character variables to factors…}\]
Na caixa de diálogo dessa opção, basta selecionar a variável. Se desejarmos criar uma nova variável do tipo fator, mantendo a antiga variável como character, digitamos o nome da nova variável no campo Novo nome de variável ou prefixo para múltiplas variáveis e clicamos em OK. Caso desejemos simplesmente transformar a variável em fator, mantendo o mesmo nome, não mexemos no campo Novo nome de variável ou prefixo para múltiplas variáveis e clicamos em OK. Nesse caso, o programa irá perguntar se desejamos sobrescrever a variável. Se respondermos Não à pergunta, o comando será cancelado e a variável não será convertida.
Caso mais de uma variável seja selecionada, se desejarmos criar novas variáveis do tipo fator a partir das variáveis selecionadas, mantendo as antigas variáveis como character, precisamos digitar um prefixo no campo Novo nome de variável ou prefixo para múltiplas variáveis. O nome de cada nova variável que será criada será o nome da variável que será convertida precedido desse prefixo. Em seguida, cliamos em OK. Caso desejemos simplesmente transformar as variáveis em fator, mantendo o mesmo nome, não mexemos no campo Novo nome de variável ou prefixo para múltiplas variáveis e clicamos em OK. Nesse caso, o programa irá perguntar se desejamos sobrescrever cada variável selecionada. Se respondermos Não a alguma das perguntas, o comando será cancelado e nenhuma variável será convertida.
6.2 Manipulação do conjunto de dados
Além de manipular variáveis em um conjunto de dados, há uma série de recursos que permitem a manipulação do próprio conjunto de dados. A figura 6.19 mostra as opções disponíveis no R Commander. Esse submenu pode ser acessado a partir da barra de menus da seguinte forma:
\[Dados \Rightarrow Conjunto\ de\ dados\ ativo\]

Figura 6.19: Recursos disponíveis para a manipulação do conjunto de dados ativo.
As duas últimas opções desse menu (Salvar conjunto de dados ativo… e Exportar conjunto de dados ativo…) foram mostradas no capítulo 4.
6.2.1 Seleção do conjunto de dados ativo
Os conteúdos desta seção e das seções 6.2.2 e 6.2.3 podem ser visualizados neste vídeo.
As opções disponíveis no R Commander atuam sobre o conjunto de dados que está ativo no R Commander. Embora vários conjuntos de dados possam estar carregados na área de trabalho do R, somente um conjunto de dados está ativo em cada momento no R Commander.
Para escolhermos o conjunto de dados que estará ativo no R Commander, selecionamos a opção
\[Dados \Rightarrow Conjunto\ de\ dados\ ativo \Rightarrow\ Selecionar\ conjunto\ de\ dados\ ativo...\]
Na tela Selecione o conjunto de dados (figura 6.20), são mostrados os conjuntos de dados que estão carregados no R na sessão corrente. Vamos selecionar o conjunto Melanoma.
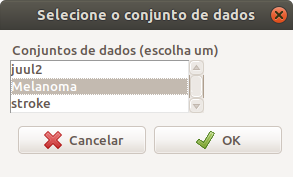
Figura 6.20: Caixa de diálogo para selecionar o conjunto de dados ativo no R Commander.
Um atalho para selecionarmos o conjunto de dados ativo é clicarmos sobre o nome do conjunto de dados ativo no momento, ao lado do rótulo Conjunto de dados, abaixo da barra de menus.
6.2.2 Visualização dos dados
O botão Ver conjunto de dados, abaixo da barra de menus, exibe o conteúdo do conjunto de dados. Para escolhermos que variáveis ou que subconjunto de observações serão visualizados, selecionamos a opção:
\[Dados \Rightarrow Conjunto\ de\ dados\ ativo \Rightarrow \ View\ data...\]
Na caixa de diálogo dessa opção (figura 6.21), podemos selecionar as variáveis que serão visualizadas ou marcar para visualizar todas as variáveis. Nesse exemplo, selecionamos as variáveis status e thickness e vamos exibir somente as observações relativas aos óbitos por melanoma (status == 1).
Ao pressionarmos o botão OK, somente as duas variáveis serão exibidas para os óbitos devido ao melanoma.
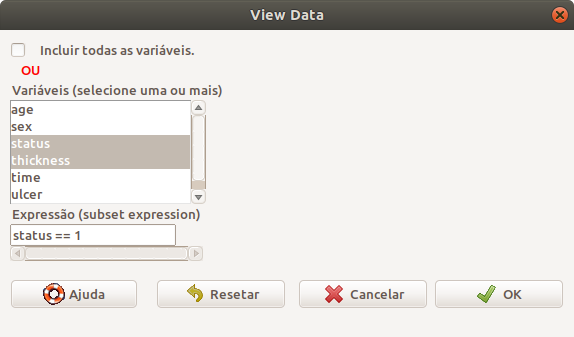
Figura 6.21: Caixa de diálogo para selecionar as variáveis a serem visualizadas.
6.2.3 Renovar conjunto de dados ativo…
Às vezes é necessário renovar o conjunto de dados no R Commander, especialmente quando fazemos alguma alteração no conjunto de dados diretamente a partir da linha de comando, para que essas alterações fiquem visíveis nas opções de menu e telas de configuração do R Commander.
Vamos supor que tenhamos convertido as variáveis status e sex do conjunto de dados Melanoma, executando o comando abaixo na área de script do R Commander, sem utilizarmos a opção para converter variável numérica para fator do menu.
Melanoma <- within(Melanoma, {
status_fac <- factor(status, labels=c('óbito por melanoma','vivo',
'óbito por outras causas'))
sexo_fac <- factor(sex, labels=c('feminino','masculino'))
})As variáveis status_fac e sexo_fac foram criadas e aparecem quando clicamos no botão Ver conjunto de dados, mas se tentarmos criar um gráfico de barras a partir do menu:
\[\text{Gráficos}\]
vemos que a opção Gráfico de barras não está habilitada. É necessário renovar o conjunto de dados ativo.
Para renovar o conjunto de dados ativo, utilizamos a opção:
\[\text{Dados} \Rightarrow \text{Conjunto de dados ativo} \Rightarrow \text{Renovar conjunto de dados ativo (Refresh)}\]
Após essa operação, a opção Gráfico de barras passa a estar habilitada e podemos selecionar uma das variáveis status_fac ou sexo_fac para criarmos um diagrama de barras.
6.2.4 Ajuda no conjunto de dados ativo (se disponível)
Os conteúdos desta seção e das seções 6.2.5 e 6.2.6 podem ser visualizados neste vídeo.
A opção do menu abaixo irá mostrar a ajuda sobre o conjunto de dados ativo, se ela estiver disponível. Em geral os conjuntos de dados disponíveis em pacotes do R oferecem uma ajuda sobre o seu conteúdo, especificando que variáveis estão presentes no conjunto de dados e as respectivas unidades e codificações.
Por meio da opção abaixo, a ajuda para o conjunto de dados ativo será disponibilizada no seu navegador Web padrão.
\[\text{Dados} \Rightarrow \text{Conjunto de dados ativo} \Rightarrow \text{Ajuda no conjunto de dados (se disponível)}\]
Com o Melanoma como conjunto de dados ativo, o comando a seguir será executado:
6.2.5 Variáveis no conjunto de dados ativo
A opção abaixo lista os nomes das variáveis do conjunto de dados ativo.
\[\text{Dados} \Rightarrow \text{Conjunto de dados ativo} \Rightarrow \text{Variáveis no conjunto de dados ativo}\]
Essa opção executa a função names(conjunto de dados ativo).
6.2.6 Definir nomes dos casos
Vamos supor que o conjunto de dados ativo contenha uma coluna com os nomes dos pacientes. O script abaixo cria um “nome” para cada linha, onde o primeiro nome é “n1” e o último é “n205”. Não se preocupem em entender esse script agora.
nomes = NULL
for (i in 1:nrow(Melanoma)) {
nomes = c(nomes, paste("n", i, sep=''))
}
Melanoma$nomes = nomesSe verificarmos os registros de Melanoma, veremos a adição da variável nomes. Além disso, os nomes das linhas são os números 1 até 205, precedidos da letra n. A função row.names(data frame) exibe os nomes das linhas do data frame.
## time status nomes
## 1 10 3 n1
## 2 30 3 n2
## 3 35 2 n3
## 4 99 3 n4
## 5 185 1 n5
## 6 204 1 n6## [1] "1" "2" "3" "4" "5" "6"Para fazermos com que os nomes das linhas sejam iguais aos de uma variável de um conjunto de dados, usamos a opção:
\[\text{Dados} \Rightarrow \text{Conjunto de dados ativo} \Rightarrow \text{Definir nomes dos casos}\]
Na caixa de diálogo Defina nome do caso (figura 6.22), selecionamos a variável que contém os nomes e pressionamos o botão OK. Pode ser necessário renovar o conjunto de dados ativo para a variável nomes aparecer na lista de variáveis (seção 6.2.3).
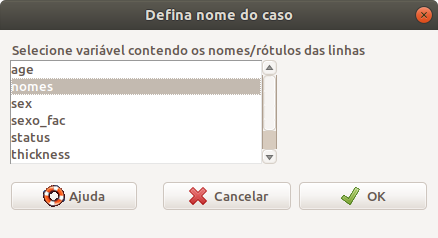
Figura 6.22: Caixa de diálogo para selecionar a variável que contém os nomes que serão usados para as observações do conjunto de dados ativo.
Os comandos executados são mostrados a seguir. Os valores das linhas do Melanoma são substituídos pelos valores da variável nomes e essa variável é removida do conjunto de dados.
Vejam as alterações ocorridas no conjunto de dados:
## time status
## n1 10 3
## n2 30 3
## n3 35 2
## n4 99 3
## n5 185 1
## n6 204 1## [1] "n1" "n2" "n3" "n4" "n5" "n6"6.2.7 Definir subconjunto de dados ativo
O conteúdo desta seção e da seção 6.2.7.1 podem ser visualizados neste vídeo.
Vamos supor que desejamos fazer uma análise somente com menores de idade no conjunto de dados Melanoma. Então temos que gerar um subconjunto de dados. No R Commander, selecionamos a opção:
\[\text{Dados} \Rightarrow \text{Conjunto de dados ativo} \Rightarrow \text{Definir subconjunto de dados ativo}\]
Na caixa de diálogo Definir um subconjunto dos dados (figura 6.23), damos um nome para o novo conjunto de dados, indicamos que variáveis serão incluídas nesse conjunto de dados (o padrão é todas), e a expressão que especifica o filtro que será aplicado ao conjunto de dados ativo. Nesse caso, o filtro é: age < 18.
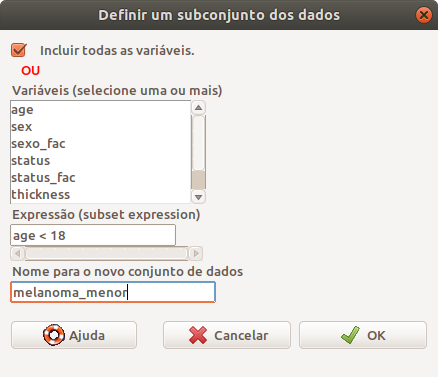
Figura 6.23: Caixa de diálogo para especificarmos um subconjunto de Melanoma composto pelos menores de 18 anos.
Ao pressionarmos OK, o comando abaixo é executado. A função subset() retorna um subconjunto do objeto especificado no primeiro argumento, de acordo com a expressão definida no argumento subset.
O conjunto de dados melanoma_menor possui somente 4 registros:
## time status age
## n15 469 1 14
## n29 858 1 16
## n74 1710 2 15
## n174 3385 2 4
## n186 3776 2 12Vamos ver um outro exemplo. Vamos voltar a fazer com que Melanoma seja o conjunto de dados ativo e vamos criar um outro subconjunto de Melanoma, excluindo os óbitos por outras causas. Novamente, utilizamos a seguinte opção:
\[\text{Dados} \Rightarrow \text{Conjunto de dados ativo} \Rightarrow \text{Definir subconjunto de dados ativo}\]
Na caixa de diálogo Definir um subconjunto dos dados (figura 6.24), damos um nome para o novo conjunto de dados (melanomaSemOutrosObitos), selecionamos todas as variáveis e a expressão que especifica o filtro que será aplicado ao conjunto de dados ativo (status != 3). Poderíamos também ter utilizado a expressão status_fac != "óbito por outras causas" para especificarmos o subconjunto de Melanoma.
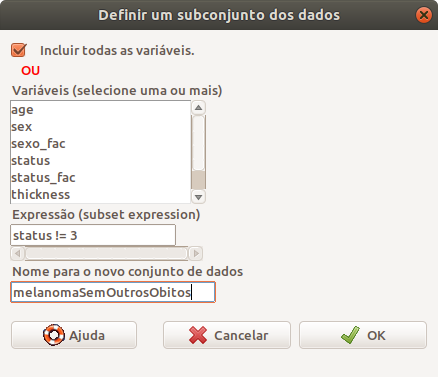
Figura 6.24: Caixa de diálogo para especificarmos um subconjunto do conjunto de dados Melanoma, excluindo os óbitos por outras causas.
Ao pressionarmos OK, o comando a seguir é executado.
6.2.7.1 Abandonar fatores não usados
Continuando com o conjunto de dados melanomaSemOutrosObitos da seção anterior, onde excluímos de Melanoma todos os registros cujo status fosse “óbito por outras causas”.
Se observarmos os níveis da variável status_fac, veremos que ela continua com três níveis, apesar de o nível óbito por outras causas não ser utilizado.
## [1] "óbito por melanoma" "vivo" "óbito por outras causas"Vamos fazer um diagrama de barras da variável status_fac por meio da opção:
\[\text{Gráficos} \Rightarrow \text{Diagrama de barras}\]
O gráfico resultante é mostrado na figura 6.25. Observamos que o nível correspondente a óbito por outras causas aparece, mesmo sabendo que não há nenhuma observação com esse nível no conjunto de dados.
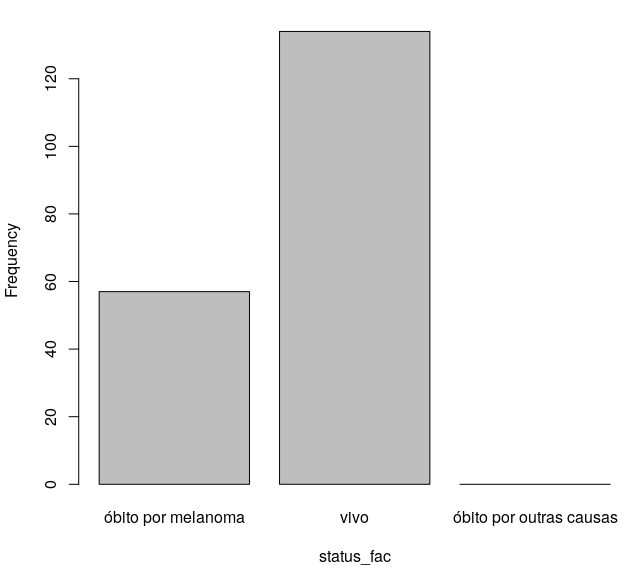
Figura 6.25: Diagrama de barras da variável status_fac do conjunto de dados melanomaSemOutrosObitos.
Para removermos os níveis não utilizados no R Commander, usamos a opção:
\[\text{Dados} \Rightarrow \text{Modificação variáveis no conj. de dados} \Rightarrow \text{Abandonar fatores não usados}\]
A caixa de diálogo Abandonar níveis dos fatores não utilizados (figura 6.26) nos permite selecionar as variáveis cujos níveis não utilizados serão abandonados. Podemos selecionar também todas as variáveis da classe factor.
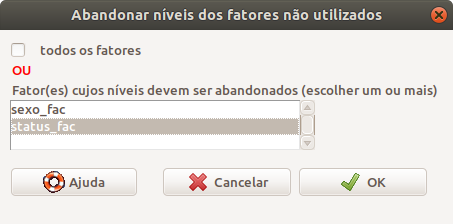
Figura 6.26: Caixa de diálogo para selecionar as variáveis cujos niveis não usados serão removidos.
Ao pressionarmos OK e, após uma confirmação, o comando abaixo será executado. A função droplevels() remove os níveis não usados.
melanomaSemOutrosObitos <- within(melanomaSemOutrosObitos, {
status_fac <- droplevels(status_fac)
})Ao verificarmos os níveis da variável status_fac, veremos que são listados somente os níveis utilizados.
## [1] "óbito por melanoma" "vivo"Se fizermos o gráfico de barras da variável status_fac novamente, vamos obter o gráfico mostrado na figura 6.27. Observamos que agora o nível correspondente a óbito por outras causas não aparece no gráfico.
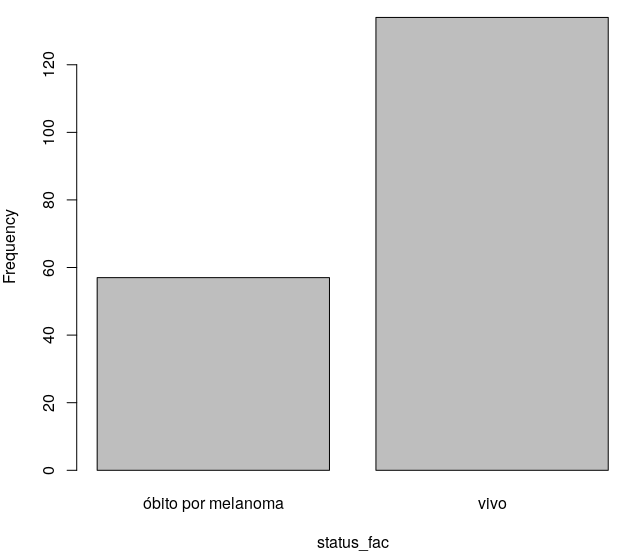
Figura 6.27: Diagrama de barras da variável status_fac do conjunto de dados melanomaSemOutrosObitos, após a remoção dos níveis não usados da variável status_fac.
6.2.8 Ordenar o conjunto de dados ativo
O conteúdo desta seção pode ser visualizado neste vídeo.
Vamos tornar o conjunto de dados Melanoma novamente o conjunto de dados ativo no R Commander.
Para ordenarmos o conjunto de dados ativo de acordo com os valores de uma ou mais variáveis, podemos usar a função order. No R Commander, utilizamos a seguinte opção:
\[\text{Dados} \Rightarrow \text{Conjunto de dados ativo} \Rightarrow \text{Sort active data set...}\]
Na caixa de diálogo Sort Active Data Set (figura 6.28), selecionamos as variáveis que definirão a ordenação, a direção da ordenação (crescente ou decrescente) e o nome do conjunto de dados que será criado. Nesse exemplo, vamos sobrescrever o conjunto de dados corrente.
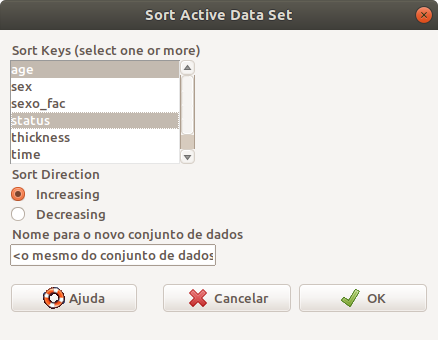
Figura 6.28: Caixa de diálogo para especificarmos como o conjunto de dados será ordenado.
Ao pressionarmos o botão OK, é necessário especificar a ordem de prioridade para a ordenação (figura 6.29). Nesse exemplo, o conjunto de dados será ordenado primeiramente de acordo com os valores da variável status. Depois todos os registros com o mesmo valor da variável status serão ordenados em ordem crescente de acordo com a idade.
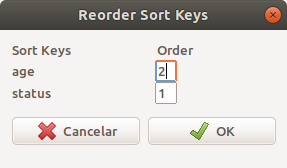
Figura 6.29: Caixa de diálogo para especificarmos a ordem de prioridade das variáveis que serão usadas para a ordenação.
Ao pressionarmos o botão OK, o comando a seguir é executado. Observem que as posições das linhas de Melanoma são alteradas de acordo com a ordem especificada.
Melanoma <- with(Melanoma, Melanoma[order(status, age, decreasing=FALSE), ])
head(Melanoma[, c("time", "status", "status_fac", "age")])## time status status_fac age
## n15 469 1 óbito por melanoma 14
## n29 858 1 óbito por melanoma 16
## n37 1062 1 óbito por melanoma 19
## n22 718 1 óbito por melanoma 25
## n45 1435 1 óbito por melanoma 27
## n6 204 1 óbito por melanoma 28Por meio do R Commander, temos que especificar a mesma direção de ordenação (crescente ou decrescente) para todas as variáveis. Por meio da linha de comando, podemos alterar o comando acima para ordenar o conjunto de dados em ordem crescente de status e decrescente de idade, fazendo o argumento decreasing ser igual a um vetor lógico onde cada elemento do vetor define se a ordenação da correspondente variável será decrescente ou não, conforme mostrado abaixo. Agora os registros estão ordenados em ordem crescente de status e os registros com mesmo valor de status estão ordenados em ordem decrescente de idade.
Melanoma <- with(Melanoma, Melanoma[order(status, age,
decreasing=c(FALSE, TRUE),
method="radix"), ])
head(Melanoma[, c("time", "status", "status_fac", "age")])## time status status_fac age
## n19 629 1 óbito por melanoma 95
## n21 667 1 óbito por melanoma 89
## n72 1690 1 óbito por melanoma 83
## n51 1516 1 óbito por melanoma 80
## n149 2782 1 óbito por melanoma 78
## n7 210 1 óbito por melanoma 776.2.9 Remoção de linhas do conjunto de dados ativo
Os conteúdos desta seção e da seção 6.2.10 podem ser visualizados neste vídeo.
Vamos supor que queiramos remover os registros 1 e 3 do conjunto de dados Melanoma. Para isso, selecionamos novamente o conjunto de dados Melanoma como o conjunto de dados ativo e selecionamos a opção abaixo no R Commander:
\[\text{Dados} \Rightarrow \text{Conjunto de dados ativo} \Rightarrow \text{Remova linha(s) do conjunto de dados ativo}\]
Na caixa de diálogo Remova linhas do subconjunto de dados ativo (figura 6.30), especificamos as linhas que serão removidas e damos um nome para o novo conjunto de dados que será gerado, ou podemos sobrescrever o conjunto de dados ativo.
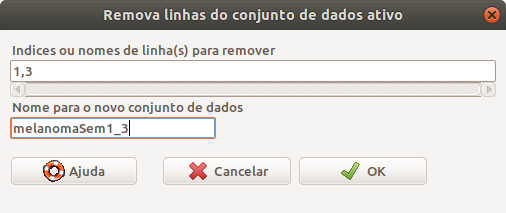
Figura 6.30: Caixa de diálogo para especificarmos as linhas que serão eliminadas do conjunto de dados.
Ao pressionarmos o botão OK, o comando abaixo é executado.
Observamos abaixo que as linhas 1 e 3 do conjunto de dados Melanoma (correspondentes aos nomes n19 e n72) não aparecem no conjunto de dados melanomaSem1_3.
## time status status_fac age
## n21 667 1 óbito por melanoma 89
## n51 1516 1 óbito por melanoma 80
## n149 2782 1 óbito por melanoma 78
## n7 210 1 óbito por melanoma 77
## n96 1933 1 óbito por melanoma 77
## n36 1055 1 óbito por melanoma 756.2.10 Remoção de observações com valores ausentes
Voltando ao conjunto de dados Melanoma, suponhamos que alteramos os valores das 4 primeiras variáveis do primeiro registro para NA e o valor da 6a variável no segundo registro para NA, conforme abaixo:
## time status sex age year thickness ulcer
## n19 NA NA NA NA 1968 5.48 1
## n21 667 1 0 89 1968 NA 1
## n72 1690 1 1 83 1971 1.62 0
## n51 1516 1 1 80 1968 2.58 1
## n149 2782 1 1 78 1969 1.94 0
## n7 210 1 1 77 1972 5.16 1Para removermos essas linhas que contêm pelo menos um valor de uma variável igual a NA, selecionamos a opção abaixo no R Commander:
\[\text{Dados} \Rightarrow \text{Conjunto de dados ativo} \Rightarrow \text{Remover observações com dados faltantes...}\]
A caixa de diálogo Remover Valores Faltantes (figura 6.31) permite a seleção das variáveis que serão armazenadas no novo data frame (melanoma_sem_missing).
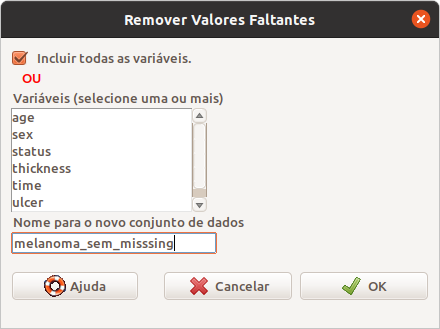
Figura 6.31: Caixa de diálogo para especificarmos o que será gravado após a remoção das observações com valores ausentes.
O comando executado é mostrado abaixo, onde a função na.omit() remove os registros com valores ausentes:
Vemos abaixo que os dois primeiros registros de Melanoma com valores faltantes foram removidos no conjunto de dados melanoma_sem_missing:
## time status sex age year thickness ulcer
## n72 1690 1 1 83 1971 1.62 0
## n51 1516 1 1 80 1968 2.58 1
## n149 2782 1 1 78 1969 1.94 0
## n7 210 1 1 77 1972 5.16 1
## n96 1933 1 0 77 1972 1.94 0
## n36 1055 1 0 75 1967 2.58 16.2.11 Variáveis agregadas do conjunto de dados ativo
Os conteúdos desta seção e da seção 6.2.12 podem ser visualizados neste vídeo.
A opção do R Commander abaixo permite a aplicação de funções de agregação de variáveis numéricas por categorias de uma ou mais variáveis categóricas.
\[\text{Dados} \Rightarrow \text{Conjunto de dados ativo} \Rightarrow \text{Variáveis agregadas ao conjunto de dados ativo...}\]
Para calcularmos a média das variáveis tempo de sobrevida (time) e espessura do tumor (thickness) para cada combinação dos níveis de status_fac e sexo_fac, por exemplo, completaríamos a caixa de diálogo Observações agregadas como mostra a figura 6.32.
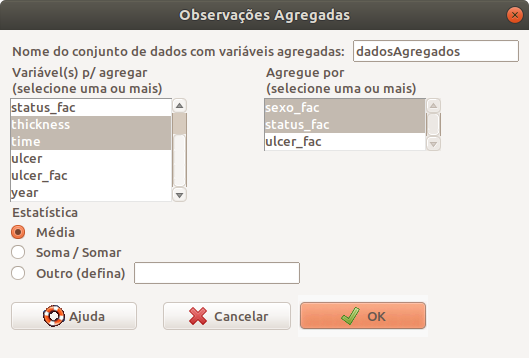
Figura 6.32: Caixa de diálogo para especificarmos como uma ou mais variáveis serão agregadas no conjunto de dados.
O comando executado é mostrado abaixo:
A função aggregate funciona da seguinte forma: a função definida pelo argumento FUN é aplicada às variáveis definidas pelo primeiro argumento da função antes do símbolo ~ para cada combinação de categorias das variáveis após o símbolo ~. As variáveis que definem as categorias são separadas pelo sinal +. O argumento data define o conjunto de dados que será utilizado. O resultado é um data frame, contendo as agregações e, nesse exemplo, é armazenado no objeto dadosAgregados.
Vejamos o data frame com as médias das variáveis time e thickness para cada combinação dos níveis de status_fac e sexo_fac:
## sexo_fac status_fac thickness time
## 1 feminino óbito por melanoma 3.620000 1408.667
## 2 masculino óbito por melanoma 4.595000 1146.000
## 3 feminino vivo 2.016374 2641.011
## 4 masculino vivo 2.727907 2577.628
## 5 feminino óbito por outras causas 2.601429 1225.714
## 6 masculino óbito por outras causas 4.834286 1450.8576.2.12 Empilhar variáveis no conjunto de dados ativo
A opção do R Commander abaixo permite a criação de um data frame com variáveis empilhadas uma abaixo da outra.
\[\text{Dados} \Rightarrow \text{Conjunto de dados ativo} \Rightarrow \text{"Stack variables" no conjunto de dados ativo}\]
A figura 6.33 mostra a caixa de diálogo para selecionar as variáveis a serem empilhadas. Nesse exemplo, foram selecionadas as variáveis age e sex. O data frame a ser criado será armazenado no objeto dadosEmpilhados com duas variáveis: valor e variavel.
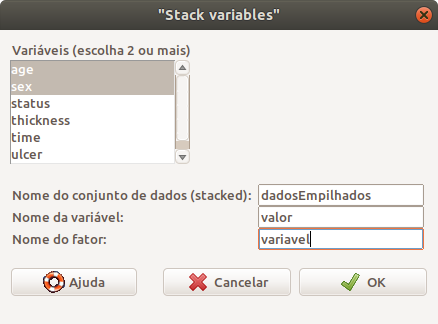
Figura 6.33: Tela para especificarmos as variáveis que serão empilhadas.
Ao pressionarmos o botão OK, os comandos abaixo serão executados:
dadosEmpilhados <- stack(Melanoma[, c("age","sex")])
names(dadosEmpilhados) <- c("valor", "variavel")A função stack realiza o empilhamento das variáveis definidas no primeiro argumento e cria um data frame. Se observarmos o conjunto de dados, verificaremos que o data frame contém o dobro de linhas de Melanoma, onde a primeira metade das linhas contém os valores de age na coluna valor e a palavra age na coluna variavel. As linhas restantes contém os valores da variável sex na coluna valor e a palavra sex na coluna variável.
6.2.13 Remodelar um conjunto de dados do formato longo para o formato largo
Os conteúdos desta seção e da seção 6.2.14 podem ser visualizados neste vídeo.
Vamos usar o conjunto de dados heart.rate, do pacote ISwR, que contém dados de frequência cardíaca (hr) de 9 pacientes com insuficiência cardíaca antes (time = 0) e em três instantes após a administração de enalaprilato (time = 30, 60 e 120 min). Nesse conjunto de dados (figura 6.34), uma variável, subj, identifica o indivíduo, e as variáveis hr e time indicam o valor da frequência cardíaca e o instante em que foi medida, respectivamente. Há, portanto, quatro valores de frequência cardíaca para cada indivíduo.
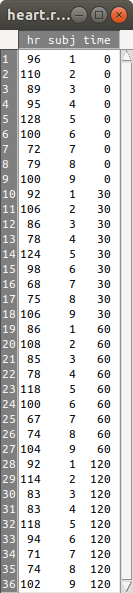
Figura 6.34: Conteúdo do conjunto de dados heart.rate.
Esse formato é chamado de longo, pois há um registro para cada valor de frequência cardíaca.
Uma outra forma de organizar esse conjunto de dados é mostrada na figura 6.35. Aqui há 5 variáveis, onde a variável subj identifica cada indivíduo e as variáveis hr0, hr30, hr60 e hr120 correspondem às frequências cardíacas de cada indivíduo nos instantes antes da administração e 30, 60 e 120 min após a administração do enalaprilato, respectivamente.
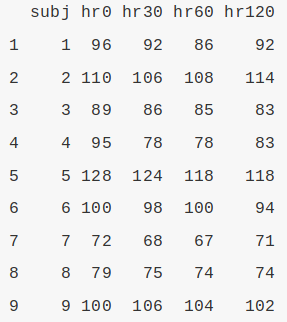
Figura 6.35: Conteúdo do conjunto de dados heart.rate no formato largo (wide).
Vamos chamar esse formato de formato largo – wide format. Nesse formato, há um registro para cada unidade de análise, ou paciente. Assim precisamos de 4 colunas, contendo as medidas de frequência cardíaca para cada indivíduo nos instantes 0, 20, 60 e 120 minutos.
Às vezes precisamos converter de um formato para o outro. Vamos ver como fazer isso no R Commander.
Vamos supor que o conjunto de dados heart.rate foi carregado e está como o conjunto de dados ativo no R Commander. Para convertermos o conjunto de dados heart.rate para o formato largo, usamos a seguinte opção:
\[\text{Dados} \Rightarrow \text{Conjunto dados ativo} \Rightarrow \text{Reshape dataset from long to wide format…}\]
Na tela de configuração da transformação do conjunto de dados (figura 6.36), damos um nome para o conjunto de dados que será gerado (heart.rateWide) e selecionamos a variável que identifica cada indivíduo (subj), a variável resposta (hr - variables that vary by occasion) e o fator (time - within subject factors).
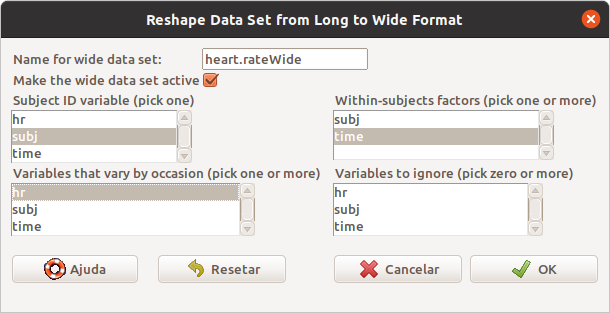
Figura 6.36: Tela para a seleção das variáveis que serão utilizadas para converter o formato longo de heart.rate para o formato largo.
Ao clicarmos em OK, o comando a seguir é executado e o conjunto de dados heart.rateWide será criado a partir de heart.rate, com quatro variáveis (X0, X30, X60, X120), representando as medidas de frequência cardíaca para cada indivíduo nos instantes 0, 20, 60 e 120 minutos, respectivamente.
Podemos, se for desejado, alterar os nomes das variáveis X0, X30, X60 e X120 por meio da seguinte opção no menu, como mostrado na seção 6.1.8:
\[\text{Dados} \Rightarrow \text{Modificação de variáveis no conjunto de dados} \Rightarrow \text{Renomear variáveis…}\]
Na tela da figura 6.37, selecionamos as variáveis que desejamos renomear. Ao clicarmos em OK, na tela seguinte (figura 6.38), damos os novos nomes das variáveis de heart.rateWide.
Figura 6.37: Seleção das variáveis do conjunto de dados heart.rateWide que serão renomeadas.
Figura 6.38: Especificação dos novos nomes das variáveis de heart.rateWide.
Ao clicarmos em OK, o comando a seguir é executado, atribuindo os novos nomes das variáveis de heart.rateWide.
6.2.14 Remodelar um conjunto de dados do formato largo para o formato longo
Agora, vamos fazer a conversão do formato largo para o formato longo, partindo do conjunto de dados heart.rateWide, gerado na seção anterior.
Para convertermos o conjunto de dados heart.rateWide para o formato longo, usamos a seguinte opção:
\[\text{Dados} \Rightarrow \text{Conjunto dados ativo} \Rightarrow \text{Reshape dataset from wide to long format…}\]
No conjunto de dados heart.rateWide, temos somente um fator que indica os diferentes instantes onde a frequência cardíaca foi medida. Assim vamos preencher os campos da aba One Repeated-Measures Factor na tela de configuração da transformação de heart.rateWide para o formato longo (figura 6.39). Vamos colocar o nome time para Name for the within-subjects factor. Teremos quatro níveis para essa variável, cada um indicando um instante de tempo em que a frequência cardíaca foi medida. A seguir, vamos selecionar hr0, hr30, hr60 e hr120 para os níveis 1 a 4 respectivamente.
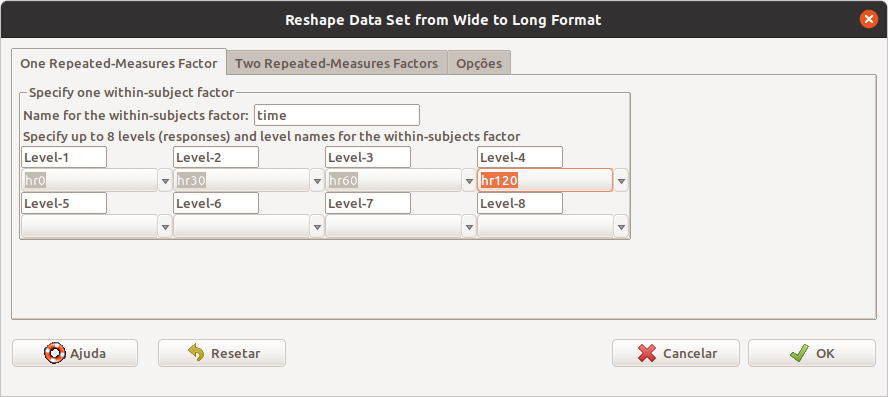
Figura 6.39: Tela para a seleção das variáveis que serão utilizadas para converter o formato largo de heart.rate (heart.rateWide) para o formato longo.
Na aba Opções da tela de configuração da transformação de heart.rateWide para o formato longo (figura 6.40), vamos dar o nome para o conjunto de dados que será criado (heart.rateLong), o nome da variável resposta, hr (heart rate) e o nome da variável que identifica cada indivíduo (subj). Também vamos tornar o conjunto de dados que será criado como conjunto de dados ativo.
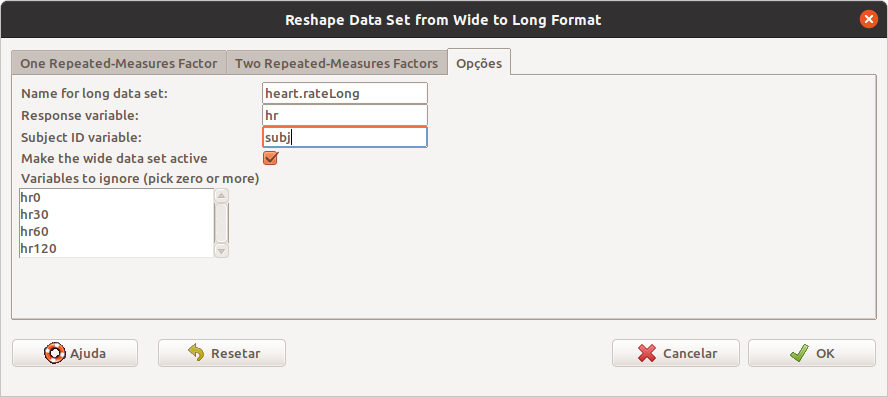
Figura 6.40: Aba Opções da configuração da transformação de heart.rateWide para o formato longo.
Ao clicarmos em OK, o comando a seguir será executado e o conjunto de dados heart.rateLong será criado.
heart.rateLong <- reshapeW2L(heart.rateWide, within="time",
levels=list(time=c("Level-1", "Level-2", "Level-3", "Level-4")),
varying=list(hr=c("hr0", "hr30", "hr60", "hr120")), id="subj")Se compararmos o conjunto de dados heart.rateLong com o conjunto de dados heart.rate original (figura 6.41), vemos que o instante 0 de heart.rate é indicado pelo valor Level-1 em heart.rateLong, o instante 30 é indicado pelo valor Level-2, o instante 60 por Level-3 e o instante 120 por Level-4. A ordem das linhas é diferente, mas há uma correspondência entre as medidas de frequência cardíaca de cada indivíduo em cada instante de tempo.

Figura 6.41: Conjunto de dados heart.rate e heart.rateLong lado a lado.
Podemos alterar os valores da variável time no conjunto heart.rateLong para ficarem iguais aos correspondentes valores da variável time em heart.rate, recodificando a variável time no conjunto de dados heart.rateLong. Para isso, utilizamos o seguinte item de menu (seção 6.1.1):
\[\text{Dados} \Rightarrow \text{Modificação de variáveis no conjunto de dados} \Rightarrow \text{Recodificar variáveis…}\]
Na tela para recodificação da variável (figura 6.42), vamos selecionar a variável time, vamos sobrescrever a variável, colocando o valor time para novo nome da variável, vamos manter a variável como fator e vamos especificar a recodificação como mostrada na figura.
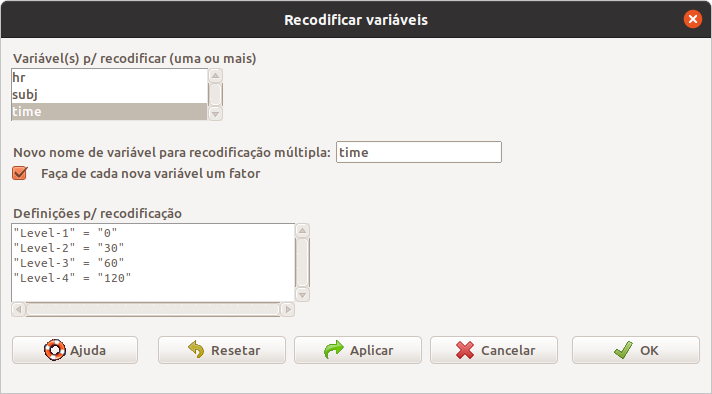
Figura 6.42: Renomeação das categorias da variável time por meio da função Recode.
Ao clicarmos em OK, o programa pergunta se desejamos sobrescrever a variável time. Vamos responder Sim. Agora os dois conjuntos de dados, heart.rate e heart.rateLong, são essencialmente idênticos.
6.2.15 Converter todas as variáveis do tipo character para o tipo factor
A opção do menu:
\[\text{Dados} \Rightarrow \text{Conjunto de dados ativo} \Rightarrow \text{Convert all character variables to factors}\]
utiliza a função strings2factors, do pacote car, para converter variáveis do conjunto de dados ativo do tipo character para fator. Na forma como ela é executada no R Commander, todas as variáveis do tipo character, com exceção daquelas cujos valores são únicos (ou seja, todos os valores da variável são diferentes uns dos outros), são convertidas para fatores. As variáveis do tipo character cujos valores são todos diferentes uns dos outros são tipicamente identificadores de casos e não são variáveis categóricas.
6.3 Exercício
Com o conjunto de dados VA do pacote MASS (GPL-2 | GPL-3), faça as seguintes atividades.
Verifique a ajuda para o conjunto de dados. Observe os códigos para as seguintes variáveis:
status: 0=censored; 1=dead
treat: 0=standard; 1=test
prior: 0=no;10=yes
cell: 1=squamous; 2=smallcell; 3=adeno; 4=large- Carregue o conjunto de dados.
- Liste os 10 primeiros registros do conjunto de dados.
- Verifique a classe das variáveis status, treat, cell e prior.
- Converta a variável status para fator, atribuindo nomes descritivos aos seus valores.
- Recodifique as variáveis cell, treat e prior, atribuindo nomes descritivos aos seus valores;
- Crie uma nova variável cujos valores sejam o logaritmo da variável stime. Use a função log.
- Crie uma variável que agrupe os valores de idade nas seguintes faixas: <31, [32-40], [41-60], >60.
- Padronize as variáveis age, diag.time e stime.
- Salve os dados em um arquivo do R.
- Verifique a classe da variável cell.
- Crie um subconjunto de VA com um nome apropriado que contenha somente os registros cujo valor de cell sejam dos tipos adeno ou large.
- Remova os níveis não usados da variável cell no subconjunto de dados criado.
Gere um relatório no R Markdown com as operações acima.