1 Introdução
1.1 O que é Estatística?
Uma definição comum em livros de Estatística considera a Estatística como a ciência que se preocupa com a organização, descrição, análise e interpretação dos dados experimentais (Costa Neto 1977). Pode-se acrescentar a essa definição o próprio planejamento de experimentos, já que o delineamento experimental influencia a análise e a interpretação dos resultados. Ao longo deste texto, cada um dos itens dessa definição serão esmiuçados.
1.2 Por que estudar Estatística?
Há diversos motivos por que os profissionais de saúde devam conhecer os princípios básicos de Estatística, alguns dos quais são citados abaixo:
- Planejamento de estudos. O conhecimento dos princípios básicos de Estatística é importante antes mesmo de um experimento ser realizado. Não é raro estudos serem realizados sem atenção aos princípios básicos de planejamento de experimentos e, ao final, os autores verificarem que o tamanho amostral ou o delineamento do experimento não foram adequados para responder às perguntas formuladas;
- Interpretação de estatísticas vitais e dados epidemiológicos;
- Interpretação de resultados de estudos publicados na literatura ou em outras fontes que visam a avaliar efeitos de tratamentos, qualidade de testes de diagnóstico e etiologia de doenças.
Embora a maior parte das análises estatísticas publicadas na literatura da área de saúde ainda sejam relativamente simples (por exemplo, teste t e teste qui-quadrado), tem havido um crescimento paulatino de análises mais complexas (regressão logística, modelos proporcionais de Cox, análises multivariadas) (Yi et al. 2015). Isso implica em uma maior necessidade de algum conhecimento de Estatística para aqueles que desejem compreender os estudos realizados na área de saúde. Por outro lado, muitos trabalhos têm avaliado a qualidade das análises estatísticas e da descrição dessas análises na área de saúde. Apesar de haver uma melhoria nesses aspectos, diversos problemas ainda são detectados em um bom número de publicações: tamanho amostral insuficiente, análises equivocadas, descrição deficiente dos métodos utilizados, conclusões não suportadas pelos dados, etc. (Altman 1998), (Parsons, Nick R et al. 2012), (Fernandes-Taylor et al. 2011). A situação é ainda mais alarmante em estudos que envolvem pesquisas com animais (Kikenny et al. 2009).
1.3 Dado, informação e conhecimento
Na prática clínica, obter dados, interpretá-los e relacioná-los são atividades centrais no processo de assistência à saúde. Shortliffe e Barnet (Shortliffe and Cimino 2014) conceituam dado clínico como toda a observação isolada de um paciente: temperatura axilar, hematócrito, história pregressa de sarampo, cor dos olhos, etc. Um dado pode ser caracterizado pelas seguintes propriedades: a entidade à qual ele se aplica; o que está sendo observado (parâmetro), o seu valor, o instante da observação e o método de observação. Assim, ao medirmos a temperatura axilar do paciente P por meio de um termômetro clínico, às 7:00 horas do dia 10 de agosto de 2014, e obtendo o valor de 38 Graus Celsius, teríamos uma observação (dado), com as seguintes propriedades:
Entidade – paciente P
Parâmetro – temperatura axilar
Valor – 38oC
Instante – 10/08/2014, às 7:00
Método – termômetro clínico
Van Bemmel e Musen (Bemmel and Musen 1997) definem dado como a representação de observações ou conceitos de modo adequado para a comunicação, a interpretação e o processamento por seres humanos ou máquinas. Esses mesmos autores definem informação como fatos úteis e com significados extraídos dos dados. Para um médico, o valor da temperatura acima (38oC) em um ser humano adulto indica que esse paciente está febril. O médico realizou uma interpretação desse dado; ele tem agora uma informação.
Assim a representação de um dado define uma forma ou sintaxe para o dado. O conteúdo ou semântica dessa representação define o significado ou interpretação do dado. A informação é o dado mais o seu significado (Bernstam, Smith, and Johnson 2010).
O conhecimento é composto de fatos e relacionamentos usados ou necessários para se obter um insight ou resolver problemas (Bemmel and Musen 1997), ou informação considerada verdadeira (Bernstam, Smith, and Johnson 2010). Pelo raciocínio indutivo, com os dados interpretados, coletados de muitos pacientes (ou por processos similares), novas informações são adicionadas ao corpo do conhecimento na medicina. Esse conhecimento é usado para a interpretação de outros dados. Por exemplo, voltando ao paciente em questão, a informação de que ele possui febre juntamente com outros fatos observados sobre o paciente e da associação desses fatos com determinadas doenças podem levar o médico a um diagnóstico para o paciente.
Podemos então considerar a informação como a interpretação de um dado dentro de um determinado contexto e o conhecimento a interpretação e/ou relacionamento de informações em um contexto mais amplo (Figura 1.1).

Figura 1.1: Relacionamento entre dado, informação e conhecimento.
Há diversas formas como os dados se apresentam nas diversas atividades humanas. Vamos apresentar abaixo alguns exemplos da área de saúde.
Narrativa
A narrativa é uma das principais formas de comunicação entre os seres humanos. Um exemplo de um trecho de um prontuário de um paciente é mostrado abaixo:
“9:00hs - apresenta-se consciente, comunicativo, ictérico, aceitou o desjejum oferecido, tomou banho de aspersão, deambulando, afebril, dispneico, normotenso, taquicárdico, mantendo venóclise por scalp em MSE, com bom fluxo, sem sinais flogísticos, abdômen ascítico, doloroso à palpação, SVD com débito de 200ml de coloração alaranjada, eliminação intestinal ausente há 1 dia. Refere algia generalizada.”
Embora seja extremamente útil para a comunicação entre os seres humanos, é muito difícil representar a narrativa de uma forma que possa ser processada pelos computadores, independentemente da intervenção humana. Essa é uma das áreas mais interessantes da inteligência artificial.
Medidas numéricas
Muitos dados utilizados no dia a dia são numéricos: peso, altura, idade, glicose. Esses dados são facilmente processados pelos computadores e analisados por métodos estatísticos.
Dados Categóricos
Dados categóricos são aqueles cujos valores são selecionados dentro de um conjunto limitado de categorias. Por exemplo, o tipo sanguíneo é um dado categórico com quatro níveis ou categorias (A, B, AB e O). Embora essas categorias possam ser codificadas numericamente, por exemplo, A - 1, B - 2, AB - 3, O - 4, elas não podem ser tratadas numericamente. Assim não há sentido em tirar uma média dos tipos sanguíneos de um grupo de pessoas, por exemplo.
Sinais biológicos
Diversos sinais podem ser obtidos a partir das atividades fisiológicas dos seres vivos: eletrocardiograma, eletroencefalograma, eletromiograma, etc. Esses sinais são utilizados para diversas finalidades, entre elas o estabelecimento de um diagnóstico. A figura 1.2 mostra um exemplo de um eletrocardiograma. Em geral esses sinais são representados por uma série temporal de dados numéricos onde, para cada instante, é registrada a intensidade do sinal.
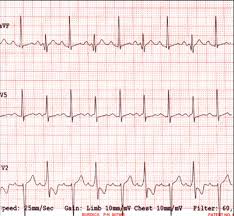
Figura 1.2: Exemplo de um sinal biológico – o eletrocardiograma.
Imagens
A utilização de imagens para fins de diagnóstico e acompanhamento da evolução de doenças tem avançado muito nas últimas décadas. Atualmente, imagens são geradas por diversos processos: Raios X, Tomografia Computadorizada, Ressonância Magnética Nuclear, Ultrassom, etc. A figura 1.3 mostra um exemplo de uma imagem de Raio X do pulmão. Para imagens monocromáticas, os dados de imagens são registrados por meio da sua localização e intensidade do nível de cinza. Para imagens coloridas, além da localização, são registrados valores relacionados às cores em cada local.
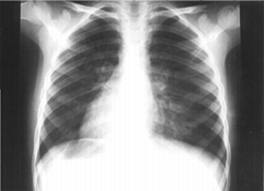
Figura 1.3: Exemplo de uma imagem de Raio X do pulmão.
Sequência genética
A bioinformática é, possivelmente, uma das áreas que mais tem avançado nos últimos anos. Cada gene é composto de uma sequência de elementos, onde cada elemento da sequência é um dos 4 nucleotídeos: Adenina - A, Guanina - G, Citosina - C e Timina - T. Uma possível sequência genética é mostrada abaixo:
CTGTGCGGCTCACACCTGGTGGAAGCTCTCTACCTAGTGTGCGGGGA
Para o processamento desses dados pelos computadores digitais, todos eles devem ser representados em uma forma que seja compreensível pelos computadores, utilizando o sistema binário.
Em Estatística, os dados são também chamados de variáveis. Para fins de análise estatística, é útil distinguir os tipos de variáveis mais utilizados e as operações que podem ser realizadas com cada tipo.
1.4 Variáveis em estudos clínicos
A figura 1.4 é a primeira página de um artigo publicado no British Medical Journal Open em 2013 (Rahman et al. 2013). Esse artigo não foi selecionado por alguma razão especial, mas apenas para dar um exemplo de um estudo clínico-epidemiológico. Nesses estudos, em geral, busca-se verificar, entre outras possibilidades, a associação entre variáveis relacionadas ao estado clínico e/ou tratamento aplicado a pacientes e algum desfecho clínico de interesse. Nesse exemplo, é verificada a associação entre duas doenças, osteoartrite e doença cardiovascular.
Não é objetivo deste texto o de discutir o estudo em si, mas sim mostrar os diversos tipos de variáveis que usualmente são coletadas em estudos clínico-epidemiológicos.
A figura 1.5 mostra a tabela 2 do estudo mostrado na figura 1.4, a qual apresenta diversas variáveis que foram medidas no estudo e as respectivas associações com o desfecho, que é a ocorrência ou não de doença cardiovascular. A medida de associação utilizada foi a razão de chances (“OR - Odds Ratio”).

Figura 1.4: Exemplo de um estudo clínico-epidemiológico. Fonte: (Rahman et al. 2013) (CC BY-NC).
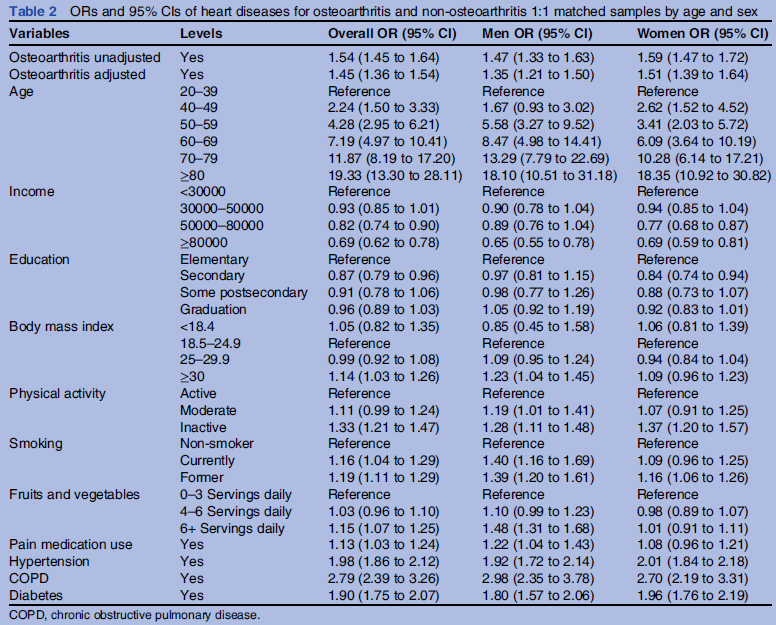
Figura 1.5: Tabela 2 do estudo da figura 1.4, com os valores das variáveis analisadas e a medida de associação entre cada variável e o desfecho clínico (doença cardiovascular).
Olhando atentamente a figura 1.5, vamos discutir os tipos e valores das variáveis que foram medidas Vamos começar pela variável idade (age). Pense um pouco sobre como vocês iriam medir a idade de uma pessoa para realizar algum estudo antes de continuar a leitura.
A idade pode ser medida de diversas formas. Pode-se, por exemplo, perguntar à pessoa ou a algum parente a sua idade. Outra possibilidade é a de registrar a data de nascimento e calcular a idade a partir dessa data. Finalmente podem-se criar faixas etárias e, para cada pessoa, registrar a faixa etária a que ela pertence. Essa última opção foi a utilizada para apresentar os valores da idade no estudo; foram utilizadas as seguintes faixas: 20-39, 40-49 e assim por diante.
A idade é uma variável numérica. Uma boa forma de coletá-la é por meio da data de nascimento. Assim nós podemos calculá-la a qualquer momento, com o grau de precisão que desejarmos. Depois, se for desejado, ela pode ser agrupada em qualquer configuração de faixas etárias que quisermos. Caso a idade tenha sido coletada em faixas etárias desde o início, não poderemos depois agrupá-la em outra configuração de faixas etárias e muito menos poderemos saber a idade de cada pessoa, apenas uma aproximação definida pelas faixas etárias criadas.
Observação importante: apesar de esse estudo apresentar os valores de idade agrupados por faixas etárias, isso não quer dizer que os autores coletaram os dados sobre idade dessa forma. Eles poderiam ter coletado o valor da idade (número de anos) e, para apresentar os valores de idade no estudo, preferiram agrupá-la em faixas etárias. O mesmo vale para outras variáveis apresentadas na tabela da figura 1.5, como índice de massa corporal, renda, etc.
Outra variável numérica avaliada no estudo é o índice de massa corporal - IMC - (Body mass index em inglês). Ela é calculada pela fórmula IMC = Peso/Altura2. Nesse caso, a melhor opção seria medir o peso e a altura da pessoa e, então, calcular o IMC pela fórmula. Depois, poderemos agrupá-la do jeito que quisermos.
O nível educacional (Education) é frequentemente registrado como uma variável categórica, onde os valores da variável são categorias previamente selecionadas. No Brasil, poderíamos usar, por exemplo, analfabeto, fundamental, nível médio, nível superior, etc.
As variáveis Diabetes, Hipertensão, DPOC - doença pulmonar obstrutiva crônica (COPD em inglês) - são binárias no estudo. O indivíduo é ou não diabético, é ou não hipertenso, etc. Essas variáveis poderiam ter sido coletadas de outras formas. Por exemplo, poder-se-ía ter registrado o tipo de diabetes e as medidas de pressão arterial sistólica e diastólica. Como as variáveis são medidas e analisadas em um estudo específico depende de diversos fatores: possibilidades de coleta, tipo de análise a ser realizada, custos, etc.
Verifiquem na figura 1.5 as outras variáveis apresentadas e pensem em outras formas em que elas poderiam ser registradas.
A seção seguinte apresenta como geralmente os dados de um estudo clínico-epidemiológico são organizados em arquivos.
1.5 Arquivos de dados
O conteúdo desta seção pode ser visualizado neste vídeo.
Em geral, ao ser realizada uma pesquisa clínica (figura 1.6), tem-se em mente um problema de saúde para o qual o estudo se propõe a investigar algum aspecto. Para isso, é preciso fazer um planejamento do estudo e, em geral, se estabelece um protocolo, detalhando como o estudo será realizado: qual o delineamento ou desenho do estudo, que variáveis serão medidas, o tempo de realização do estudo, as análises que serão realizadas, o número de pacientes que irão compor a amostra do estudo e outros aspectos do trabalho, etc.
Durante a realização do estudo, são definidos um ou mais instrumentos de coleta de dados, que se referem a uma amostra de pessoas que são selecionadas em uma determinada população por meio de um determinado processo de amostragem. Os dados coletados são organizados em estruturas conhecidas como arquivos de dados, conjuntos de dados ou bases de dados e, em seguida, são analisados por meio de pacotes estatísticos. Finalmente os resultados do estudo podem ser publicados em diversos meios: relatórios técnicos, artigos científicos, vídeos, páginas web, etc.
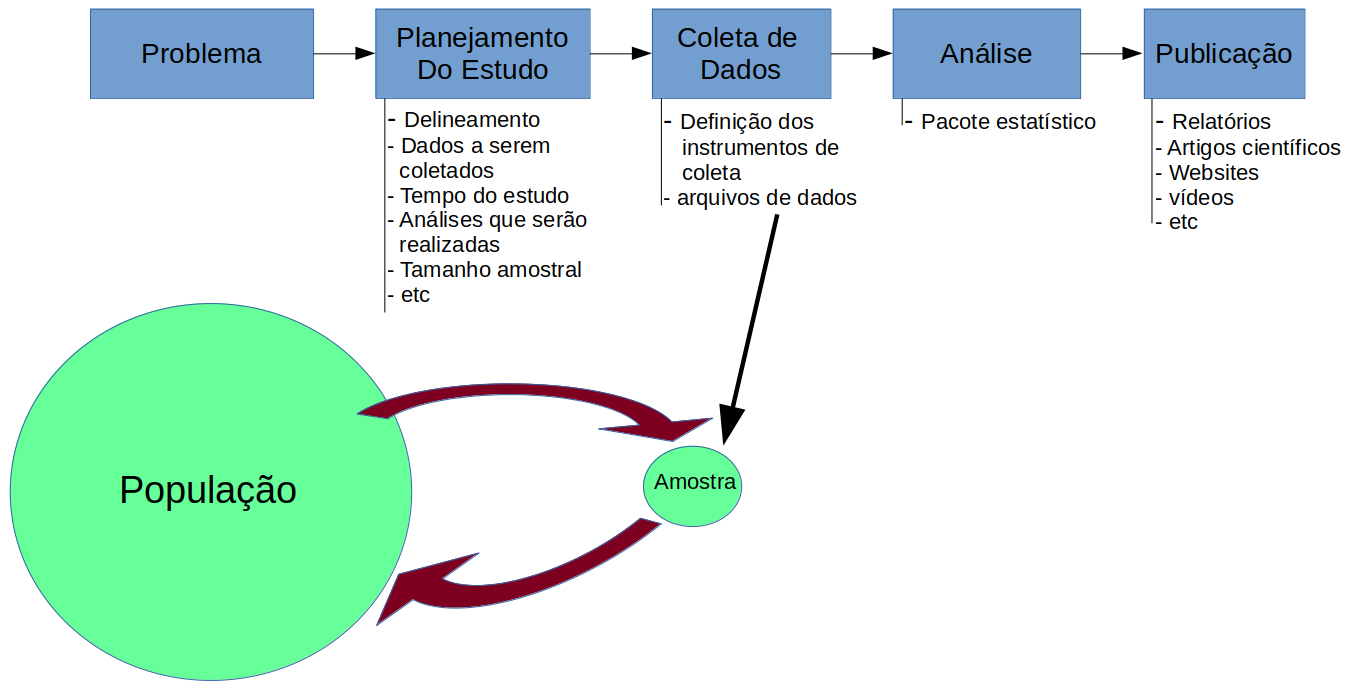
Figura 1.6: Fases de uma pesquisa clínica.
Definidas as variáveis que serão avaliadas no estudo, é preciso criar instrumentos de como essas variáveis serão coletadas para cada entidade participante do estudo. A figura 1.7 mostra uma declaração de nascido vivo. No Brasil, essa declaração é preenchida para todas as pessoas recém-nascidas. A declaração de nascido vivo contém uma série de variáveis que são coletadas por ocasião do nascimento da pessoa: data de nascimento, sexo, peso ao nascer, índice de Apgar, duração da gestação, etc. Esse é um exemplo de um formulário em papel.

Figura 1.7: Declaração de nascido vivo. Fonte: anexo A do manual de instruções para o preenchimento da declaração de nascido vivo (Ministério da Saúde 2011).
Os dados também podem ser coletados por meio eletrônico. A figura 1.8 mostra uma tela de um sistema de registro eletrônico de saúde, onde diversos dados relativos à condição clínica do paciente são coletados: queixa principal, doença atual, exames físicos e clínicos, hipóteses diagnósticas, etc.
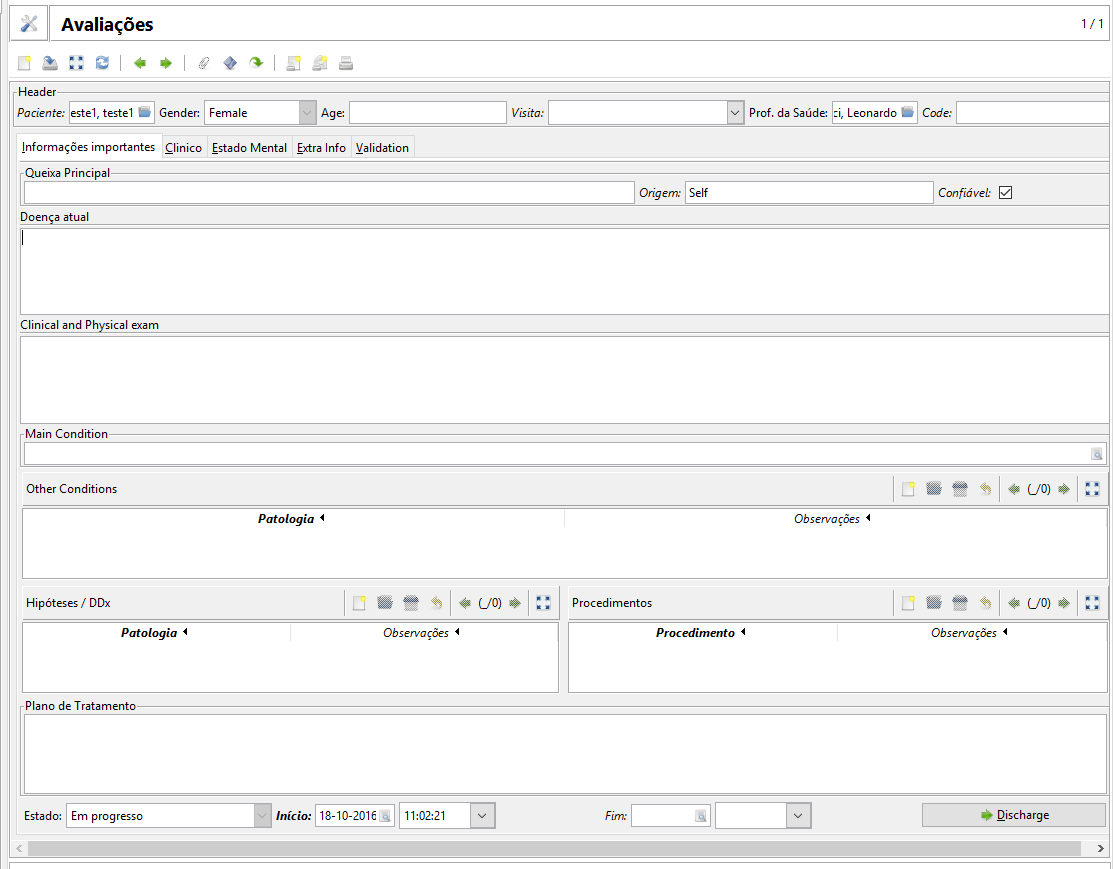
Figura 1.8: Interface do GnuHealth - Hospital Management Information System (GNU GPL).
Para fins de análise estatística, os dados coletados são organizados em estruturas denominadas arquivos de dados (figura 1.9). Diversos termos são utilizados para se referirem aos componentes de um arquivo de dados. A unidade de análise, ou unidade de observação, é a menor entidade a ser considerada em um estudo. Na grande maioria dos estudos clínico-epidemiológicos, a unidade de análise é uma pessoa, mas, em outros estudos, a unidade de análise pode ser a escola, uma área geográfica (município, bairro), um animal, etc., dependendo do escopo do trabalho. Para cada unidade de análise, são coletadas uma ou mais variáveis de interesse na investigação.
As variáveis coletadas para cada unidade de análise são armazenadas em um ou mais registros. O conjunto de todos os registros forma o arquivo de dados, ou conjunto de dados, ou base de dados .
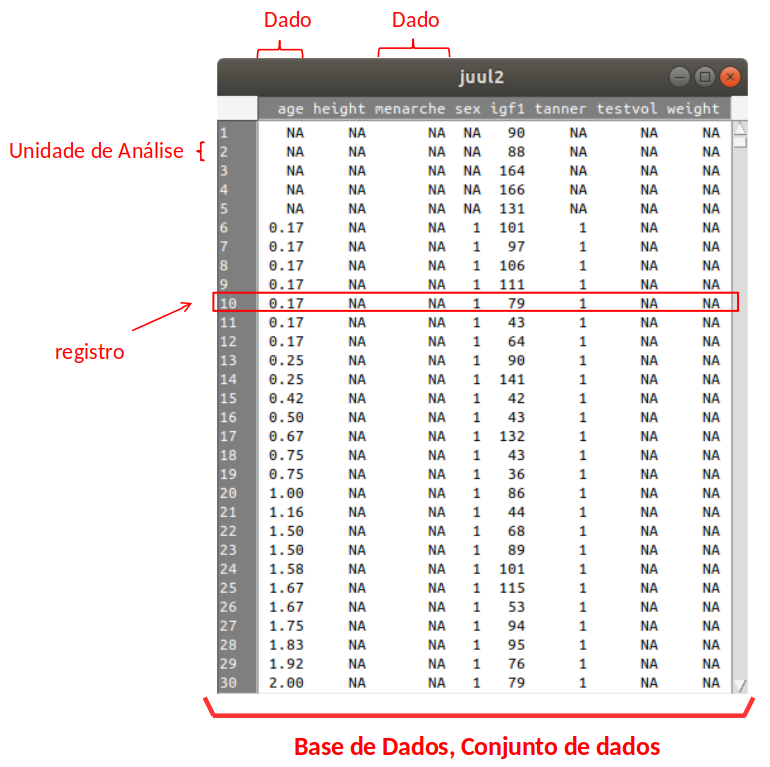
Figura 1.9: Arquivo de dados em estudos transversais. Fonte: conjunto de dados juul2 do pacote ISwR (GPL-2 | GPL-3).
Na figura 1.9, temos um exemplo de um estudo transversal que coletou dados de 1339 pessoas, principalmente pessoas em idade escolar, e as variáveis que foram coletadas são: idade (age) em anos, altura (height) em cm, menarca (menarche: se já ocorreu ou não, codificada como 1, correspondente a não; e 2, correspondente a sim), sexo (sex: 1 – menino, 2 – menina), igf1, que é o fator de crescimento parecido com a insulina, em ug/l, classificação de tanner (tanner), que se refere aos estágios da puberdade, classificados de I a V, volume testicular (testvol) em ml e peso (weight) em kg. A figura mostra o arquivo de dados com as 1339 observações, ou unidades de análises. Cada unidade de análise possui um registro ou linha nesse arquivo, porque as variáveis para cada unidade de análise foram medidas uma única vez, o que caracteriza o estudo como transversal. Cada variável é representada em uma coluna no arquivo e cada linha ou registro contém os valores de cada variável para a entidade correspondente.
O NA que aparece no arquivo significa não disponível (not available, em inglês), indicando que o valor da variável não foi coletado para a unidade de observação correspondente, ou não faz sentido em coletar aquela variável para a entidade a que ela se refere. Por exemplo a altura e idade não foram coletadas para os 5 primeiros indivíduos no arquivo da figura. Todos os valores de menarca para os meninos assumem o valor NA, já que não há sentido em verificar a ocorrência de menarca em meninos. Da mesma forma, a variável volume testicular assume o valor NA para as meninas.
Em estudos longitudinais, as variáveis são medidas em mais de um instante para cada unidade de análise. A figura 1.10 mostra duas formas de organizar os dados em um estudo longitudinal. Os dados nesse exemplo se referem a medidas da frequência cardíaca realizadas antes e após a administração de enalaprilato em 9 pacientes com insuficiência cardíaca congestiva. A frequência cardíaca foi medida nos instantes 0 (antes da administração do medicamento), 30, 60 e 120 min após o uso do medicamento.
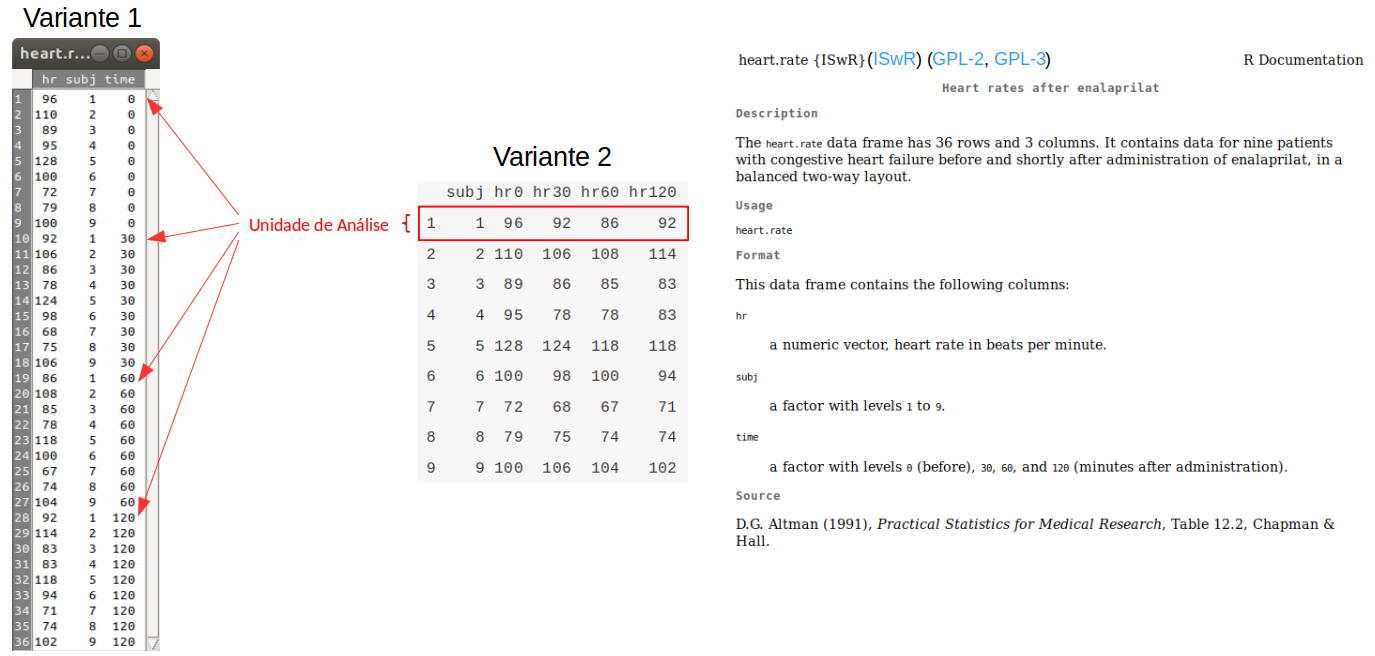
Figura 1.10: Duas formas de organização dos dados em estudos longitudinais. Fonte: conjunto de dados heart.rate, do pacote ISwR (GPL-2 | GPL-3).
No arquivo indicado pela variante 1, há uma única variável (hr) para registrar os valores da frequência cardíaca. Uma outra variável (time), indica o instante em que a frequência cardíaca foi medida e, finalmente, a variável subj identifica cada paciente do estudo. Assim, nesse arquivo, cada paciente possui 4 registros, um para cada instante em que a frequência cardíaca foi medida. Então, o arquivo contém um total de 36 registros, 4 registros por unidade de análise (ou pacientes).
No arquivo indicado pela variante 2, há 5 variáveis, onde a variável subj identifica cada indivíduo e as variáveis hr0, hr30, hr60 e hr120 correspondem às frequências cardíacas de cada indivíduo nos instantes 0, 30, 60 e 120 min após a administração do enalaprilato. Nesse arquivo, há um registro para cada unidade de análise, ou paciente.
Os arquivos podem ser armazenados em diversos formatos:
• Arquivos de pacotes estatísticos
- SPSS, Stata, R, SAS, Prisma, Statistica, etc.
• Planilhas eletrônicas
-Excel, Calc (Libre-office)
• Bancos de dados
- Oracle, PostgreSQL, MySQL, SQL-Server, Access, bancos XML, bancos NoSQL, etc.
Cada pacote estatístico geralmente possui um formato específico de armazenamento dos dados. Também podem ser utilizadas planilhas eletrônicas para coletar os dados, que podem ser exportados para serem analisados em algum pacote estatístico. Também é possível obter os dados a partir de bancos de dados que dão suporte a sistemas de prontuários eletrônicos ou a sistemas de gerenciamento da pesquisa clínica, por exemplo.
Neste livro, será utilizado o R, que é uma linguagem e um ambiente para a realização de análises estatísticas e construção de gráficos, altamente extensível. O R é disponível como software livre sob os termos da Licença Pública Geral GNU da Free Software Foundation.
O apêndice A apresenta o passo a passo para a instalação do R, de um programa que oferece um ambiente integrado de desenvolvimento baseado no R (R Studio), e de um pacote que fornece uma interface gráfica para a utilização do R (Rcmdr).
1.6 Escalas de medidas
O conteúdo desta seção, nos trechos relativos à classificação de variáveis, pode ser visualizado neste vídeo.
Existem diversos níveis de mensuração das variáveis. Esses níveis de mensuração são denominados escalas de medida. A escala na qual uma variável é medida tem implicações na forma como os dados são apresentados e resumidos e nas técnicas estatísticas utilizadas para analisá-los.
As escalas de medida são: escala nominal, escala ordinal, escala intervalar e escala de razão.
1.6.1 Escala nominal
Essa é a escala de medição mais simples. Nessa escala, os valores da variável são categorias mutuamente exclusivas e exaustivas. As categorias não possuem uma ordem.
Ex: religião, tipo sanguíneo, nacionalidade.
Variáveis medidas na escala nominal são denominadas variáveis categóricas nominais. Em geral essas variáveis são descritas por meio do percentual de cada um dos seus valores possíveis e visualizadas graficamente por meio de diagramas de barras ou diagramas de setores.
1.6.2 Escala ordinal
Nessa escala, os valores das variáveis são também categorias como nas variáveis nominais, mas essas categorias podem ser ordenadas de acordo com algum critério.
Ex: escolaridade (quando medida pelas categorias fundamental, médio e superior), estádio de câncer (0, I, II, III, IV).
A diferença entre duas categorias adjacentes não é a mesma ao longo da escala. Assim não se pode afirmar que a variação de gravidade do estádio de câncer I para o II é a mesma do estádio II para o III ou do III para o IV.
Variáveis medidas na escala ordinal são denominadas variáveis categóricas ordinais. Em geral essas variáveis são descritas por meio do percentual de cada um dos seus valores possíveis e visualizadas graficamente por meio de diagramas de barras ou diagramas de setores.
Quando o número de categorias é maior que 2, também utiliza-se o termo variáveis multicategóricas.
Observações:
Quando há somente duas categorias, a variável é chamada categórica binária ou categórica dicotômica.
Frequentemente, as variáveis dicotômicas utilizam as categorias Sim/Não ou 0/1. A designação 0/1 vem da forma como se codificam essas variáveis: em geral, ao indivíduo que apresenta a característica de interesse (Sim), atribui-se o valor 1, e para o que não a apresenta (Não), atribui-se o valor 0. Por exemplo, num estudo onde a variável fumante é dicotômica, em geral, os fumantes recebem o valor 1 (correspondente a Sim) e os não-fumantes recebem o valor 0 (correspondente a Não).
Muitas variáveis dicotômicas assumem dois valores, mas um não é a negação do outro. Nesses casos, outras codificações podem ser utilizadas, como atribuir arbitrariamente 1 e 2 a cada uma das duas categorias. Por exemplo, para a variável Sexo, pode-se atribuir o valor 1 para o sexo masculino e o valor 2 para o sexo feminino.
Variáveis multicategóricas podem ser transformadas em binárias, combinando-se as categorias. Por exemplo, considere a variável autopercepção de saúde do indivíduo, com cinco categorias ordenadas:
1 - excelente
2 - muito boa
3 - boa
4 - razoável
5 - ruim
Essa variável pode ser transformada para:
1 - ruim ou razoável
0 - bom, muito bom ou excelente.
O contrário é impossível: não se pode dividir em mais categorias uma variável que foi originalmente registrada como dicotômica.
- Algumas variáveis apresentam algumas categorias ordenadas e outras que não se encaixam em nenhuma ordenação. Por exemplo: na variável emprego, as categorias integral, parcial e desempregado podem ser ordenadas, mas onde posicionar a categoria aposentado?
1.6.3 Escala intervalar
A escala intervalar é uma escala numérica. A mesma diferença entre dois valores possui o mesmo significado ao longo da escala. Por exemplo, seja a variável idade de uma pessoa, medida em anos. Então, a diferença entre os valores de idade 18 e 20 (2) representa a mesma diferença, em termos de tempo decorrido, que entre as idades 60 e 62.
1.6.4 Escala de razão
A escala de razão é uma escala numérica que possui um zero absoluto. Para entender melhor o que isso significa, considere duas escalas muito utilizadas para medir a temperatura: escala Kelvin (K) e escala Celsius (C).
A relação entre essas duas medidas é dada pela fórmula:
K = C + 273,16
Consideremos as temperaturas
K1 = 20 K
K2 = 40 K
A razão entre K2 e K1 é 2, o que quer dizer que K2 representa um estado cuja agitação térmica é o dobro do estado designado por K1.
Entretanto, dadas as temperaturas
C1 = 20oC
C2 = 40o C
apesar de a razão entre C2 e C1 ser numericamente igual a 2, o estado designado por C2 não apresenta o dobro de agitação térmica que o estado designado por C1. Na escala Kelvin, teríamos:
C1 -> K1 = 293,16K
C2 -> K2 = 313,16K
K2/K1 = 1,07. O estado designado por C2 apresenta uma agitação térmica 1,07 vezes maior que a agitação térmica do estado designado por C1.
Por outro lado, a diferença entre as duas temperaturas em ambas as escalas (20K e 20o C) representam a mesma variação de agitação térmica entre os dois estados. Desse modo, dizemos que a escala Celsius é uma escala intervalar e a escala Kelvin é uma escala de razão.
As variáveis numéricas também podem ser classificadas como discretas ou contínuas. As variáveis contínuas podem assumir qualquer valor numérico dentro de um intervalo dado.
Ex: peso (kg), altura (m), glicemia de jejum (mg/dl), pH (adimensional).
As variáveis numéricas discretas são aquelas cujos valores pertencem a um conjunto enumerável, sendo esse frequentemente o conjunto dos números inteiros não negativos.
Ex: número de fraturas, número de extrassístoles, número de consultas médicas por ano, etc.
Em epidemiologia, os numeradores e denominadores que compõem os indicadores de saúde são frequentemente variáveis discretas (contagem de óbitos, contagem da população etc).
Algumas variáveis contínuas são discretizadas, sendo a principal delas o tempo. O tempo flui continuamente, mas a idade, por exemplo, é geralmente apresentada em anos completos, desprezando-se a fração de tempo além dos anos.
Observação: Como os instrumentos de medida possuem sempre algum limite de precisão, na prática, as variáveis contínuas não podem assumir um número infinito de valores em um intervalo. Por exemplo, em uma balança com precisão de 1 kg, uma medida de 62 kg na verdade expressa um valor entre 61,5 kg e 62,5 kg. Assim, rigorosamente falando, uma variável contínua pode, muitas vezes, ser tratada como discreta. Porém a ciência se baseia em modelos e, nos modelos estatísticos, tratamos variáveis cuja precisão depende do aparelho de medição como contínuas. Mesmo variáveis numéricas que são inerentemente discretas muitas vezes são tratadas como contínuas quando podem assumir um número grande de valores possíveis.
1.7 Transformação de variáveis
Como já vimos, as variáveis categóricas com mais de duas categorias podem ser transformadas em binárias. De maneira semelhante, variáveis numéricas podem ser recodificadas como categóricas ordinais ou mesmo binárias. Por exemplo, embora a glicemia de jejum seja uma variável contínua, ela pode ser transformada em uma variável binária: glicemia alta. Essa variável é obtida, dividindo-se os valores de glicemia por meio de um ponto de corte. A indivíduos com glicemia de jejum \(<\) 100 mg/dl poderia ser atribuído o valor 0, e para os com glicemia de jejum \({\ge}\) 100 mg/dl, o valor 1.
Variáveis com múltiplas categorias também podem ser criadas dessa forma. Por exemplo, um investigador pode preferir utilizar a seguinte escala para classificar a pressão arterial: baixa/normal/alta. Nesse caso, ele precisaria criar dois pontos de corte.
O que não é possível é desagregar uma variável originalmente registrada num formato mais agregado. O gradiente de agregação de variáveis é:
\[\text{Continua} \Rightarrow\ \text{Discreta} \Rightarrow\ \text{Multicategórica} \Rightarrow\ \text{Binária}\]
A figura 1.11 resume a classificação de variáveis para finalidades estatísticas.
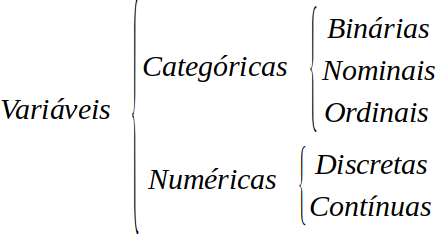
Figura 1.11: Resumo dos tipos de variáveis.
Um grupo especial de variáveis que é muito comum na área de saúde são as escalas ou índices.
1.8 Escalas e índices
O conteúdo desta seção pode ser visualizado neste vídeo.
Índices e escalas são dispositivos de redução de dados, onde as várias respostas de um respondente podem ser resumidas num único escore. Não se deve confundir o conceito de escalas utilizado nesta seção com o conceito de escalas de medidas, apresentado na seção 1.6.
Existem inúmeras escalas propostas nas diversas áreas da saúde. Alguns exemplos de escalas são listados abaixo:
• Geboes Score
• Apache II
• Charlson Comorbidity Index
• Short Form Health Survey (SF-36)
• TIMI
• Nutritional Risk Screening
Uma das escalas mais simples é a escala de Apgar. Essa escala foi proposta por Virgínia Apgar, uma médica estadounidense e é calculada como mostra a figura 1.12.
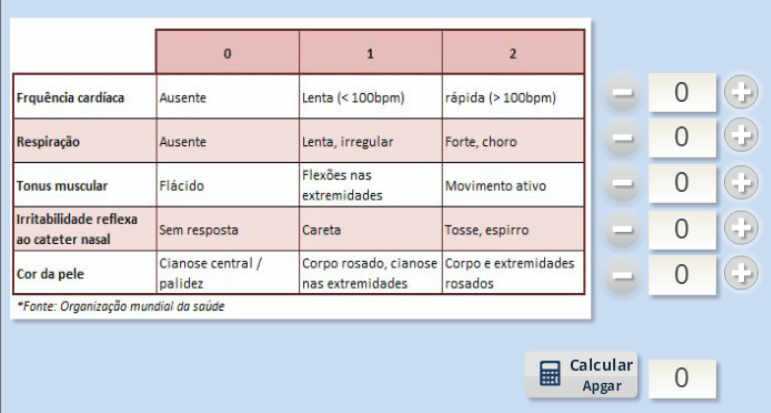
Figura 1.12: Componentes da escala de Apgar.
Uma criança recém-nascida é avaliada em 5 itens (frequência cardíaca, respiração, tônus muscular, irritabilidade reflexa ao cateter nasal e cor da pele) e recebe uma pontuação de 0 a 2 para cada dimensão de acordo com os critérios mostrados no quadro da figura 1.12. Assim, se a frequência cardíaca estiver ausente, a criança recebe 0 nesse quesito. Se a frequência cardíaca estiver lenta (abaixo de 100 bpm), a criança recebe 1. Se a frequência cardíaca estiver rápida (acima de 100 bpm), a criança recebe 2. Atribuindo a pontuação correspondente para os outros 4 itens e somando-se todos os pontos obtemos o escore de Apgar. Portanto o escore de Apgar é um número inteiro de 0 a 10.
O teste é geralmente realizado no primeiro e quinto minutos após o nascimento (chamados de Apgar de 1 minuto e Apgar de 5 minutos, respectivamente) e é repetido posteriormente se o índice permanecer baixo.
Observando como o valor de Apgar é obtido, podemos considerá-lo como uma variável numérica, medida na escala intervalar, ou os números refletem mais o grau de saúde da criança, sem necessariamente quantificá-la? Por exemplo, se o Apgar fosse uma variável numérica que refletisse o quanto a criança é saudável, então a diferença entre os valores de Apgar 5 e 6, por exemplo, deveria refletir a mesma variação no nível de saúde que a diferença entre os valores de Apgar 9 e 10, ou seja, a diferença de 1 unidade entre dois valores de Apgar deveria significar a mesma variação na quantidade de saúde ao longo de toda a escala de Apgar. Assim, possivelmente, seria mais conveniente considerar a escala de Apgar como uma variável categórica ordinal. Entretanto, há trabalhos publicados na literatura que tratam o Apgar como uma variável numérica discreta. Essa mesma observação possivelmente pode ser aplicada a um bom número das escalas que são propostas na área de saúde.
Há escalas mais complexas do que a escala de Apgar. Uma escala frequentemente utilizada para avaliar a qualidade de vida de pacientes é a escala conhecida como SF36, Medical Outcomes Short-Form Health Survey. Essa escala é composta de 36 perguntas (itens) que abordam os domínios:
- capacidade funcional (10 itens)
- aspectos físicos (4 itens)
- dor (2 itens)
- estado geral da saúde (5 itens)
- vitalidade (4 itens)
- aspectos sociais (2 itens)
- aspectos emocionais (3 itens)
- saúde mental (5 itens)
- um item que compara as condições de saúde atual e a de um ano atrás.
O arquivo SF-36 (CC BY) mostra o questionário e como o escore é calculado para cada domínio.
No início, o arquivo mostra como pontuar a resposta a cada questão. Há um total de 11 questões, sendo que algumas questões possuem mais de uma pergunta, totalizando 36 perguntas. Assim, por exemplo, a questão 1 do questionário é mostrada abaixo:
- Em geral você diria que sua saúde é (circule uma):
Excelente - 1
Muito boa - 2
Boa - 3
Ruim - 4
Muito ruim - 5
Cada resposta da pergunta 1 recebe uma pontuação de acordo com a lista abaixo:
1 - 5,0
2 - 4,4
3 - 3,4
4 - 2,0
5 - 1,0
Em seguida, o arquivo mostra como calcular os escores para cada domínio e as questões que estão relacionadas a cada um dos oito domínios (figura 1.13).
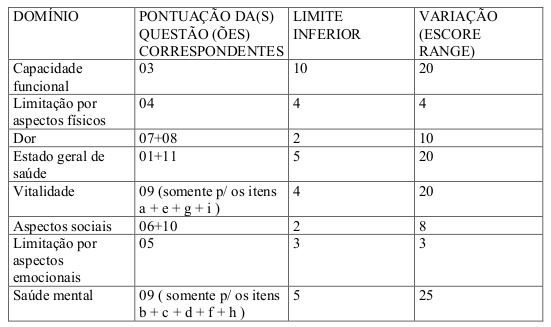
Figura 1.13: Quadro que mostra como calcular os escores para cada domínio do SF36.
No quadro da figura 1.13, a fórmula para o cálculo do escore para cada domínio é dada por:
\(Domínio: \frac{(Valor\ obtido\ nas\ questões\ correspondentes - limite\ inferior).100}{Variação\ (Score\ Range)}\)
Na fórmula acima, os valores de limite inferior e variação são fixos e especificados no quadro da figura 1.13.
Dois escores (resumo do componente físico e resumo do componente mental) podem também ser derivados do SF-36.
Finalmente o arquivo mostra o questionário com as 11 questões.
Os domínios do SF36 são frequentemente tratados como variáveis numéricas em trabalhos científicos, mas questões semelhantes às levantadas para o Apgar quanto à validade de se tratar os domínios do SF36 como variáveis numéricas podem ser levantadas.
1.9 Identificação de variáveis em estudos clínicos
Ao realizar a leitura de um estudo clínico-epidemiológico, é importante identificar as variáveis que foram analisadas e os respectivos tipos. As variáveis podem estar identificadas no próprio texto do trabalho, ou podem aparecer nos resultados gráficos ou em tabelas. Vejam a figura 1.14. A elipse em vermelho destaca as variáveis que aparecem na tabela. O retângulo em amarelo destaca os valores que cada variável à esquerda pode assumir. Assim a variável idade pode assumir os seguintes valores: 20-39, 40-49, 50-59, 60-69, 70-79, \(\ge\) 80. A idade, nesse estudo, é apresentada como uma variável categórica ordinal.
Há uma outra variável não explicitamente identificada na tabela mostrada na figura 1.14. Observe a elipse em verde, onde existe uma coluna que fornece os valores da razão de chances (OR – Odds Ratio em inglês) para homens e uma outra para as mulheres. Então temos mais uma variável, gênero, que foi considerada no estudo.
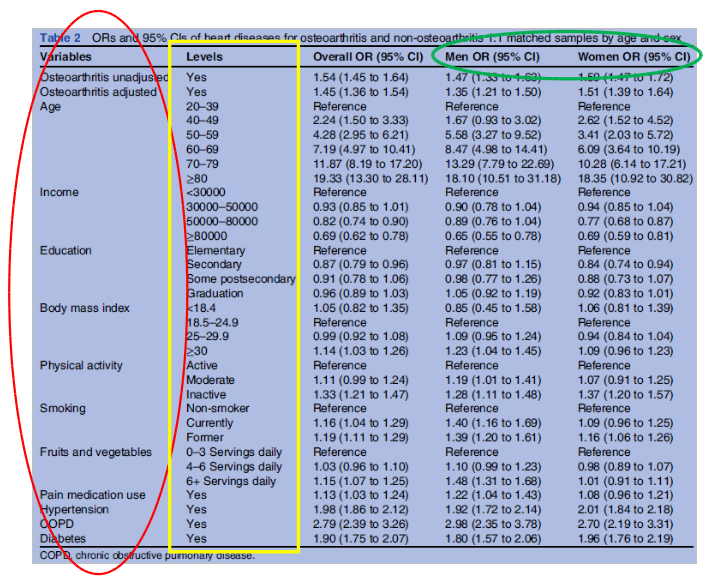
Figura 1.14: Tabela 2 do estudo de Rahman et al (Rahman et al. 2013) (CC BY-NC), com os valores das variáveis analisadas e a medida de associação entre cada variável e o desfecho clínico (doença cardiovascular).
A tabela 1.1 mostra a classificação das variáveis da figura 1.14.
| Variável | Classificação |
|---|---|
| osteoartrite | Categórica Binária |
| Idade | Categórica Ordinal |
| Renda | Categórica Ordinal |
| Educação | Categórica Ordinal |
| Índice de Massa Corporal | Categórica Ordinal |
| Atividade Física | Categórica Ordinal |
| Tabagismo | Categórica Ordinal |
| Frutas e Verduras | Categórica Ordinal |
| Uso de Medicação | Categórica Binária |
| Hipertensão | Categórica Binária |
| Diabetes | Categórica Binária |
| DPOC | Categórica Binária |
| Gênero | Categórica Binária |
1.10 Exercício
- Classifique as variáveis presentes nas tabelas do artigo intitulado “Fatores associados à qualidade de vida sob a perspectiva da terapia medicamentosa em pacientes com asma grave” (Souza, Noblat, and Santos 2015) (CC BY-NC).