8 Medidas de associação
8.1 Introdução
Neste capítulo, serão apresentadas algumas das principais medidas de associação para variáveis categóricas utilizadas em estudos clínico-epidemiológicos: diferença de riscos, número necessário para tratar, risco relativo, diferença relativa de riscos e razão de chances. Seguindo outros capítulos, será mostrado como obter essas medidas a partir de conjuntos de dados no R.
8.2 Medidas de associação
O conteúdo desta seção pode ser visualizado neste vídeo.
As medidas de associação entre duas variáveis serão apresentadas para o caso de duas variáveis categóricas dicotômicas. Uma maneira bastante útil de obter essas medidas é apresentar os resultados na forma de uma tabela 2x2 (tabela 8.1). Vamos supor que uma variável de exposição possua duas categorias (Nível 1 e Nível 2) e a variável de desfecho clínico possua as categorias Sim e Não, que indicam se o desfecho avaliado ocorreu ou não. Por exemplo, no estudo de Brindle et al. (Brindle et al. 2017), Adjunctive clindamycin for cellulitis: a clinical trial comparing flucloxacillin with or without clindamycin for the treatment of limb cellulitis, a variável de exposição seria, por exemplo, tratamento para celulite dos membros, com duas categorias: flucloxacilina com clindamicina e flucloxacilina sem clindamicina. Uma variável de desfecho do estudo é a melhoria no quinto dia, com as categorias: Sim e Não.
| Exposição | Sim | Não | Total |
|---|---|---|---|
| Nível 1 | \(\textit{a}\) | \(\textit{b}\) | \(\textit{a+b}\) |
| Nível 2 | \(\textit{c}\) | \(\textit{d}\) | \(\textit{c+d}\) |
| Total | \(\textit{a+c}\) | \(\textit{b+d}\) | \(\textit{a+b+c+d}\) |
Interpretando a tabela 8.1 como o resultado de um estudo de coortes, transversal ou ensaio clínico randomizado (ECR), \(\textit{a}\) representa o número de indivíduos expostos ao nível 1 e que tiveram o desfecho clínico de interesse, \(\textit{b}\) representa o número de indivíduos expostos ao nível 1 e que não tiveram o desfecho clínico de interesse, \(\textit{c}\) representa o número de indivíduos expostos ao nível 2 e que tiveram o desfecho clínico de interesse e \(\textit{d}\) representa o número de indivíduos expostos ao nível 2 e que não tiveram o desfecho clínico de interesse.
O risco absoluto de ocorrência de um evento quando um indivíduo está exposto a um determinado nível de exposição é expresso pela razão entre o número de indivíduos expostos ao nível de exposição nos quais o evento ocorreu e o número total de indivíduos expostos ao correspondente nível de exposição.
Assim, na tabela 8.1, o risco de um indivíduo apresentar o desfecho clínico de interesse quando o indivíduo está exposto ao nível 1 do fator de exposição é dado por:
\[\begin{equation} R_{N1} = \frac{a}{a+b} \tag{8.1} \end{equation}\]
onde RN1 significa o risco devido à exposição ao nível 1 do fator de exposição. Conforme visto no capítulo anterior, esse risco é uma estimativa da probabilidade de ocorrência do desfecho clínico condicionado à exposição do indivíduo ao nível 1 do fator de exposição.
Analogamente, o risco de um indivíduo apresentar o desfecho clínico de interesse quando o indivíduo está exposto ao nível 2 do fator de exposição é dado por:
\[\begin{equation} R_{N2} = \frac{c}{c+d} \tag{8.2} \end{equation}\]
Onde RN2 significa o risco devido à exposição ao nível 2 do fator de exposição. Analogamente, esse risco é uma estimativa da probabilidade de ocorrência do desfecho clínico condicionado à exposição do indivíduo ao nível 2 do fator de exposição.
Vamos considerar os resultados apresentados pelo estudo de Hjerkind, Stenehjem e Nilsen (Hjerkind, Stenehjem, and Nilsen 2017), que avaliaram a associação entre a adiposidade e a atividade física com o diabetes mellitus.
| Atividade Física | Sim | Não | Total |
|---|---|---|---|
| Exercita 4+ vezes/semana | 45 | 1836 | 1881 |
| Inativo | 73 | 1875 | 1948 |
| Total | 118 | 3711 |
A tabela 8.2 é uma versão simplificada da tabela 3 do referido estudo, considerando somente a relação entre a atividade física e a ocorrência de diabetes mellitus entre os homens. Levando em conta somente dois níveis de atividade física (inatividade e exercita 4 ou mais vezes/semana), os riscos seriam expressos como:
\[\begin{equation} R_{inativo} = \frac{73}{1948}=0,037=3,7\% \end{equation}\]
\[\begin{equation} R_{exercita 4+ vezes/semana } = \frac{45}{1881}=0,024=2,4\% \end{equation}\]
De cada 100 homens inativos, 3,7 em média irão desenvolver diabetes mellitus. De cada 100 homens que se exercitam 4 ou mais vezes por semana, em média, 2,4 irão desenvolver diabetes mellitus. Esse resultado deve ser visto com cautela, já que não leva em conta outros fatores que poderiam afetar o desfecho clínico em estudo.
A tabela 8.3 é uma versão simplificada da tabela 3 do estudo de Hjerkind, Stenehjem e Nilsen, considerando somente a relação entre a adiposidade, expressa pelo índice de massa corporal (IMC) e a ocorrência de diabetes mellitus entre os homens.
| \(\boldsymbol{IMC (kg/m^2)}\) | Sim | Não | Total |
|---|---|---|---|
| ≥ 30 | 156 | 1228 | 1384 |
| 14,5 – 24,9 | 95 | 10893 | 10988 |
| Total | 251 | 12121 |
Levando em conta somente dois níveis do IMC (14,5 < IMC < 25 kg/m2 e IMC \(\ge\) 30 kg/m2), os riscos seriam expressos como:
\[\begin{equation} R_{14,5<IMC<25} = \frac{95}{10988}=0,0086=0,86\% \end{equation}\]
\[\begin{equation} R_{IMC \ge 30} = \frac{156}{1384}=0,11=11\% \end{equation}\]
Uma vez estimados os riscos associados a cada nível de uma variável de exposição, vamos definir e exemplificar algumas das principais medidas de associação utilizadas em epidemiologia clínica.
8.2.1 Diferença absoluta de riscos (DAR)
Os conteúdos desta seção e da seção 8.2.2 podem ser visualizados neste vídeo.
A Diferença Absoluta de Riscos para uma variável de exposição é expressa pela diferença entre os riscos absolutos associados aos respectivos níveis da variável de exposição considerada, tomando um dos níveis como referência. Assim sendo, na tabela 8.1, a DAR para a variável de exposição, tomando o nível 2 como referência, é dada por:
\[\begin{equation} DAR = R_{N1}- R_{N2} \tag{8.3} \end{equation}\]
No exemplo da tabela 8.2, para a atividade física, tomando a inatividade como referência, a DAR é dada por:
\[\begin{equation} DAR = R_{exercita4+ }- R_{inativo }= 0,024 - 0,037 = -0,013 = -1,3\% \end{equation}\]
Nesse exemplo, o fato de se exercitar com frequência maior ou igual a 4 vezes por semana reduz o risco de diabetes mellitus em 1,3% em comparação com a inatividade, desconsiderando a influência de outros fatores sobre o diabetes. Nesse caso, a atividade física seria considerada um fator de proteção em relação ao diabetes mellitus. Assim seria preciso 100 homens passarem a se exercitar 4 ou mais vezes por semana para, em média, termos uma redução de 1,3 homens que desenvolverão a doença.
No exemplo da tabela 8.3, tomando o IMC como fator de exposição e o nível do IMC entre 14,5 e 25 kg/m2 como referência, a DAR, é dada por:
\[\begin{equation} DAR = R_{IMC \ge 30 } - R_{14,5<IMC<25 }= 0,11 - 0,0086 = 0,1014 = 10,14\% \end{equation}\]
Nesse exemplo, um IMC \(\ge\) 30 kg/m2 aumenta em 10,14% o risco de diabetes mellitus em comparação com o IMC na faixa entre 14,5 e 25 kg/m2, desconsiderando a influência de outros fatores sobre o diabetes. Nesse caso, adiposidade é considerada um fator de risco em relação ao diabetes mellitus.
8.2.2 Número necessário para tratar
O Número Necessário para Tratar (NNT) é o inverso do módulo (desconsiderando o sinal) da diferença absoluta de riscos.
No exemplo da tabela 8.2, o seu valor seria:
\[\begin{equation} NNT = \frac{1}{0,013}=76,9 \end{equation}\]
Vimos no item anterior que seria preciso 100 homens passarem a se exercitar 4 ou mais vezes por semana para, em média, se ter uma redução de 1,3 homens que desenvolverão a doença. O NNT pode ser obtido a partir do número de homens que deveriam se exercitar 4 ou mais vezes por semana para evitar 1 caso de diabetes mellitus. Usando uma regra de três:
100 ― 1,3
NNT ― 1
\[\begin{equation} NNT = \frac{1\ .\ 100}{1,3}=76,9 \end{equation}\]
Assim, nesse exemplo, o NNT pode ser interpretado como o número de homens que precisariam passar a realizar a atividade de prevenção (exercitar 4 ou mais vezes por semana) para que tenhamos um caso a menos da doença.
No exemplo da tabela 8.3, como um IMC \(\ge\) 30 kg/m2 aumenta o risco de ocorrência de diabetes mellitus, essa medida seria mais convenientemente chamada de Número Necessário para Causar Dano (NNH - Number Needed to Harm, em inglês). O seu valor seria:
\[\begin{equation} NNH= \frac{1}{0,1014}=9,9 \tag{8.4} \end{equation}\]
Ou seja, seria preciso 9,9 homens terem um IMC \(\ge\) 30 kg/m2, para ocorrer um caso a mais de diabetes mellitus do que se esses homens tivessem o IMC na faixa entre 14,5 e 25 kg/m2.
Assim a interpretação do NNT depende se o fator estudado é um fator de proteção ou de risco.
8.2.3 Risco relativo
Os conteúdos desta seção e das seções 8.2.4 e 8.2.5 podem ser visualizados neste vídeo.
O Risco Relativo (RR) de ocorrência de um evento devido a uma fator de exposição é expresso pela razão entre os riscos absolutos associados aos respectivos níveis da variável de exposição considerada, tomando um dos níveis como referência. Assim sendo, na tabela 8.1, o RR para a variável de exposição, tomando o nível 2 como referência, é dado por:
\[\begin{equation} RR = \frac{R_{N1}}{R_{N2}} \tag{8.5} \end{equation}\]
No exemplo da tabela 8.2, o RR de ocorrência de diabetes para a atividade física entre os homens, tomando a inatividade como referência, é dada por:
\[\begin{equation} RR = \frac{R_{exercita4+}}{R_{inativo}}= \frac{\frac{45}{1881}}{\frac{73}{1948}}=0,638 \end{equation}\]
Nesse exemplo, o risco de desenvolver diabetes mellitus ao se exercitar com frequência maior ou igual a 4 vezes por semana é igual a 0,64 vezes o risco de desenvolver diabetes mellitus para homens inativos, desconsiderando a influência de outros fatores sobre o diabetes. Quando uma variável de exposição exerce um efeito protetor, o RR varia entre 0 e 1.
No exemplo da tabela 8.3, tomando o nível de IMC 14,5 – 24,9 kg/m2 como referência, o RR é dada por:
\[\begin{equation} RR = \frac{R_{IMC \ge 30}}{R_{14,5<IMC<25}}=\frac{\frac{156}{1384}}{\frac{95}{10988}}=13,0 \end{equation}\]
Nesse exemplo, o risco de desenvolver diabetes mellitus com um IMC \(\ge\) 30 kg/m2 é 13,0 vezes maior do que o risco de desenvolver diabetes mellitus em comparação com um IMC na faixa entre 14,5 e 25 kg/m2, desconsiderando a influência de outros fatores sobre o diabetes. Nesse caso, a adiposidade é considerada um fator de risco em relação ao diabetes mellitus. Para uma variável de exposição cujo efeito aumenta o risco, o RR é maior que 1.
Quando o RR é igual a 1, isso significa que a variável de exposição considerada não tem influência sobre o desfecho clínico.
8.2.4 Diferença relativa de riscos
A Diferença Relativa de Riscos (DRR) é uma estimativa do percentual do risco basal (nível de referência) que é removido (ou aumentado) como resultado do fator em estudo; ela é calculada como o oposto da diferença absoluta de riscos entre os grupos (níveis do fator) estudados, dividida pelo risco absoluto nos pacientes no grupo de referência.
Para a tabela 1, a DRR é calculada por:
\[\begin{equation} DRR = \frac{R_{N2}-R_{N1}}{R_{N2}} = \frac{-DAR}{R_{N2}} = 1 - RR \tag{8.6} \end{equation}\]
Para os dados da tabela 8.2, a DRR é dada por:
\[\begin{equation} DRR = \frac{R_{inativo}-R_{exercita4+}}{R_{inativo}}=\frac{0,037-0,024}{0,037}=0,362=36,2\% \end{equation}\]
Nesse caso, podemos interpretar a diferença relativa de riscos como a redução relativa do risco de desenvolver diabetes mellitus devido à atividade física. Houve uma redução relativa de 36,2% no risco de desenvolver diabetes mellitus no grupo de homens que se exercitam com frequência maior ou igual a 4 vezes por semana em relação ao grupo de inativos, desconsiderando a influência de outros fatores sobre o diabetes.
Para os dados da tabela 8.3, a DRR é dada por:
\[\begin{equation} DRR = \frac{R_{14,5<IMC<25}-R_{IMC \ge 30}}{R_{14,5<IMC<25}}=\frac{0,0086-0,11}{0,0086}=-12,04=-1204\% \end{equation}\]
Nesse caso, podemos inverter o sinal e interpretar a diferença relativa de riscos como o aumento relativo do risco de desenvolver diabetes mellitus devido ao índice de massa corporal mais elevado. Houve um aumento relativo de 1204% no risco de desenvolver diabetes mellitus com um IMC \(\ge\) 30 kg/m2 em relação ao grupo com IMC na faixa entre 14,5 e 25 kg/m2, desconsiderando a influência de outros fatores sobre o diabetes.
8.2.5 Resumo das medidas de associação apresentadas até o momento
A tabela 8.4 apresenta os valores das medidas de associação apresentadas até o momento para diferentes configurações dos riscos absolutos para o nível de referência (Risco basal) e para o nível de interesse.
| Situação | Risco Basal (Referência) | Risco nível de interesse | Risco Relativo | Diferença Relativa de Riscos | Diferença Absoluta de Riscos | NNT |
|---|---|---|---|---|---|---|
| 1 | 0,02 | 0,01 | 0,5 | 50% | -0,01 | 100 |
| 2 | 0,4 | 0,2 | 0,5 | 50% | -0,2 | 5 |
| 3 | 0,04 | 0,02 | 0,5 | 50% | -0,02 | 50 |
| 4 | 0,04 | 0,03 | 0,75 | 25% | -0,01 | 100 |
| 5 | 0,4 | 0,3 | 0,75 | 25% | -0,1 | 10 |
| 6 | 0,01 | 0,005 | 0,5 | 50% | -0,005 | 200 |
As seguintes observações podem ser feitas em relação a essa tabela:
1) nas duas primeiras linhas, o risco relativo é igual, o mesmo acontecendo com a diferença relativa de riscos. Porém a diferença absoluta de riscos e, consequentemente o NNT, são bastante diferentes;
2) nas linhas 1 e 4, as diferenças absolutas de riscos são iguais, mas os valores do risco relativo e diferença relativa de riscos são diferentes;
3) para diferentes valores da diferença absoluta de riscos (linhas 1, 2 e 3 ou linhas 4 e 5), os valores do risco relativo e diferença relativa de riscos podem ser iguais (linhas 1, 2 e 3), mas também podem ser diferentes (linhas 1 e 4);
4) os valores do risco relativo e diferença relativa de riscos podem ser iguais para diferentes configurações de riscos (linhas 1, 2, 3 e 6 e também linhas 4 e 5), mas também podem ser diferentes (linhas 3 e 4 e também linhas 5 e 6);
5) quanto menor a diferença absoluta de riscos, maior o valor do NNT e mais pessoas precisam ser submetidas ao grupo de tratamento para observarmos um caso que se beneficiaria do tratamento.
A diferença relativa de riscos pode ser obtida a partir do risco relativo, e o número necessário para tratar pode ser obtido a partir da diferença absoluta de risco, mas a relação entre a diferença absoluta de riscos (número necessário para tratar) e o risco relativo (diferença relativa de riscos) depende dos riscos absolutos de cada nível do fator em estudo.
Na apresentação dos dados de um estudo, é boa prática apresentar a tabela sempre que possível para permitir que o usuário derive as diversas medidas de associação e extraia as suas próprias conclusões. Isso evita a situação em que autores chamem atenção para os seus resultados, apresentando somente as medidas com valores “atraentes”.
A diferença absoluta de riscos e o número necessário para tratar são medidas úteis na gestão em saúde, particularmente na decisão sobre alocação de recursos. Quanto menor o NNT de um dado tratamento, por exemplo, maior o impacto da aplicação desse tratamento na população e mais eficiente a alocação de recursos para esse tratamento em relação a um outro tratamento com NNT maior. Obviamente, deve ser levado em conta que nenhuma medida isoladamente deve ser o fator determinante para a alocação de recursos.
O risco relativo é frequentemente utilizado em epidemiologia para expressar a força de associação entre, por exemplo, um fator de exposição e uma dada doença.
8.2.6 Razão de chances (odds ratio)
Os conteúdos desta seção e da seção seguinte (8.2.7) podem ser visualizados neste vídeo.
8.2.6.1 Chance (odds) de ocorrência de um evento
Seja p a probabilidade (risco) de ocorrência de um evento, um número entre 0 e 1. A chance de ocorrência C desse evento é dada por:
\[\begin{equation} C = \frac{p}{1-p} \tag{8.7} \end{equation}\]
A tabela 8.5 lista alguns valores para a probabilidade e o correspondente valor para a chance. Observem que a chance pode variar de 0 até \(+\infty\). Para valores pequenos da probabilidade, digamos abaixo de 10%, o valor da chance é próximo ao valor da probabilidade. À medida que a probabilidade aumenta, os valores da chance se afastam cada vez mais do correspondente valor da probabilidade. Assim não é correto interpretar a chance como probabilidade.
| Risco | Chance |
|---|---|
| 0 (0%) | 0 |
| 0,05 (5%) | 0,053 |
| 0,1 (10%) | 0,11 |
| 0,2 (20%) | 0,25 |
| 0,3 (30%) | 0,43 |
| 0,4 (40%) | 0,67 |
| 0,5 (50%) | 1 |
| 0,6 (60%) | 1,5 |
| 0,7 (70%) | 2,3 |
| 0,8 (80%) | 4 |
| 0,9 (90%) | 9 |
| 0,95 (95%) | 19 |
| 0,99 (99%) | 99 |
A chance é frequentemente usada em bolsa de apostas. Quando se fala que a chance de um cavalo ganhar a corrida é de 8 para 1 (chance = 8), isso significa que o cavalo ganharia 8 corridas para cada uma que perdesse. Isso corresponderia a uma probabilidade de ganhar de 8/9 (89%). Esse valor poderia ser obtido, expressando a probabilidade em função da chance na expressão (8.7):
\[\begin{equation} (1-p)C =p \ \Rightarrow \ p= \frac{C}{1+C} \end{equation}\]
Na tabela 8.2, a chance de ocorrência de diabetes para homens inativos é dada por:
\[\begin{equation} C_{Inativo} = \frac{R_{Inativo}}{1-R_{Inativo}}=\frac{0,037}{1-0,037}=0,0384 \end{equation}\]
e para pessoas que exercitam 4 ou mais vezes por semana:
\[\begin{equation} C_{exercita4+} = \frac{R_{exercita4+}}{1-R_{exercita4+}}=\frac{0,024}{1-0,024}=0,0246 \end{equation}\]
Na tabela 8.3, a chance de ocorrência de diabetes para homens com IMC na faixa 14,5-25 kg/m2 é dada por:
\[\begin{equation} C_{14,5<IMC<25} = \frac{R_{14,5<IMC<25}}{1-R_{14,5<IMC<25}}=\frac{0,0086}{1-0,0086}=0,0087 \end{equation}\]
e para pessoas com \(IMC \ge 30\ kg/m^2\):
\[\begin{equation} C_{IMC \ge 30} = \frac{R_{IMC \ge 30}}{1-R_{IMC \ge 30}}=\frac{0,11}{1-0,11}=0,124 \end{equation}\]
8.2.6.2 Razão de chances (odds ratio)
A Razão de Chances (RC) de ocorrência de um evento para uma variável de exposição é expressa pela razão entre as chances associadas aos respectivos níveis da variável de exposição considerada, tomando um dos níveis como referência. Assim sendo, na tabela 8.1, a RC de ocorrência de diabetes para a variável de exposição, tomando o nível 2 como referência, é dada por:
\[\begin{equation} RC = \frac{C_{N1}}{C_{N2}} \end{equation}\]
No exemplo da tabela 8.2, a RC de ocorrências de diabetes para a atividade física entre os homens, tomando a inatividade como referência, é dada por:
\[\begin{equation} RC = \frac{C_{exercita4+}}{C_{inativo}}=\frac{45\ .\ 1875}{73\ .\ 1836}= 0,630 \end{equation}\]
Nesse exemplo, a chance de desenvolver diabetes mellitus ao se exercitar com frequência maior ou igual a 4 vezes por semana é igual a 0,63 vezes maior do que a chance de desenvolver diabetes mellitus para homens inativos, desconsiderando a influência de outros fatores sobre o diabetes, ou seja, o exercício reduz a chance de ocorrência de diabetes mellitus. Quando uma categoria de exposição exerce um efeito protetor, a RC varia entre 0 e 1. Observem que, nesse caso, a RC é menor do que o RR.
No exemplo da tabela 8.3, tomando o nível de IMC 14,5 – 24,9 kg/m2 como referência, a RC é dada por:
\[\begin{equation} RC = \frac{C_{IMC \ge 30}}{C_{14,5<IMC<25}}=\frac{156\ .\ 10893}{95\ .\ 1228}= 14,6 \end{equation}\]
Nesse exemplo, a chance de desenvolver diabetes mellitus com um IMC \(\ge\) 30 kg/m2 é 14,6 vezes maior do que a chance de desenvolver diabetes mellitus em comparação com um IMC na faixa 14,5–24,9 kg/m2, desconsiderando a influência de outros fatores sobre o diabetes. Nesse caso, a adiposidade é considerada um fator de risco para o diabetes mellitus. Para uma categoria de exposição cujo efeito aumenta a chance, a RC é maior que 1. Observem que, nesse caso, a RC é maior do que o RR.
8.2.7 Razão de chances e risco relativo
Foi visto na seção anterior que a razão de chances superestima o risco relativo quando ele é maior que 1 e subestima o risco relativo quando o mesmo é menor que 1. Duas perguntas podem ser feitas em relação à razão de chances:
1) Por que usar a razão de chances como medida de associação?
2) Quando a razão de chances pode ser utilizada como uma aproximação para o risco relativo?
Em relação à primeira pergunta, a razão de chances é uma das medidas de associação mais utilizadas em estudos de metanálise e estudos de caso-controle. Além disso, ela é obtida diretamente a partir dos modelos de regressão logística, que é um dos modelos estatísticos mais utilizados na literatura médica.
Para responder à segunda pergunta, vamos utilizar a análise apresentada por Davies, Crombie, and Tavakoli (Davies, Crombie, and Tavakoli 1998).
Sejam P1 e P2 as proporções de indivíduos que experimentam um evento em dois grupos 1 e 2, respectivamente. Seja o grupo 1 o grupo de referência e vamos chamar de P1 o risco basal ou risco de referência. Então o risco relativo (RR) é dado por: \[\begin{equation} RR = \frac{P_2}{P_1} \end{equation}\]
A partir da definição de razão de chances (RC), ela pode ser escrita como:
\[\begin{equation} RC = \frac{1-P_1}{1-P_2}RR \end{equation}\]
Com alguma manipulação algébrica, é possível representar a discrepância entre a razão de chances e o risco relativo como uma proporção do risco relativo.
Para estudos onde a razão de chances é > 1, essa discrepância é expressa por: \[\begin{equation} RC-RR = P_1\ (RC-1)\ RR \end{equation}\]
Para estudos onde a razão de chances é < 1, essa discrepância é expressa por: \[\begin{equation} RC-RR = P_1\ (1-RC)\ RR \end{equation}\]
O multiplicador do risco relativo nas expressões acima, \(P_1\ (RC-1)\) ou \(P_1\ (1-RC)\), fornece o quanto a razão de chances superestima ou subestima o risco relativo, expresso como uma proporção do risco relativo. Essa proporção depende do risco basal (inicial ou referência) e do valor da razão de chances.
A aplicação Risco Relativo x Razão de Chances mostra o quanto a razão de chances subestima ou superestima o risco relativo, para um determinado nível do risco basal (nível de referência). Nessa aplicação, cuja tela inicial é mostrada na figura 8.1, as linhas vermelhas mostram a discrepância da razão de chances em relação ao risco relativo em função do risco basal, expressa em porcentagem. Para cada valor da razão de chance, uma reta diferente é obtida. Algumas linhas de referência com os respectivos valores da razão de chance são mostradas. O gráfico superior mostra as retas para valores da razão de chance acima de 1. O gráfico da parte inferior mostra as retas para valores da razão de chance abaixo de 1. O ponto em azul no gráfico mostra a discrepância para o valor do risco basal selecionado no painel à esquerda. Experimente a aplicação com diferentes valores da razão de chances e risco basal.
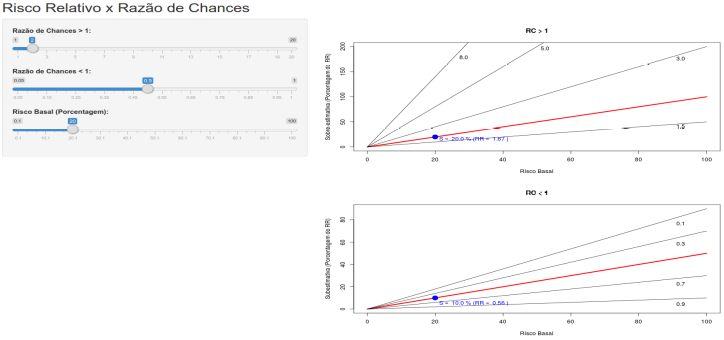
Figura 8.1: Aplicação que mostra o quanto a RC superestima ou subestima o RR em função do risco basal. No gráfico superior, o ponto em azul indica que, para o risco basal de 20%, a RC (2 nesse exemplo) é 20% maior do que o risco relativo. No gráfico inferior, o ponto em azul indica que, para o risco basal de 20%, a RC (0,5 nesse exemplo) é 10% inferior ao risco relativo.
Os gráficos mostram que, para razões de chances menores que 1, mesmo com riscos basais tão grandes quanto 50% e grandes reduções no risco (razão de chances em torno de 0,1), a razão de chances é somente 50% menor do que o risco relativo. De fato, para razão de chances menores que 1, a discrepância entre a razão de chances e o risco relativo nunca será maior do que o risco basal.
Para razões de chances maiores que 1, embora grandes desvios entre a razão de chances e o risco relativo são possíveis, a razão de chances exagera o risco relativo em menos de 50% para uma vasta gama de riscos basais e razão de chances. Para riscos basais de 10% ou menos, mesmo razões de chances de até 6 podem razoavelmente ser interpretadas como riscos relativos (discrepância menor que 50%). Como regra conservadora, se o risco basal multiplicado pela razão de chances for inferior a 100%, a razão de chances será menor do que o dobro do risco relativo.
Resumindo, vale a pena reproduzir aqui a conclusão da análise de Davies, Crombie, and Tavakoli (Davies, Crombie, and Tavakoli 1998):
“A razão de chances pode ter uma interpretação não intuitiva, mas, em quase todos os casos realistas, interpretando-as como se fossem riscos relativos, é improvável que qualquer avaliação qualitativa dos resultados do estudo seja alterada. A razão de chances sempre irá exagerar o valor quando interpretada como um risco relativo, e o grau de exagero irá aumentar à medida que aumenta o risco basal e o efeito do fator em estudo. No entanto não há nenhum ponto em que o grau de exagero é susceptível de conduzir a diferentes julgamentos qualitativos sobre o estudo. Discrepâncias significativas entre a razão de chances e o risco relativo são vistas apenas quando os efeitos do fator em estudo são grandes e o risco basal é elevado. Se um grande aumento ou um grande decréscimo do risco é indicado, nossos julgamentos serão provavelmente os mesmos: os efeitos são importantes.”
A razão de chances é utilizada frequentemente nas seguintes situações:
- Como aproximação do risco relativo, particularmente em estudos de caso-controle, onde não se conhece o risco de ocorrência do desfecho no grupo de referência ou não seja possível estimar o risco relativo;
- em modelos de regressão logística, nos quais os coeficientes de cada variável do modelo são relacionados com a razão entre as chances de ocorrência do desfecho para os respectivos níveis da variável;
- em estudos de metanálise, como expressão da medida de associação comum dos diversos estudos analisados.
8.3 Medidas de associação no R
O conteúdo desta seção pode ser visualizado neste vídeo, seguido deste vídeo e deste vídeo.
Nesta seção, será mostrado como obter no R as medidas de associação apresentadas nas seções anteriores. Para isso, será utilizado o conjunto de dados stroke do pacote ISwR (GPL-2 | GPL-3). Para ler um conjunto de dados de um pacote do R, siga os passos especificados no capítulo 2, seção 2.2. O conjunto de dados stroke contém todos os casos de AVC (acidente vascular cerebral) (829 observações) em Tartu, Estonia, durante 1991-1993, com acompanhamento até 1o de janeiro de 1996.
Vamos obter as medidas de associação entre as variáveis:
- dead: variável categórica binária, com os valores TRUE, se o paciente faleceu, e FALSE, se
o paciente continuava vivo ao final do estudo, e
- diab: história de diabetes, variável categórica binária, com os valores No e Yes.
Vamos tomar a ausência de história de diabetes como nível de referência e vamos comparar os riscos de morte entre aqueles com ou sem histórico de diabetes.
Recordando, para abrir o conjunto de dados via R Commander, executamos a função
na área de script do R Commander e, em seguida, selecionamos o conjunto stroke via:
\[\text{Dados} \Rightarrow \text{Conjunto de dados em pacotes} \Rightarrow \text{Ler conjunto de dados de pacotes 'atachados'}\]
Em seguida, selecionamos o conjunto de dados stroke no pacote ISwR (figura 8.2).
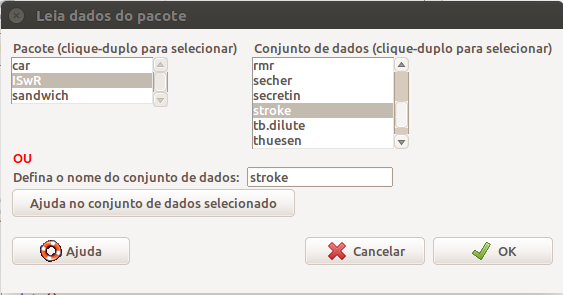
Figura 8.2: Tela para a leitura do conjunto de dados stroke do pacote ISwR via R Commander.
As tabelas que mostram a contagem para cada combinação das categorias das variáveis categóricas são também chamadas tabelas de contingência. Quando há duas variáveis categóricas binárias, a tabela de contingência também é chamada tabela de dupla entrada ou tabela 2x2.
Vamos analisar uma tabela 2x2 no R Commander. Selecionamos a opção:
\[\text{Estatísticas} \Rightarrow \text{Tabelas de contingência} \Rightarrow \text{Tabela de dupla entrada...}\]
Na tela de configuração do comando para analisar uma tabela 2x2, é preciso selecionar a variável cujas categorias aparecerão nas linhas da tabela e a outra variável cujas categorias comporão as colunas da tabela (figura 8.3).
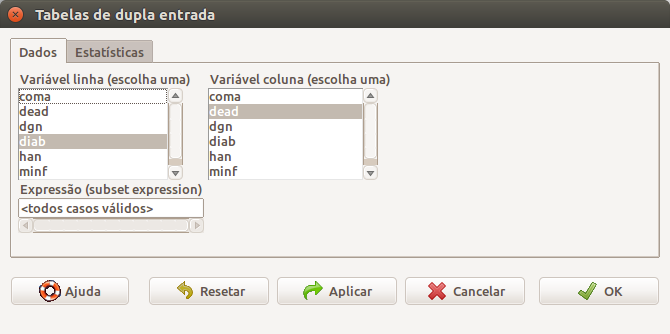
Figura 8.3: Selecionando as variáveis da tabela 2x2.
Na aba Estatísticas, vamos marcar as opções Percentual das linhas, Teste do Qui-Quadrado e Teste exato de Fisher (figura 8.4). Vamos clicar no botão OK.
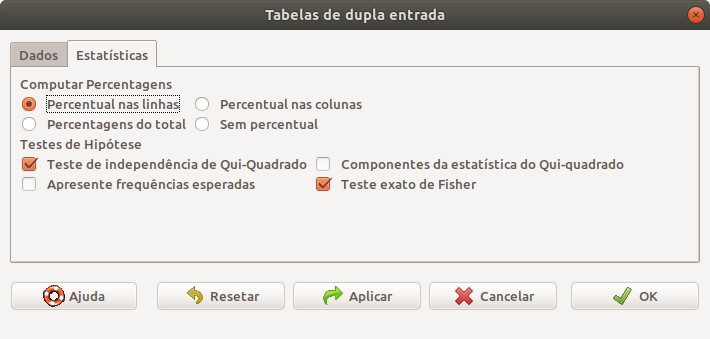
Figura 8.4: Opções para a análise de uma tabela de contingência 2x2 por meio do R Commander.
Os resultados são mostrados na figura 8.5. As frequências da tabela 2x2 são mostradas na primeira tabela. Observem que as colunas e linhas são ordenadas, por padrão, em ordem alfabética (linhas vermelhas).
Os riscos de morte com ou sem história de diabetes são mostrados abaixo de Row percentages (círculo verde). Em seguida, são mostrados os testes estatísticos do qui-quadrado e teste exato de Fisher e o intervalo de confiança para a razão de chances. Finalmente é mostrada a estimativa da razão de chances para essa tabela (linha alaranjada).
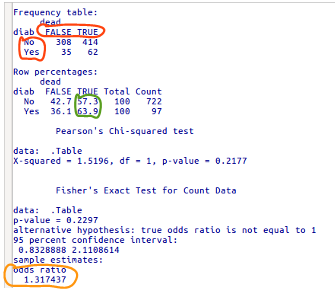
Figura 8.5: Resultado da análise da tabela de contingência 2x2 por meio do R Commander.
Observem, porém, que a tabela 2x2 foi montada de tal forma que a primeira linha corresponde àqueles sem história de diabetes e a segunda linha àqueles com história de diabetes. A primeira coluna corresponde aos sobreviventes e a segunda coluna aos mortos. Para calcularmos as medidas de associação entre a ocorrência de morte e histórico ou não de diabetes, precisamos montar a tabela de modo que a primeira linha corresponda aos casos com histórico de diabetes e a primeira coluna aos casos de morte. Para isso, basta alterar a ordem dos níveis das variáveis diab e dead, utilizando os dois comandos abaixo:
stroke$diab <- ordered(stroke$diab, levels=c("Yes", "No"))
stroke$dead <- ordered(stroke$dead, levels=c("TRUE", "FALSE"))O primeiro comando ordena os níveis da variável diab do conjunto de dados stroke, sendo a ordem especificada pelo argumento levels. Recordando, o $ é utilizado para separar a variável do conjunto de dados. O comando seguinte ordena os nívels da variável dead.
Ao executarmos esses dois comandos e repetirmos a análise da tabela de contingência no R Commander, obtemos os resultados da figura 8.6.
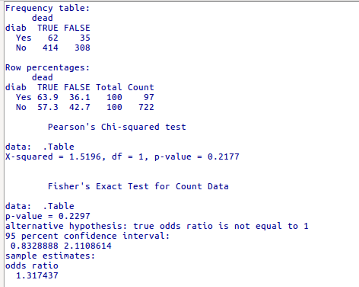
Figura 8.6: Análise da tabela 2 x 2 (diab x dead) após a reordenação dos níveis dos fatores.
Observem agora que as linhas e colunas estão ordenadas da forma desejada: o desfecho de interesse (morte) na primeira coluna e a exposição de interesse (história de diabetes) na primeira linha.
A partir dos valores do risco de morte para histórico ou não de diabetes, podem ser obtidas as demais medidas de associação vistas neste capítulo. Porém vamos verificar uma forma de obtê-las diretamente do R. É imprescindível que os fatores estejam com os níveis ordenados de modo adequado. Caso contrário, as medidas de associação obtidas podem não ser calculadas corretamente.
Para isso, vamos instalar o pacote epiR, conforme mostrado na seção A.6. Uma vez instalado o pacote, vamos executar o seguinte script no R Commander:
library(epiR)
tab <- table(stroke$diab, stroke$dead)
epi.2by2(tab, method = 'cohort.count', conf.level = 0.95)A primeira função carrega o pacote epiR para ser utilizado. A segunda função cria uma tabela 2x2 a partir das variáveis diab e dead do conjunto de dados stroke. A tabela criada é armazenada no objeto tab. Finalmente a função epi.2by2 irá gerar as medidas de associação para a tabela criada e calcular o intervalo de confiança para cada uma das medidas de associação, utilizando o método de coortes, supondo que esse tenha sido o método utilizado para a coleta de dados do conjunto stroke. As medidas de associação são mostradas na figura 8.7.
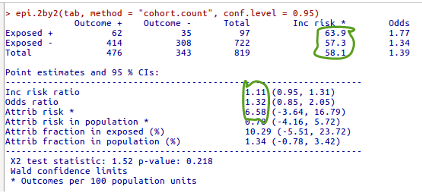
Figura 8.7: Medidas de associação obtidas para a tabela da figura 8.6 por meio do pacote epiR. Os riscos absolutos e as medidas de associação são mostrados dentro das linhas verdes.
O epiR sempre considera a primeira linha como Exposed + (nesse caso com histórico de diabetes) e a segunda linha como Exposed - (sem histórico de diabetes). Analogamente, a primeira coluna seria Outcome + (Morte) e a segunda coluna Outcome – (Vivo). Por isso é fundamental que os níveis dos fatores estejam ordenados adequadamente.
No epiR, o risco relativo é expresso como Inc risk ratio, abaixo de Point estimates and 95% CIs. A diferença absoluta de riscos é expressa como Attrib risk. São mostrados as estimativas dessas medidas e os respectivos intervalos de confiança entre parênteses.
8.4 Exercícios
- Qual é a relação entre o risco relativo e a razão de chances?
- Considere a tabela 8.6 abaixo. Nela estão representados resultados de diversos estudos controlados com dois grupos, com os resultados em cada grupo expressos na linha correspondente a cada estudo. A partir dos resultados apresentados, calcule e preenche as lacunas para cada medida de associação expressa na tabela.
| Risco Basal (Controle) | Risco Grupo de Estudo | Risco Relativo | Razão de Chances | Diferença Absoluta de Riscos | NNT |
|---|---|---|---|---|---|
| 0,005 | 0,01 | ||||
| 0,3 | 0,6 | ||||
| 0,01 | 0,005 | ||||
| 0,2 | 0,1 |
Três estudos diferentes que avaliaram a associação entre duas variáveis dicotômicas obtiveram os seguintes valores para o risco relativo: 0,5; 1 e 3, respectivamente. Que valores de razão de chances são compatíveis com os valores de RR na ordem?
- 1; 0,7 e 4
- 0,4; 1 e 4
- 0,7; 1 e 2
- 0,4; 1 e 2
- 0,7; 1 e 4
- 0,7; 4 e 1
Carregue o conjunto de dados stroke do pacote ISwR.
- Veja a ajuda do conjunto de dados.
- Faça uma tabela 2x2, relacionando as variáveis han e coma e obtenha as medidas de associação: diferença de riscos, risco relativo e razão de chances. Interprete os resultados.
- Faça uma tabela 2x2, relacionando as variáveis minf e dead e obtenha as medidas de associação: diferença de riscos, risco relativo e razão de chances. Interprete os resultados.
- Gere o relatório.