2 Tabelas de frequências
2.1 Introdução
Os conteúdos desta seção e das seções 2.2 e 2.3.1 podem ser visualizados neste vídeo.
Neste capítulo, serão apresentadas diversas formas para apresentar em tabelas a frequência ou porcentagem das categorias de uma variável categórica ou de combinação de categorias de variáveis categóricas em um conjunto de dados. As tabelas assim obtidas são também chamadas de tabelas de contingência.
A figura 2.1 mostra a tabela 2 do estudo de Barata e Valete (Barata and Valete 2018), intitulado “Perfil clínico-epidemiológico de 106 pacientes pediátricos portadores de urolitíase no Rio de Janeiro”. Essa tabela mostra a frequência de ocorrência das categorias das variáveis sexo, cor da pele, idade no início dos sintomas e idade no diagnóstico.
A frequência de uma categoria de uma variável categórica em um conjunto de dados é o número de observações daquela categoria da variável no conjunto de dados. Na figura 2.1, vemos que a frequência de mulheres no estudo é 52 e de homens, 54. Em relação à cor da pele, 67 pessoas eram brancas, 30 pardas, 8 negras e 1 amarela.
Se dividirmos a frequência de uma categoria de uma variável pelo número total de observações, obtemos a proporção da respectiva categoria da variável no conjunto de dados. Multiplicando essa proporção por 100, obtemos então a porcentagem da categoria da variável no conjunto de dados. Na figura 2.1, vemos que a porcentagem de mulheres no estudo é 49,1% e de homens, 50,9%.
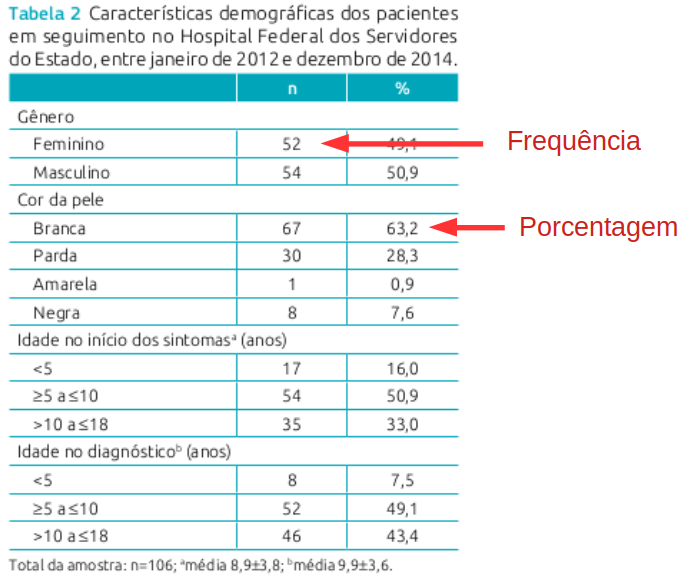
Figura 2.1: Características demográficas dos pacientes pediátricos portadores de urolitíase no Rio de Janeiro em seguimento no Hospital Federal dos Servidores do Estado. Fonte: (Barata and Valete 2018) (CC BY).
O conjunto dos pares formados pelas categorias de uma variável em um conjunto de dados, juntamente com as suas respectivas frequências, é chamado de distribuição de frequências da variável.
A figura 2.2 mostra a tabela 2 do estudo de Vanin et al. (Vanin et al. 2019), intitulado “Fatores de risco materno-fetais associados à prematuridade tardia”. Essa tabela mostra, entre outras, a distribuição de frequência conjunta das variáveis sexo e maturidade. A variável maturidade possui dois níveis ou categorias: RNPT - recém-nascido prematuro tardio e RNT - recém-nascido a termo. Para cada categoria da variável maturidade, a tabela mostra as frequências de cada categoria da variável sexo e entre parênteses a porcentagem da respectiva categoria de sexo em relação à frequência total do nível de maturidade correspondente. Por exemplo, entre os recém-nascidos a termo, a frequência do sexo feminino é 124, correspondendo a 44,1% do total de crianças recém-nascidas a termo (124 de 281).

Figura 2.2: Tabela 2 do estudo de Vanin et al., mostrando a frequência conjunta de diversas variáveis e o nível de maturidade das crianças recém-nascidas do estudo. Fonte: (Vanin et al. 2019) (CC BY).
Para mostrar como obtemos distribuições de frequências de variáveis ou combinação de variáveis em um conjunto de dados no ambiente R, vamos utilizar o conjunto de dados stroke do pacote ISwR (GPL-2 | GPL-3). Esse conjunto de dados contém todos os casos de AVC (acidente vascular cerebral) em Tartu, Estonia, durante 1991-1993, com acompanhamento até 1o de janeiro de 1996.
Na seção seguinte, vamos carregar o conjunto de dados stroke no R para podermos analisá-lo.
2.2 Carregando conjuntos de dados de pacotes do R
Ao abrir o R Commander via RStudio ou diretamente a partir da tela de entrada do R, temos acesso ao menu principal e uma janela com duas abas: Script e Markdown.
Muitos pacotes do R contêm conjuntos de dados que podem ser utilizados para ilustrar os recursos disponíveis no pacote. O conjunto de dados stroke pertence ao pacote ISwR.
O pacote ISwR precisa ser instalado. Os passos para a instalação desse pacote são os mesmos utilizados para a instalação do R Commander, seção A.6.
De outra maneira, podemos digitar o comando a seguir na console do RStudio e pressionar a tecla Enter. De maneira alternativa, com o mesmo comando na área de script do R Commander e, com o cursor na linha do comando, clicamos no botão Submeter. Como o nome indica, a função install.packages instala o pacote especificado entre aspas.
Antes de abrirmos o conjunto de dados stroke, é preciso carregar o pacote ISwR. Na sequência deste capítulo, utilizaremos o R Commander, carregado a partir do R e não a partir do RStudio.
Para carregarmos o pacote ISwR a partir do R Commander, digitamos library(ISwR) na área de script do R Commander e, com o cursor na linha do comando, clicamos no botão Submeter (figura 2.3).
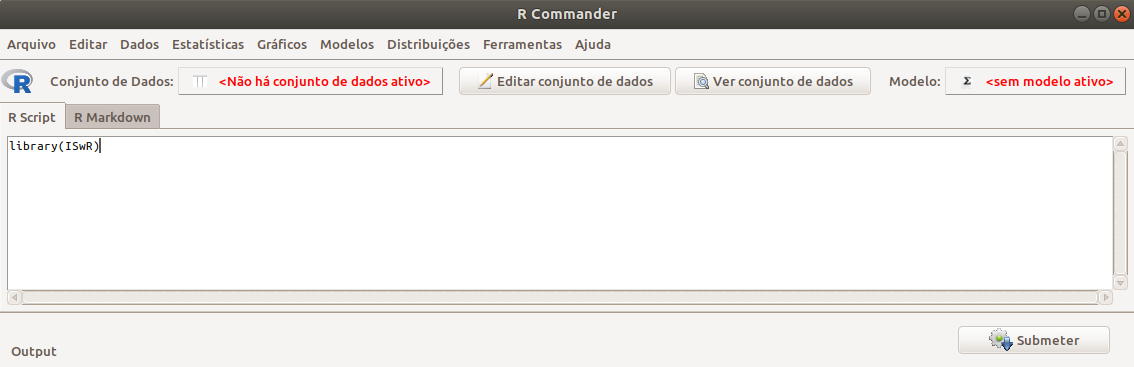
Figura 2.3: Tela do R commander, com a digitação da função library(ISwR) na área de Script.
Ao submetermos a função, ela aparece na área de output do R Commander (figura 2.4) e, se houver alguma coisa errada, uma mensagem de erro apareceria na área de mensagens do R Commander.
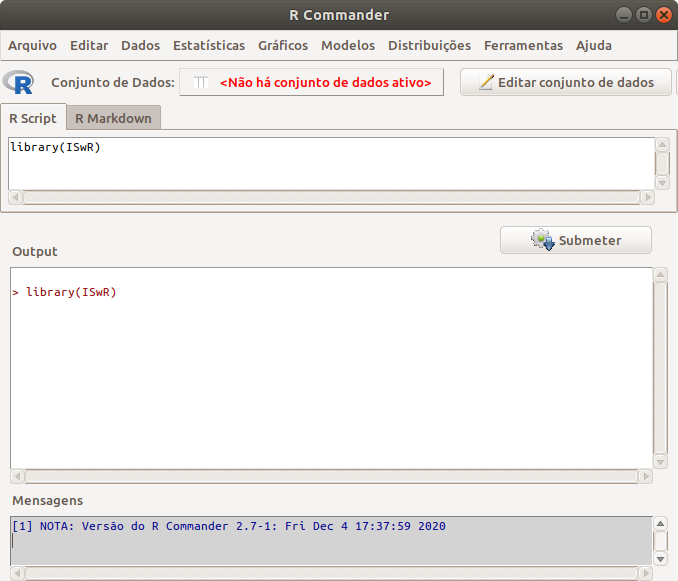
Figura 2.4: Tela do R Commander após a execução da função library conforme mostrado na figura 2.3.
Alternativamente o pacote ISwR poderia ser carregado por meio da opção de menu do R Commander:
\[\text{Ferramentas} \Rightarrow \text{Carregar pacote(s)...}\]
A função library(ISwR) carregou a biblioteca ISwR, a qual contém uma série de conjuntos de dados que podemos utilizar. Para visualizar e, eventualmente, selecionar um desses conjuntos de dados, selecionamos a opção abaixo no R Commander (figura 2.5):
\[\text{Dados} \Rightarrow \text{Conjunto de dados em pacotes} \Rightarrow \text{Ler dados de pacote 'atachado'}\]
A partir de agora, toda opção a ser selecionada no menu será apresentada como uma sequência de itens a serem selecionados como acima.
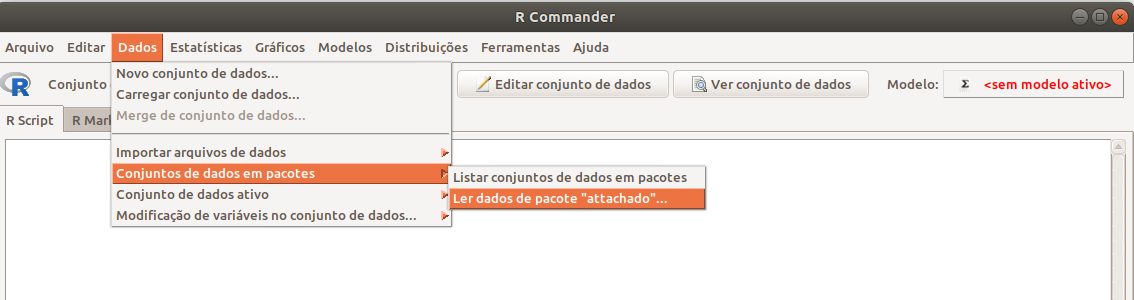
Figura 2.5: Menu do R Commander com a opção para carregar arquivos de pacotes do R.
Na tela Leia dados do pacote (figura 2.6), observem que alguns pacotes aparecem na área à esquerda da figura: carData, datasets, ISwR e sandwich. Para ver a lista dos conjuntos de dados em ISwR, demos um duplo clique nesse pacote e uma lista de conjuntos de dados será mostrada à direita (figura 2.6). Rolamos essa lista e clicamos no conjunto stroke para selecioná-lo. Para conhecermos a estrutura desse conjunto de dados, clicamos no botão Ajuda para o conjunto de dados selecionado (seta verde na figura). Uma descrição desse conjunto de dados será exibida no seu navegador padrão (figura 2.7). Ao clicarmos no botão OK na figura 2.6, após termos selecionado stroke, esse conjunto de dados será carregado no R commander (figura 2.8).
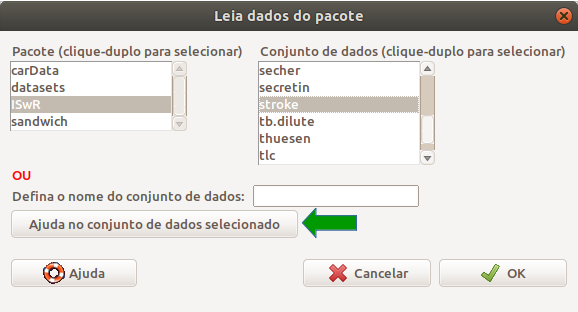
Figura 2.6: Visualizando a lista de conjuntos de dados do pacote ISwR e selecionando o conjunto stroke.

Figura 2.7: Texto com a descrição do conjunto de dados stroke.
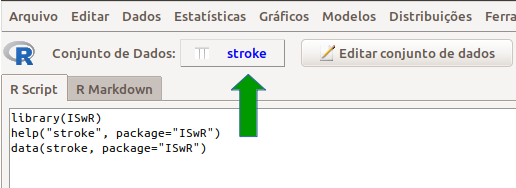
Figura 2.8: Tela do R commander após o carregamento do conjunto de dados stroke. Observem a função que foi executada – data(stroke, package="ISwR") – e o nome do conjunto selecionado (seta verde).
Observem as funções que foram executadas no R Commander:
A função help mostra uma ajuda sobre o conjunto de dados stroke do pacote ISwR.
A função data(stroke, package="ISwR") carrega o conjunto de dados stroke que passa a ser o conjunto de dados ativo no R Commander. Observem o nome dele ao lado do rótulo conjunto de dados (seta verde na figura 2.8). Esse objeto pode ser acessado pelo próprio nome (stroke nesse caso).
Na área de mensagens do R Commander, aparece a seguinte mensagem abaixo do comando, indicando o número de registros e de variáveis no conjunto de dados stroke:
NOTA: Os dados stroke tem 829 linhas e 11 colunas.Para visualizarmos o conteúdo do conjunto de dados stroke, clicamos no botão Ver conjunto de dados (seta verde na figura 2.9).
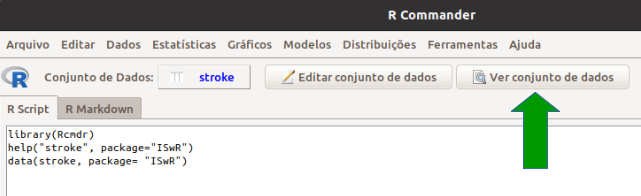
Figura 2.9: Botão do R Commander (seta verde) para exibir o conteúdo do conjunto de dados ativo.
A figura 2.10 mostra as observações do conjunto de dados stroke.
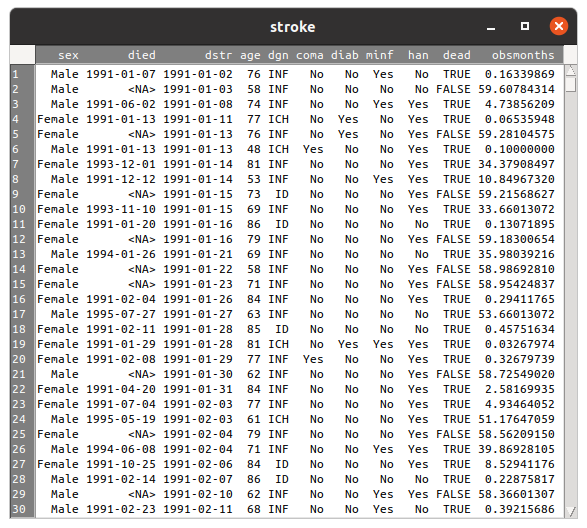
Figura 2.10: Conteúdo do conjunto de dados stroke.
Para mostrar como obter distribuições de frequências de variáveis categóricas e gerar tabulações de dados com combinações de variáveis categóricas, vamos trabalhar com as seguintes variáveis do conjunto de dados stroke (figura 2.7):
- dead: variável categórica binária, com os valores TRUE, se o paciente faleceu, e FALSE, se o paciente continuava vivo ao final do estudo;
- dgn: diagnóstico do paciente, variável categórica nominal, com as categorias ICH (hemorragia intracranial), ID (não identificado), INF (infarto), SAH (hemorragia subaracnóide);
- minf: história de infarto do miocárdio, variável categórica binária, com os valores No e Yes;
- diab: história de diabetes, variável categórica binária, com os valores No e Yes.
2.3 Tabelas de frequências no conjunto de dados stroke
2.3.1 Uma única variável categórica
Para construirmos uma tabela que mostra a frequência ou porcentagem de cada categoria de uma variável categórica no R Commander, usamos a opção:
\[\text{Estatísticas} \Rightarrow \text{Resumos} \Rightarrow \text{Distribuições de frequência...}\]
Na tela dessa opção (figura 2.11), selecionamos uma ou mais variáveis para as quais desejamos a distribuição de frequências. Serão montadas tabelas para cada variável separadamente. Nesse exemplo, selecionamos a variável dead.
Figura 2.11: Caixa de diálogo para a seleção das variáveis categóricas cujas distribuições marginais serão exibidas.
Ao clicarmos em OK, os comandos abaixo serão executados, com os resultados mostrados logo a seguir.
local({
.Table <- with(stroke, table(dead))
cat("\ncounts:\n")
print(.Table)
cat("\npercentages:\n")
print(round(100*.Table/sum(.Table), 2))
})##
## counts:
## dead
## FALSE TRUE
## 344 485
##
## percentages:
## dead
## FALSE TRUE
## 41.5 58.5São mostradas duas tabelas, uma com a frequência de cada categoria da variável dead (TRUE, FALSE) no conjunto de dados stroke, e outra com as porcentagens de cada categoria.
No primeiro comando da sequência acima, mostrado novamente abaixo, a função with possui dois argumentos: o primeiro indica o conjunto de dados que será utilizado (stroke), e o segundo argumento indica a função que será executada com variáveis do conjunto de dados especificado no primeiro argumento. Nesse caso, é executada a função table para gerar uma tabela de frequência da variável entre parênteses.
O resultado da execução do comando é armazenado no objeto .Table.
O comando seguinte cat imprime uma linha na tela para informar que a tabela mostrada a seguir é relativa à contagem (counts:) ou frequência das categorias da variável. A barra invertida (“\”), seguida da letra “n” antes e depois da expressão “counts:”, indica que uma linha deve ser pulada antes e depois de escrever a expressão “counts:”.
O comando seguinte, print, mostra então a tabela de frequências da variável dead.
Vemos que 485 pacientes morreram e 344 continuavam vivos até o final do estudo. Esses números são obtidos, contando-se o número de observações no conjunto de dados stroke cujos valores da variável dead são TRUE ou FALSE, respectivamente.
Os dois comandos seguintes imprimem a expressão “percentages:” na tela e, em seguida, a tabela com as porcentagens de cada categoria da variável dead.
Vamos entender como as porcentagens foram calculadas. A função sum aplicada ao objeto .Table irá somar as frequências das categorias da variável dead (344 + 485 = 829). A expressão .Table/sum(.Table) então divide a frequência de cada categoria da variável dead pela soma das frequências, resultando nas proporções de cada categoria (344/829=0,41496; 485/829=0,58504). Esses dois valores são então multiplicados por 100 para fornecer as porcentagens de cada categoria (41,496; 58,504). A função round irá arredondar esses valores com duas casas decimais.
2.3.2 Tabelas de frequências para duas variáveis categóricas
Os conteúdos desta seção e da seção 2.3.3 podem ser visualizados neste vídeo.
Para gerarmos tabelas de frequências ou porcentagens para combinação das categorias de duas variáveis categóricas no R Commander, usamos a opção:
\[\text{Estatísticas} \Rightarrow \text{Tabelas de contingência} \Rightarrow \text{Tabela de dupla entrada...}\]
Esse tipo de tabela é chamada também de tabela de dupla entrada (por envolver duas variáveis).
Na aba Dados da tela dessa opção (figura 2.12), selecionamos as duas variáveis (uma cujas categorias irão aparecer nas linhas e outra cujas categorias irão aparecer nas colunas da tabela), para as quais desejamos a distribuição conjunta de frequências. Nesse exemplo, selecionamos a variável dgn (diagnóstico) para as linhas e dead para as colunas.
Figura 2.12: Tela para a seleção das variáveis categóricas que comporão a tabela de dupla entrada.
2.3.2.1 Obtendo os percentuais de cada célula em relação ao total da linha correspondente
Na aba Estatísticas (figura 2.13), vamos marcar a opção percentual nas linhas e desmarcar a opção Teste de independência de Qui-Quadrado. Nesse caso, a tabela de dupla entrada irá mostrar os percentuais de cada célula da tabela em relação ao total da linha correspondente.
Figura 2.13: Tela para especificar que a tabela de dupla entrada irá mostrar os percentuais de cada célula em relação ao total da linha correspondente.
Ao clicarmos em OK, os comandos abaixo serão executados, com os resultados mostrados logo a seguir.
local({
.Table <- xtabs(~dgn+dead, data=stroke)
cat("\nFrequency table:\n")
print(.Table)
cat("\nRow percentages:\n")
print(rowPercents(.Table))
})##
## Frequency table:
## dead
## dgn FALSE TRUE
## ICH 25 54
## ID 54 148
## INF 239 262
## SAH 26 21
##
## Row percentages:
## dead
## dgn FALSE TRUE Total Count
## ICH 31.6 68.4 100 79
## ID 26.7 73.3 100 202
## INF 47.7 52.3 100 501
## SAH 55.3 44.7 100 47Dessa vez, a tabela foi gerada por meio da função xtabs. Essa função utiliza uma fórmula para especificar as variáveis que comporão a tabela. Nessa fórmula, as variáveis são especificadas após o sinal ~, sendo a primeira variável aquela cujas categorias aparecerão nas linhas e a segunda variável aquela cujas categorias aparecerão nas colunas. As variáveis são separadas pelo sinal “+”. O argumento data especifica o conjunto de dados que contém as variáveis descritas na fórmula.
A função rowPercents, do pacote RcmdrMisc, gera os percentuais de cada célula em relação ao total da linha correspondente.
Assim a tabela de frequência mostra que, dos 79 pacientes cujo diagnóstico era “ICH”, 54 morreram e 25 não morreram no período de tempo considerado. Esses valores são obtidos, contando-se no conjunto de dados quantos pacientes que possuem o diagnóstico de hemorragia intracranial vieram ou não a óbito, respectivamente. A tabela com as porcentagens nas linhas mostra que, dos 79 pacientes com diagnóstico “ICH”, 31,6% (25) não morreram e 68,4% (54) morreram. Interpretação análoga se aplica às demais linhas da tabela.
2.3.2.2 Obtendo os percentuais de cada célula em relação ao total da coluna correspondente
Se, na aba Estatísticas para gerar uma tabela de dupla entrada, marcarmos a opção percentual nas colunas (figura 2.14), a tabela de dupla entrada irá mostrar os percentuais de cada célula em relação ao total da coluna correspondente.
Figura 2.14: Tela para especificar que a tabela de dupla entrada irá mostrar os percentuais de cada célula em relação ao total da coluna correspondente à célula.
Ao clicarmos em OK, os comandos a seguir serão executados, com os resultados mostrados logo após.
local({
.Table <- xtabs(~dgn+dead, data=stroke)
cat("\nFrequency table:\n")
print(.Table)
cat("\nColumn percentages:\n")
print(colPercents(.Table))
})##
## Frequency table:
## dead
## dgn FALSE TRUE
## ICH 25 54
## ID 54 148
## INF 239 262
## SAH 26 21
##
## Column percentages:
## dead
## dgn FALSE TRUE
## ICH 7.3 11.1
## ID 15.7 30.5
## INF 69.5 54.0
## SAH 7.6 4.3
## Total 100.1 99.9
## Count 344.0 485.0A função colPercents, do pacote RcmdrMisc, gera os percentuais de cada célula em relação ao total da coluna correspondente.
Assim a tabela de frequência mostra novamente que, dos 79 pacientes cujo diagnóstico era “ICH”, 54 morreram e 25 não morreram no período de tempo considerado. A tabela com as porcentagens nas colunas mostra que, dos 344 pacientes que não morreram, 7,3% (25) tiveram o diagnóstico “ICH”, e dos 485 que morreram, 11,1% (54) tiveram o diagnóstico “ICH”. Interpretação análoga se aplica às demais linhas da tabela.
2.3.2.3 Obtendo os percentuais de cada célula em relação ao total da tabela
Se, na aba Estatísticas para gerar uma tabela de dupla entrada, marcarmos a opção percentagens do total (figura 2.15), a tabela de dupla entrada irá mostrar os percentuais de cada célula em relação ao total da tabela.
Figura 2.15: Tela para especificar que a tabela de dupla entrada irá mostrar os percentuais de cada célula em relação ao total da tabela.
Ao clicarmos em OK, os comandos abaixo serão executados, com os resultados mostrados logo a seguir.
local({
.Table <- xtabs(~dgn+dead, data=stroke)
cat("\nFrequency table:\n")
print(.Table)
cat("\nTotal percentages:\n")
print(totPercents(.Table))
})##
## Frequency table:
## dead
## dgn FALSE TRUE
## ICH 25 54
## ID 54 148
## INF 239 262
## SAH 26 21
##
## Total percentages:
## FALSE TRUE Total
## ICH 3.0 6.5 9.5
## ID 6.5 17.9 24.4
## INF 28.8 31.6 60.4
## SAH 3.1 2.5 5.7
## Total 41.5 58.5 100.0A função totPercents, do pacote RcmdrMisc, gera os percentuais de cada célula em relação ao total da tabela.
Assim a tabela de frequência mostra que 54 pacientes cujo diagnóstico era “ICH” morreram. A tabela com as porcentagens de cada célula mostra que, do total de 829 pacientes, 6,5% (54) tiveram o diagnóstico “ICH” e morreram. Interpretação análoga se aplica às demais células da tabela.
2.3.3 Tabelas de frequência para mais de duas variáveis categóricas
Para gerar tabelas de frequências ou porcentagens para combinação das categorias de três ou mais variáveis categóricas no R Commander, usamos a opção:
\[\text{Estatísticas} \Rightarrow \text{Tabelas de contingência} \Rightarrow \text{Tabela multientrada...}\]
Esse tipo de tabela é chamada também de tabela de múltiplas entradas (por envolver mais de duas variáveis).
Na tela dessa opção (figura 2.16), selecionamos uma variável cujas categorias irão aparecer nas linhas da tabela, outra variável cujas categorias irão aparecer nas colunas da tabela e outra(s) variável(is) (chamadas de variáveis de controle no R Commander) para as quais desejamos a distribuição conjunta de frequências. Nesse exemplo, selecionamos a variável dgn (diagnóstico) para as linhas, dead para as colunas e minf (história de infarto do miocárdio) para a variável de controle. Também selecionamos a opção de mostrar os percentuais de cada célula na linha correspondente da tabela.
Figura 2.16: Tela para a seleção das variáveis categóricas que comporão a tabela multientrada com três variáveis.
Ao clicarmos em OK, a sequência de comandos abaixo será executada e os resultados mostrados a seguir.
local({
.Table <- xtabs(~dgn+dead+minf, data=stroke)
cat("\nFrequency table:\n")
print(.Table)
cat("\nRow percentages:\n")
print(rowPercents(.Table))
})##
## Frequency table:
## , , minf = No
##
## dead
## dgn FALSE TRUE
## ICH 25 46
## ID 49 131
## INF 222 207
## SAH 24 21
##
## , , minf = Yes
##
## dead
## dgn FALSE TRUE
## ICH 0 8
## ID 4 12
## INF 17 54
## SAH 2 0
##
##
## Row percentages:
## , , minf = No
##
## dead
## dgn FALSE TRUE Total Count
## ICH 35.2 64.8 100 71
## ID 27.2 72.8 100 180
## INF 51.7 48.3 100 429
## SAH 53.3 46.7 100 45
##
## , , minf = Yes
##
## dead
## dgn FALSE TRUE Total Count
## ICH 0.0 100.0 100 8
## ID 25.0 75.0 100 16
## INF 23.9 76.1 100 71
## SAH 100.0 0.0 100 2Uma tabela de frequências de dupla entrada (com as variáveis dgn e dead) é construída para cada categoria da variável minf e as porcentagens nas linhas são calculadas para cada uma das tabelas separadamente. Na função xtabs, a primeira variável após o “~” é aquela cujas categorias aparecerão nas linhas de cada tabela, a segunda variável após o “~” é aquela cujas categorias aparecerão nas colunas de cada tabela. Uma tabela de frequências será construída com as duas primeiras variáveis para cada categoria da terceira variável.
Se desejássemos os percentuais nas colunas, bastaria selecionar a opção correspondente na figura 2.16.
Podemos selecionar mais de três variáveis para montar uma tabela de múltiplas entradas. Na tela mostrada na figura 2.17, selecionamos quatro variáveis: dgn para as linhas, dead para as colunas, diab (história de diabetes) e minf (história de infarto do miocárdio) para as variáveis de controle. Dessa vez, foi selecionada a opção de mostrar os percentuais de cada célula na coluna correspondente da tabela. Uma tabela será construída para cada combinação das categorais das variáveis diab e minf. Nesse caso, serão mostradas quatro tabelas.
Figura 2.17: Tela para a seleção das variáveis categóricas que comporão a tabela multientrada com quatro variáveis.
Ao clicarmos em OK, a sequência de comandos abaixo será executada e os resultados mostrados em seguida.
local({
.Table <- xtabs(~dgn+dead+diab+minf, data=stroke)
cat("\nFrequency table:\n")
print(.Table)
cat("\nColumn percentages:\n")
print(colPercents(.Table))
})##
## Frequency table:
## , , diab = No, minf = No
##
## dead
## dgn FALSE TRUE
## ICH 23 43
## ID 39 114
## INF 203 171
## SAH 24 21
##
## , , diab = Yes, minf = No
##
## dead
## dgn FALSE TRUE
## ICH 2 3
## ID 10 14
## INF 19 35
## SAH 0 0
##
## , , diab = No, minf = Yes
##
## dead
## dgn FALSE TRUE
## ICH 0 6
## ID 4 12
## INF 13 46
## SAH 2 0
##
## , , diab = Yes, minf = Yes
##
## dead
## dgn FALSE TRUE
## ICH 0 2
## ID 0 0
## INF 4 8
## SAH 0 0
##
##
## Column percentages:
## , , diab = No, minf = No
##
## dead
## dgn FALSE TRUE
## ICH 8.0 12.3
## ID 13.5 32.7
## INF 70.2 49.0
## SAH 8.3 6.0
## Total 100.0 100.0
## Count 289.0 349.0
##
## , , diab = Yes, minf = No
##
## dead
## dgn FALSE TRUE
## ICH 6.5 5.8
## ID 32.3 26.9
## INF 61.3 67.3
## SAH 0.0 0.0
## Total 100.1 100.0
## Count 31.0 52.0
##
## , , diab = No, minf = Yes
##
## dead
## dgn FALSE TRUE
## ICH 0.0 9.4
## ID 21.1 18.8
## INF 68.4 71.9
## SAH 10.5 0.0
## Total 100.0 100.1
## Count 19.0 64.0
##
## , , diab = Yes, minf = Yes
##
## dead
## dgn FALSE TRUE
## ICH 0 20
## ID 0 0
## INF 100 80
## SAH 0 0
## Total 100 100
## Count 4 102.3.3.1 Forma alternativa de apresentar tabelas de frequência para mais de duas variáveis categóricas
Vimos na seção anterior que a função xtabs (assim como a função table) irá apresentar, para mais de duas variáveis, tantas tabelas quantas forem as combinações possíveis das categorias das variáveis de controle (variáveis após a segunda na fórmula ou na lista de variáveis).
Existe uma outra forma de apresentar os resultados da distribuição de frequências conjuntas, por meio da função ftable.
Se quisermos obter a distribuição de frequências conjuntas das variáveis dgn, dead e minf, com dgn nas linhas, usamos o comando a seguir.
## minf No Yes
## dead FALSE TRUE FALSE TRUE
## dgn
## ICH 25 46 0 8
## ID 49 131 4 12
## INF 222 207 17 54
## SAH 24 21 2 0As variáveis após o “~” serão mostradas nas linhas e aquelas antes do “~” serão mostradas nas colunas. Nesse exemplo, uma tabela relacionando dgn com dead será mostrada para a categoria No de minf ao lado de outra tabela relacionando dgn com dead para a categoria Yes de minf.
Se colocarmos dead antes de minf na fórmula, como no comando a seguir, uma tabela relacionando dgn com minf será mostrada para a categoria FALSE de dead ao lado de outra tabela relacionando dgn com minf para a categoria TRUE de dead.
## dead FALSE TRUE
## minf No Yes No Yes
## dgn
## ICH 25 0 46 8
## ID 49 4 131 12
## INF 222 17 207 54
## SAH 24 2 21 0Para obtermos as proporções de cada célula em relação ao total da linha correspondente, podemos utilizar a função prop.table, especificando como primeiro argumento o objeto correspondente à tabela que estamos trabalhando (gerado pela função ftable) e, como segundo argumento, o valor 1, que indica a primeira dimensão da tabela.
## dead FALSE TRUE
## minf No Yes No Yes
## dgn
## ICH 0.31645570 0.00000000 0.58227848 0.10126582
## ID 0.25000000 0.02040816 0.66836735 0.06122449
## INF 0.44400000 0.03400000 0.41400000 0.10800000
## SAH 0.51063830 0.04255319 0.44680851 0.00000000Para expressar as proporções como porcentagens, basta multiplicar os resultados por 100 como mostrado a seguir.
## dead FALSE TRUE
## minf No Yes No Yes
## dgn
## ICH 31.645570 0.000000 58.227848 10.126582
## ID 25.000000 2.040816 66.836735 6.122449
## INF 44.400000 3.400000 41.400000 10.800000
## SAH 51.063830 4.255319 44.680851 0.000000Para obtermos as proporções de cada célula em relação ao total da coluna correspondente, utilizamos a função prop.table, especificando como segundo argumento o valor 2, que indica a segunda dimensão da tabela.
## dead FALSE TRUE
## minf No Yes No Yes
## dgn
## ICH 0.07812500 0.00000000 0.11358025 0.10810811
## ID 0.15312500 0.17391304 0.32345679 0.16216216
## INF 0.69375000 0.73913043 0.51111111 0.72972973
## SAH 0.07500000 0.08695652 0.05185185 0.00000000O comando abaixo mostra a função ftable com quatro variáveis, sendo as categorias de dgn mostradas nas linhas.
## diab No Yes
## minf No Yes No Yes
## dead FALSE TRUE FALSE TRUE FALSE TRUE FALSE TRUE
## dgn
## ICH 23 43 0 6 2 3 0 2
## ID 39 114 4 12 10 14 0 0
## INF 203 171 13 46 19 35 4 8
## SAH 24 21 2 0 0 0 0 0O comando a seguir mostra a função ftable com quatro variáveis, sendo as categorias de dgn e diab mostradas nas linhas. Observem a flexibilidade nos arranjos das tabelas, de acordo com a posição das variáveis (antes e depois do “~”) e da ordem em que elas são colocadas.
## minf No Yes
## dead FALSE TRUE FALSE TRUE
## dgn diab
## ICH No 23 43 0 6
## Yes 2 3 0 2
## ID No 39 114 4 12
## Yes 10 14 0 0
## INF No 203 171 13 46
## Yes 19 35 4 8
## SAH No 24 21 2 0
## Yes 0 0 0 02.3.4 Entrando diretamente com as frequências das células
Às vezes, temos disponível uma tabela de frequências já construída, por exemplo, publicada em artigos científicos ou relatórios técnicos e desejamos obter as proporções ou percentuais nas linhas ou colunas e realizar alguma análise estatística.
A opção a seguir nos permite digitar as frequências de cada célula de uma tabela de dupla entrada no R Commander e obter os percentuais nas linhas, colunas ou células, além de realizar um teste estatístico de associação entre as duas variáveis:
\[\text{Estatísticas} \Rightarrow \text{Tabelas de contingência} \Rightarrow \text{Digite e analise tabela dupla entrada...}\]
Na aba Tabela dessa opção (figura 2.18), podemos escrever os nomes para as variáveis cujas categorias irão aparecer nas linhas e colunas da tabela, selecionar o número de categorias nas linhas e colunas e digitar os valores das células da tabela de dupla entrada. Nesse exemplo, reproduzimos a tabela de frequências conjuntas das variáveis dgn (diagnóstico) para as linhas e dead para as colunas (seção 2.3.2). Na aba Estatísticas (não mostrada aqui), selecionamos a opção Percentuais nas linhas e desmarcamos a opção Teste de independência de Qui-Quadrado, porque esse teste será visto com detalhes no capítulo 17.
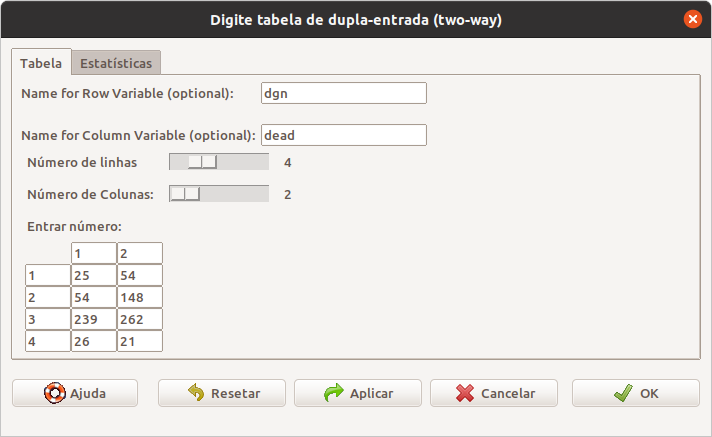
Figura 2.18: Tela para a digitação das frequências das células que comporão uma tabela de dupla entrada.
Ao clicarmos em OK, a sequência de comandos a seguir será executada e os resultados mostrados logo após.
.Table <- matrix(c(25,54,54,148,239,262,26,21), 4, 2, byrow=TRUE)
dimnames(.Table) <- list("dgn"=c("1", "2", "3", "4"), "dead"=c("1", "2"))
.Table # Counts## dead
## dgn 1 2
## 1 25 54
## 2 54 148
## 3 239 262
## 4 26 21## dead
## dgn 1 2 Total Count
## 1 31.6 68.4 100 79
## 2 26.7 73.3 100 202
## 3 47.7 52.3 100 501
## 4 55.3 44.7 100 47Observamos que os resultados são idênticos aos mostrados na seção 2.3.2, porém os nomes das categorias nas linhas e colunas aparecem como números.
A tabela foi construída por meio da função matrix. Podemos tornar os nomes das categorias mais descritivos por meio das funções colnames e rownames aplicadas ao objeto que representa a tabela gerada (.Table), como mostrado a seguir.
## dead
## dgn Não Sim
## ICH 25 54
## ID 54 148
## INF 239 262
## SAH 26 21Podemos alterar os nomes das dimensões da tabela para valores mais descritivos, usando a função names, como mostrado a seguir.
## morte
## diagnóstico Não Sim
## ICH 25 54
## ID 54 148
## INF 239 262
## SAH 26 21Poderíamos combinar os comandos anteriores (colnames, rownames e names) em um único comando, como mostrado a seguir.
## morte
## diagnóstico Não Sim
## ICH 25 54
## ID 54 148
## INF 239 262
## SAH 26 21Se quisermos trocar as linhas pelas colunas na tabela de frequência, podemos usar a função t (de transposta), como mostra o comando a seguir.
## diagnóstico
## morte ICH ID INF SAH
## Não 25 54 239 26
## Sim 54 148 262 212.4 Exercício
Carregue o conjunto de dados births14 do pacote openintro (GPL-3). Para abrir esse conjunto de dados, é necessário que o pacote openintro esteja instalado. Responda às questões abaixo.
- Abra a ajuda desse conjunto de dados e verifique o significado das suas variáveis.
- Monte tabelas de frequências e de porcentagens para as variáveis lowbirthweight, whitemom e habit.
- Monte uma tabela de contingência relacionando as variáveis habit e lowbirthweight. Quais são as porcentagens de baixo peso ao nascer para fumantes e não fumantes?
- Monte uma tabela de contingência relacionando as variáveis habit e lowbirthweight para cada nível da variável whitemom com porcentagens obtidas a partir das linhas. Comente os resultados.