4 Visualização de dados
Uma introdução sobre diversos diagramas que são frequentemente utilizados para explorar os dados de um conjunto de dados pode ser visualizada neste vídeo.
Os dois capítulos anteriores deram início à exploração de dados com as tabelas de frequência e as medidas de tendência central e de dispersão. Neste capítulo, serão abordados alguns recursos gráficos para visualizar a distribuição dos valores das variáveis de um determinado conjunto de dados. Os diagramas que serão abordados são:
diagrama de barras
diagrama de setores (pizza ou torta)
diagrama de caixa (boxplot)
histograma
histograma de densidade de frequência
diagrama de pontos
diagrama de strip chart
diagrama de dispersão
Os dois primeiros diagramas (barras e tortas) são utilizados para indicar a contagem (frequência) ou proporção de cada categoria de uma variável categórica. Os demais são utilizados para variáveis numéricas.
A figura 4.1 é um dos resultados do estudo de Furuta et al. (Furuta, Weckx, and Figueiredo 2003), que consistiu de um estudo clínico randomizado duplo-cego em crianças com adenoide obstrutiva submetidas a tratamento homeopático. Ela mostra um diagrama de barras das frequências dos tratamentos de acordo com a evolução, considerando a avaliação nasofibroscópica.
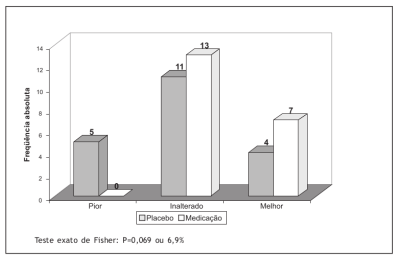
Figura 4.1: Diagrama de barras das frequências dos tratamentos segundo a evolução dos pacientes de acordo com a avaliação nasofibroscópica inicial e final. Fonte: (Furuta, Weckx, and Figueiredo 2003) (CC BY-NC).
As figuras 4.2 e 4.3 apresentam os diagramas de pizza mostrando o percentual de cada uma das categorias da evolução de acordo com a avaliação nasofibroscópica inicial e final para os tratamentos homeopático (figura 4.2) e para o placebo (figura 4.3). O percentual de inalterado no tratamento homeopático foi de 65%, enquanto que, no placebo, ele foi de 55%. Nenhum paciente teve uma piora na homeopatia e 25% teve um piora no grupo placebo. Finalmente 35% por cento tiveram uma melhora com o tratamento homeopático versus 20% com o placebo.
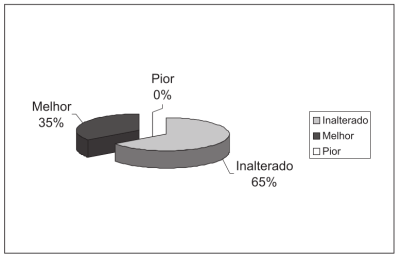
Figura 4.2: Diagrama de pizza da evolução dos pacientes do grupo I (medicamento homeopático), comparando as nasofibroscopias inicial e final do tratamento. Fonte: (Furuta, Weckx, and Figueiredo 2003) (CC BY-NC).
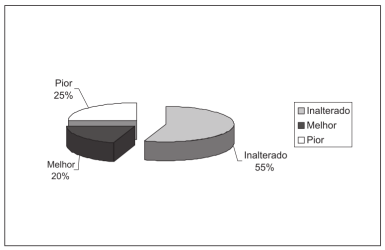
Figura 4.3: Diagrama de pizza da evolução dos pacientes do grupo II (placebo), comparando as nasofibroscopias inicial e final do tratamento. Fonte: (Furuta, Weckx, and Figueiredo 2003) (CC BY-NC).
Os dois diagramas de pizza (figuras 4.2 e 4.3) fornecem em conjunto a mesma informação que o diagrama de barras (figura 4.1) de que o tratamento homeopático tem o melhor desempenho do que o placebo em relação à avaliação nasofibroscópica, porém a análise estatística mostrou que essas diferenças não foram estatisticamente significativas ao nível de 5%.
O boxplot é utilizado para verificar a distribuição dos valores de uma variável numérica. A figura 4.4 apresenta diagramas de boxplot da contagem de diversos marcadores imunológicos em pacientes com a pele exposta à radiação ultravioleta (em vermelho) ou coberta (em azul). O diagrama sugere que as contagens dos marcadores CD45 e CD68 assim como o número de mastócitos ATM são maiores nos indivíduos expostos do que nos indivíduos não expostos à radiação ultra-violeta.
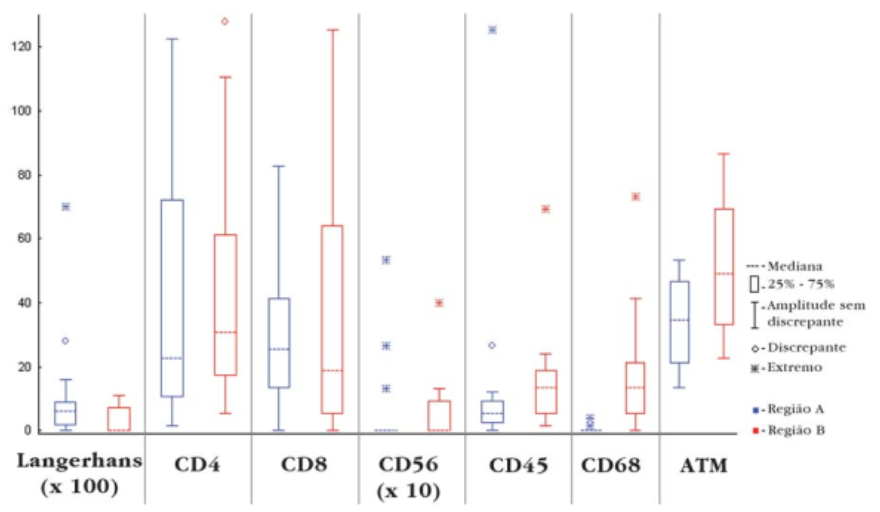
Figura 4.4: Boxplots dos marcadores imunológicos em pele coberta e exposta. Fonte: (Bezerra et al. 2011) (CC BY-NC).
A figura 4.5 mostra quatro gráficos de pontos dos níveis séricos das citocinas TNF-fator de necrose tumoral, interleucina-6, interleucina 8 assim como da RANTES (CCL5) para os seguintes grupos de pacientes: controles saudáveis, pacientes com DPOC (Doença Pulmonar Obstrutiva Crônica) e limitação do fluxo aéreo não reversível e pacientes com DPOC e limitação ao fluxo aéreo parcialmente reversível. O diagrama de pontos também é utilizado para verificar a distribuição dos valores de uma variável numérica.
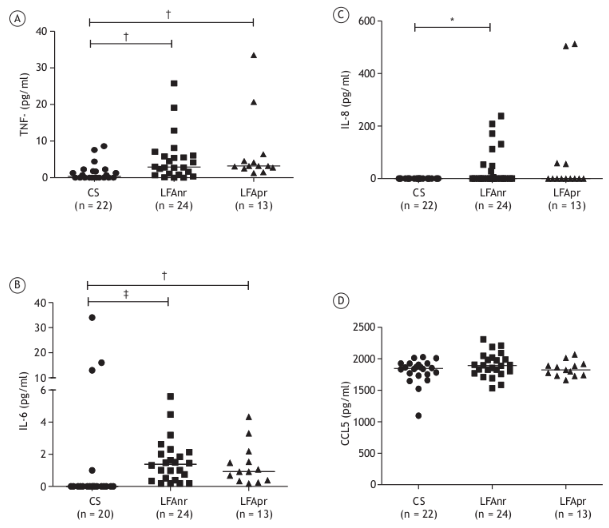
Figura 4.5: Gráfico de pontos dos níveis séricos das citocinas TNF (A), IL-6 (B) e IL-8 (C), assim como da RANTES (CCL5; D), em controles saudáveis (CS), pacientes com DPOC e limitação ao fluxo aéreo não reversível (LFAnr) e pacientes com DPOC e limitação ao fluxo aéreo parcialmente reversível (LFApr). Fonte: (Queiroz et al. 106AD) (CC BY-NC).
A figura 4.6 mostra um histograma do escore SYNTAX em pacientes com doença arterial coronariana multiarterial com indicação de intervenção coronária percutânea eletiva ou na vigência de síndrome coronariana aguda sem elevação do segmento ST com stents farmacológicos de primeira ou segunda gerações. O escore SYNTAX permite a estratificação do paciente quanto à complexidade angiográfica das lesões coronarianas.
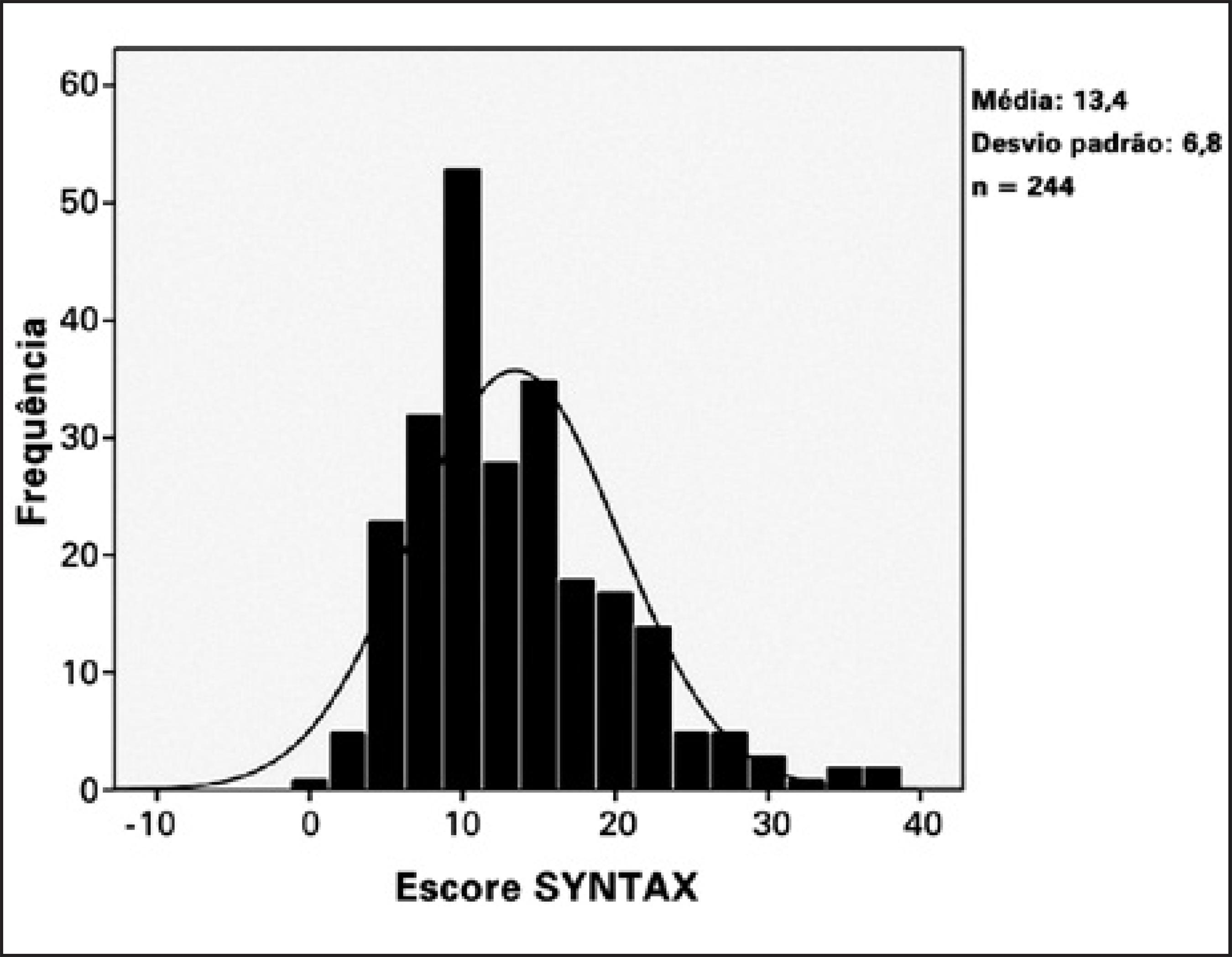
Figura 4.6: Histograma do escore SYNTAX em pacientes com doença arterial coronariana multiarterial. Fonte: (Silva et al. 2014) (CC BY-NC).
A figura 4.7 mostra um diagrama de dispersão ou espalhamento da relação fração de ejeção do ventrículo esquerdo versus relação neutrófilo-linfócito. Cada ponto corresponde aos valores da relação neutrófilo-linfócito na abscissa e a fração de ejeção do ventrículo esquerdo na ordenada para cada paciente do estudo. Esse gráfico sugere que a fração de ejeção do ventrículo esquerdo tende a diminuir à medida que a relação neutrófilo-linfócito aumenta e os autores apresentaram no gráfico a reta que melhor se ajusta a esses pontos.
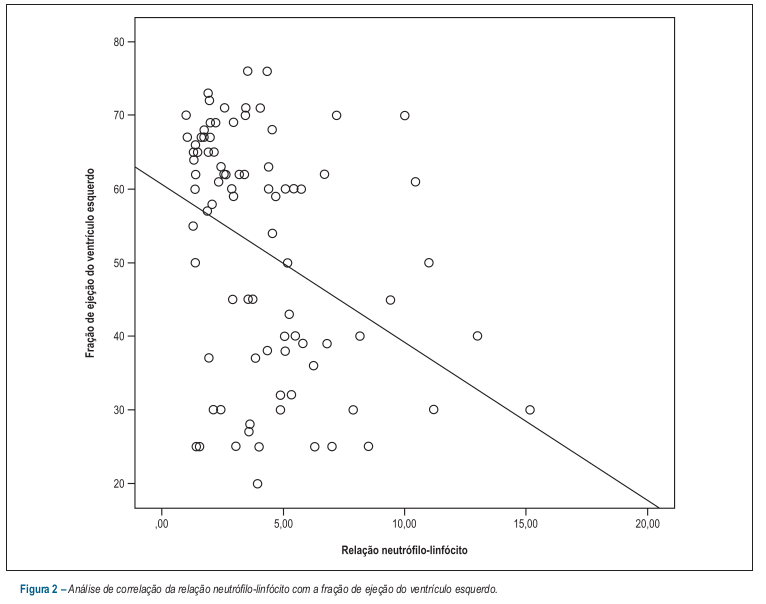
Figura 4.7: Diagrama de dispersão da relação neutrófilo-linfócito versus fração de ejeção do ventrículo esquerdo. Fonte: (Durmus et al. 2015) (CC BY).
Vamos utilizar neste capítulo o R Commander, carregado a partir do RStudio, mas também poderíamos utilizar o R Commander, carregado a partir da tela de entrada do R. Para a construção dos diagramas, vamos utilizar o conjunto de dados juul2, após a conversão das variáveis sex, menarche e tanner de numéricas para categóricas (fator).
Inicialmente, vamos executar o RStudio.
Em seguida, digitamos os comandos abaixo na console do RStudio e pressionamos a tecla Enter (figura 4.8).
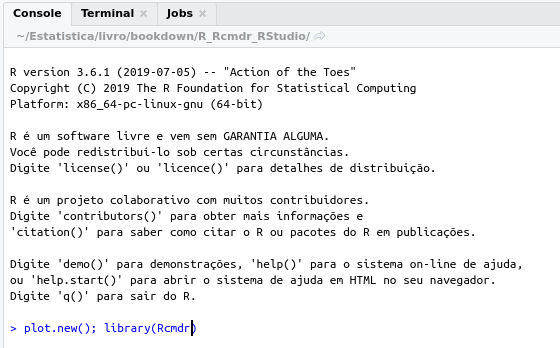
Figura 4.8: Console do RStudio, após a digitação dos comandos para carregar o pacote Rcmdr.
Observação: A função plot.new(), é executada antes do carregamento do R Commander para garantir que os gráficos gerados pelo R Commander sejam mostrados na interface do RStudio. Caso ela (ou alguma função que gere um gráfico no RStudio) não seja executada antes do carregamento do R Commander, os gráficos gerados pelo R Commander serão exibidos em uma janela separada.
4.1 Convertendo uma variável numérica para fator
O conteúdo desta seção pode ser visualizado neste vídeo.
No R Commander, vamos carregar o pacote ISwR (GPL-2 | GPL-3) e, em seguida, o conjunto de dados juul2 (seção 3.6.1).
Para analisarmos e visualizarmos as variáveis categóricas corretamente no R, elas têm que serem da classe factor (fator), outro nome utilizado em análises estatísticas para variáveis categóricas. Vamos nesta seção converter as variáveis tanner, sex e menarche para fator, porque elas estão codificadas no conjunto de dados como números. A seguir, será mostrado o passo a passo para converter a variável tanner para fator, usando o R Commander.
Para realizarmos a conversão de uma variável numérica em fator no R Commander, selecionamos a opção:
\[\text{Dados} \Rightarrow \text{Modificação var. conj. dados} \Rightarrow\ \text{Converter var. numérica para fator}\]
Na tela Converter Variáveis Numéricas p/ Fator (figura 4.9), selecionamos a variável que será convertida e escolhemos uma das opções: manter as categorias expressas como números, ou fornecer nomes às categorias. Vamos dar nomes às categorias neste exemplo. Na caixa de texto, digitamos o nome da variável que será criada. Se nenhum nome for especificado nessa caixa, os nomes serão sobrescritos aos valores numéricos na própria variável que será convertida e não será criada uma nova variável.
Figura 4.9: Passos para criar as categorias de uma variável: selecionamos a variável na lista da esquerda, escolhemos se as categorias serão dadas como texto e fornecemos o nome da nova variável. Clicamos em OK.
Como selecionamos a opção de fornecer os nomes para as categorias, ao clicarmos em OK na figura 4.9, uma nova tela aparece para darmos os nomes das categorias para cada valor numérico (figura 4.10). Finalmente, ao clicarmos em OK, a nova variável, tanner_cat, será criada com as categorias apropriadas.
Figura 4.10: Especificação das categorias para a variável tanner.
O comando executado é mostrado a seguir:
juul2 <- within(juul2, {
tanner_cat <- factor(tanner,
labels=c('Tanner I','Tanner II','Tanner III','Tanner IV','Tanner V'))
})Vamos entender como essa conversão foi efetuada. A função factor converte a variável expressa pelo primeiro argumento da função em fator. O argumento labels define os rótulos para cada valor da variável que será convertida. A função c cria um vetor com os rótulos que serão atribuídos aos números 1 a 5, na sequência.
A função within nesse exemplo possui dois argumentos: o conjunto de dados juul2 e a expressão que será executada no primeiro argumento. Essa expressão aparece entre {}. Assim a função factor vai operar sobre variáveis do conjunto de dados juul2 e, após a conversão, a variável resultante (tanner_cat) será incorporada ao próprio juul2. Poderíamos criar um outro conjunto de dados, bastando mudar o nome do objeto antes do sinal de atribuição (<-).
Observem os registros do conjunto de dados após a recodificação e a classe da variável tanner_cat, usando a função class conforme a seguir:
## [1] "factor"Repitam o procedimento acima para a variável sex, criando uma nova variável, sexo_cat, com a conversão abaixo:
1 - masculino
2 - feminino
O comando para a conversão da variável sex para fator é mostrado a seguir:
Repitam o procedimento acima para a variável menarche, criando uma nova variável, menarca_cat, com a conversão abaixo:
1 - não
2 - sim
O comando para a conversão da variável menarche é mostrado a seguir:
4.2 Diagrama de barras
O conteúdo desta seção pode ser visualizado neste vídeo.
As variáveis categóricas nominais ou ordinais podem ser visualizadas graficamente por diagramas que fornecem as contagem (frequência) ou a proporção (ou porcentagem) de cada categoria da variável no conjunto de dados. Um dos diagramas mais utilizados com essa finalidade é o diagrama de barras, o qual mostra para cada categoria uma barra com altura proporcional à frequência ou proporção da respectiva categoria. Para criar um diagrama de barras no R Commander, selecionamos a opção:
\[\text{Gráficos} \Rightarrow \text{Gráfico de barras}\]
Na aba Dados da caixa de diálogo Gráfico de Barras, é possível selecionar a variável categórica desejada. Nesse exemplo, vamos criar um diagrama de barras para a variável categórica tanner_cat (figura 4.11). Na aba Opções dessa caixa de diálogo (figura 4.12), é possível especificar a escala do eixo Y (porcentagem ou frequência), selecionar a cor e a posição das legendas, especificar as legendas dos eixos X e Y e o título do gráfico e selecionar se as frequências ou porcentagens serão exibidas nas barras. As demais opções serão discutidas logo adiante. Ao clicarmos em OK, o gráfico será exibido na aba Plots do RStudio (figura 4.13), mostrando a frequência de cada barra. Se utilizarmos o R Commander, carregado a partir do R, o gráfico será exibido em uma outra janela ou na janela do R.
Figura 4.11: Caixa de diálogo para a geração de um diagrama de barras: selecionando a variável.
Figura 4.12: Caixa de diálogo para a geração de um diagrama de barras: especificando o título do gráfico e as legendas dos eixos X e Y.
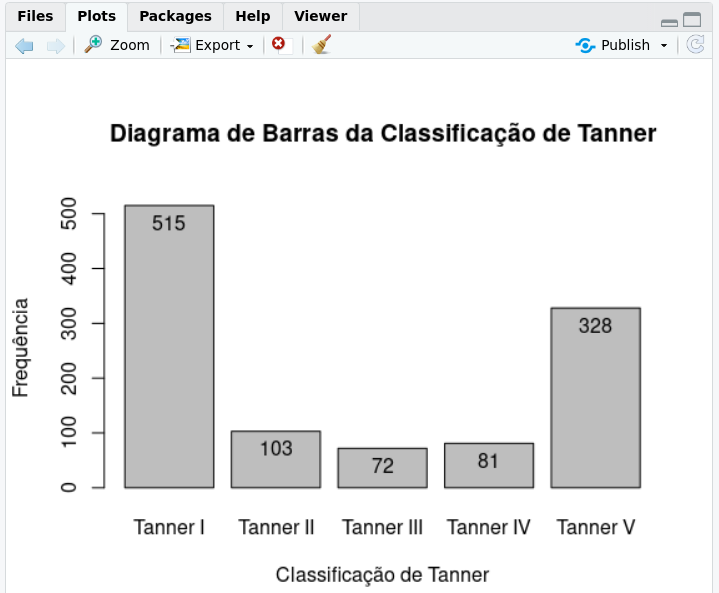
Figura 4.13: Diagrama de barras para a variável tanner_cat. São mostradas as frequências de cada categoria de Tanner.
O gráfico da figura 4.13 mostra as frequências de cada uma das cinco categorias da classificação de Tanner no conjunto de dados juul2. A categoria I é a mais frequente, seguida da categoria V. As categorias II, III e IV apresentam frequências próximas umas das outras, mas com frequências bem menores do que as categorias I e V.
Caso desejemos visualizar o diagrama de barras da variável sexo_cat separadamente para cada categoria de Tanner, precisamos selecionar sexo_cat como uma variável de agrupamento. Para isso, clicamos na opção Gráfico por grupos na figura 4.11. Seremos, então, apresentados à caixa de diálogo da figura 4.14, onde selecionamos a variável de agrupamento (sexo_cat). Ao clicarmos em OK, voltamos à tela da figura 4.11.
Clicando na aba Opções, mostrada novamente na figura 4.15, podemos, em Estilo de barras agrupadas, escolher entre duas opções de como o diagrama de barras será construído: barras de cada categoria da variável sexo_cat empilhadas (particionada) para cada categoria da variável tanner_cat, ou lado a lado. Selecionando a segunda opção e clicando em OK, será plotado o gráfico da figura 4.16. Ao selecionarmos a primeira opção, obteremos o gráfico da figura 4.17, onde desmarcamos a opção Show counts or percentages in bars na figura 4.15.
Ambos os gráficos mostram que há uma predominância de homens nas categorias I, II e IV (especialmente na I), e mais mulheres nas categorias III e V (principalmente na V). Para cada sexo, as frequências de cada categoria de Tanner seguem o padrão mostrado na figura 4.13.
Figura 4.14: Selecionando uma variável de agrupamento para o diagrama de barras das frequências das categorias da variável sexo_cat para cada categoria da classificação de Tanner.
Figura 4.15: Selecionando a forma como as barras serão apresentadas (lado a lado ou empilhadas). Neste exemplo, foi selecionada a opção lado a lado.
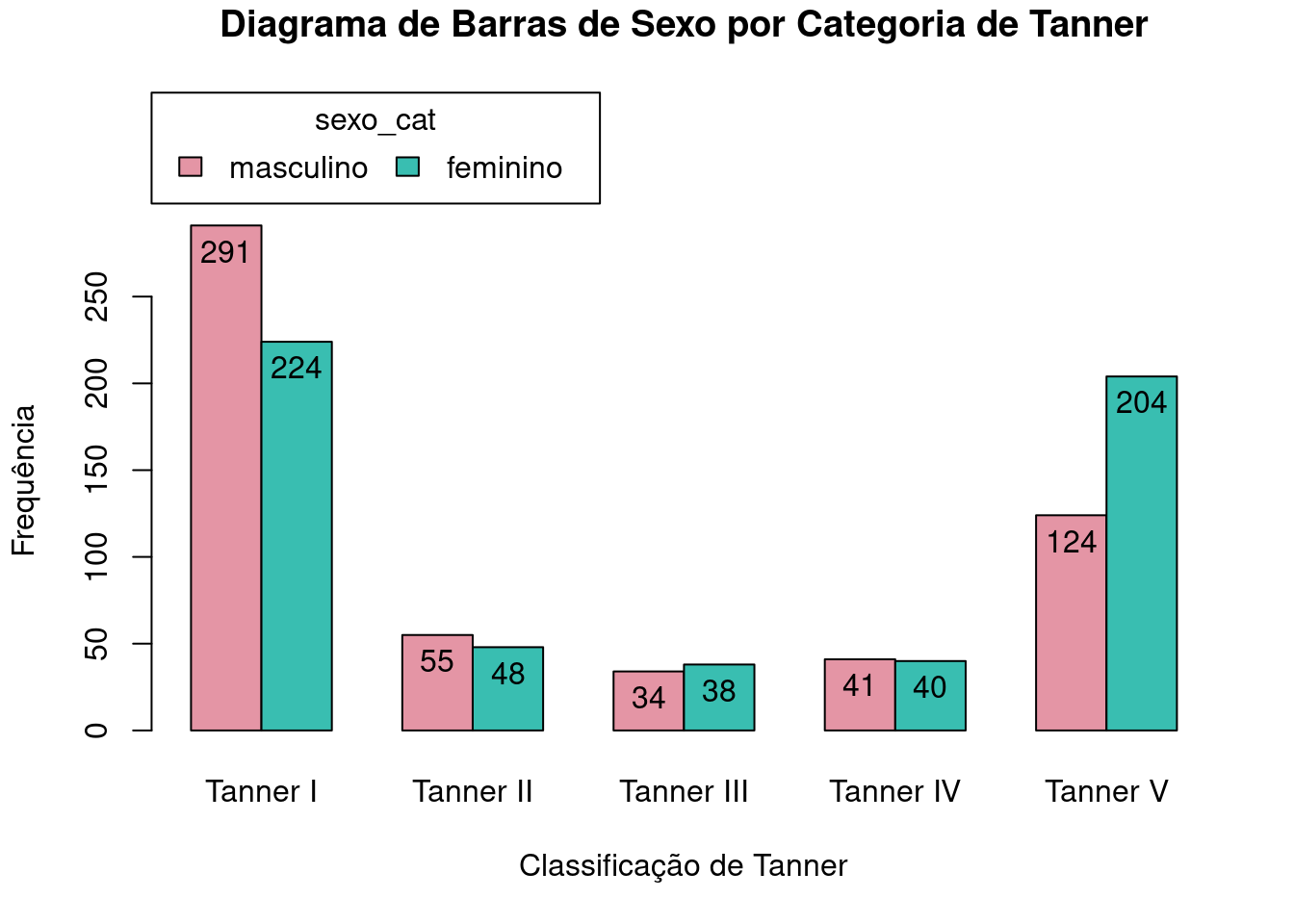
Figura 4.16: Diagrama de barras lado a lado das frequências das categorias da variável sexo_cat para cada categoria da variável tanner_cat.
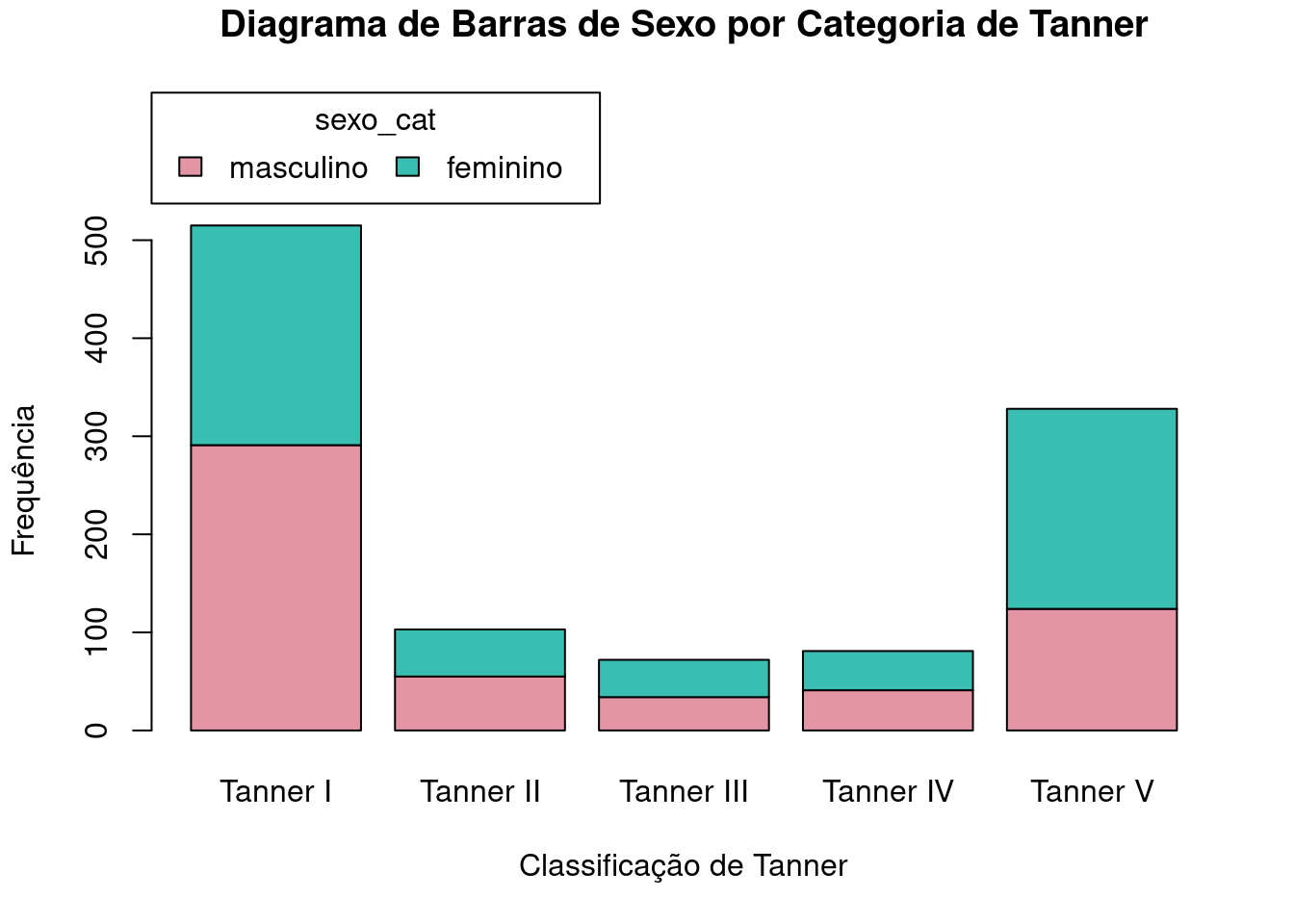
Figura 4.17: Diagrama de barras empilhadas das frequências das categorias da variável sexo_cat para cada categoria da variável tanner_cat.
Vamos supor que queiramos criar um diagrama de barras com percentuais de cada categoria, em vez de frequências. Na caixa de diálogo de opções do comando para a geração de um diagrama de barras, selecionamos as opções como mostrado na figura 4.18. Observem que foram selecionadas as opções Percentagens em Escala do eixo, e Total em Percentages for Group Bars.
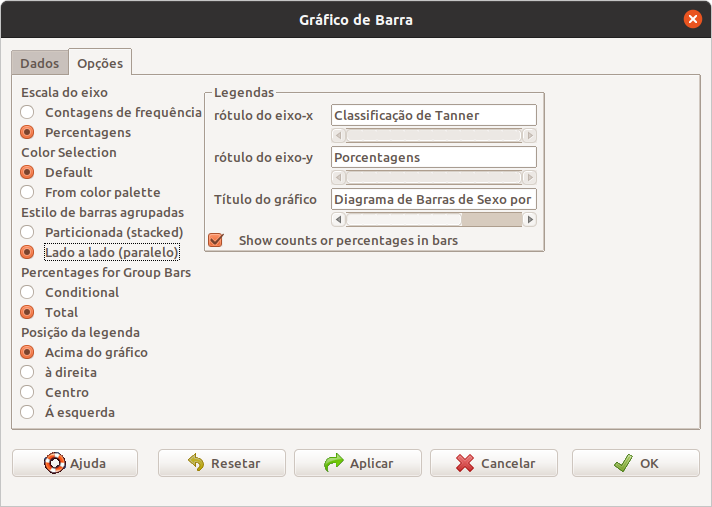
Figura 4.18: Configuração para gerar um diagrama de barras com percentagens do total para as categorias da variável sexo_cat para cada categoria da variável tanner_cat.
O comando gerado pelo R Commander é mostrado abaixo e o gráfico é apresentado na figura 4.19. Para cada categoria de Tanner, as barras mostram o percentual do total de observações para cada sexo naquela categoria. A soma de todos os percentuais é igual a 100%.
with(juul2, Barplot(tanner_cat, by=sexo_cat, style="parallel",
legend.pos="above", xlab="Classificação de Tanner",
ylab="Porcentagens", conditional=FALSE, label.bars=TRUE,
main="Diagrama de Barras de Sexo por Categoria de Tanner",
scale="percent"))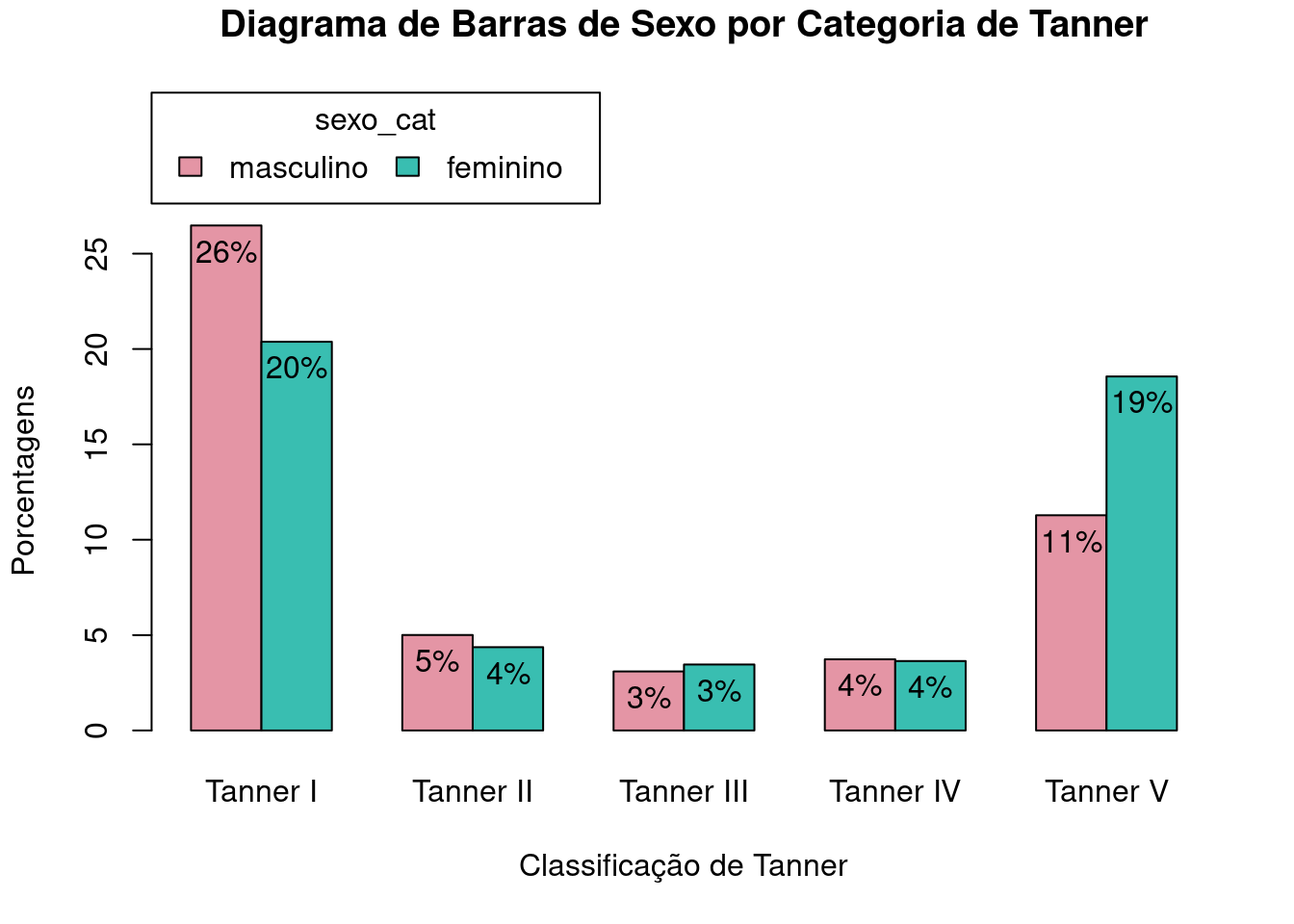
Figura 4.19: Diagrama de barras lado a lado para as porcentagens do total de observações de cada categoria de sexo_cat por categoria da variável tanner_cat.
Caso tivéssemos selecionado a opção Conditional em Percentages for Group Bars na figura 4.18, obteríamos o diagrama da figura 4.20. Em cada categoria de Tanner, os percentuais de cada sexo somam 100%.
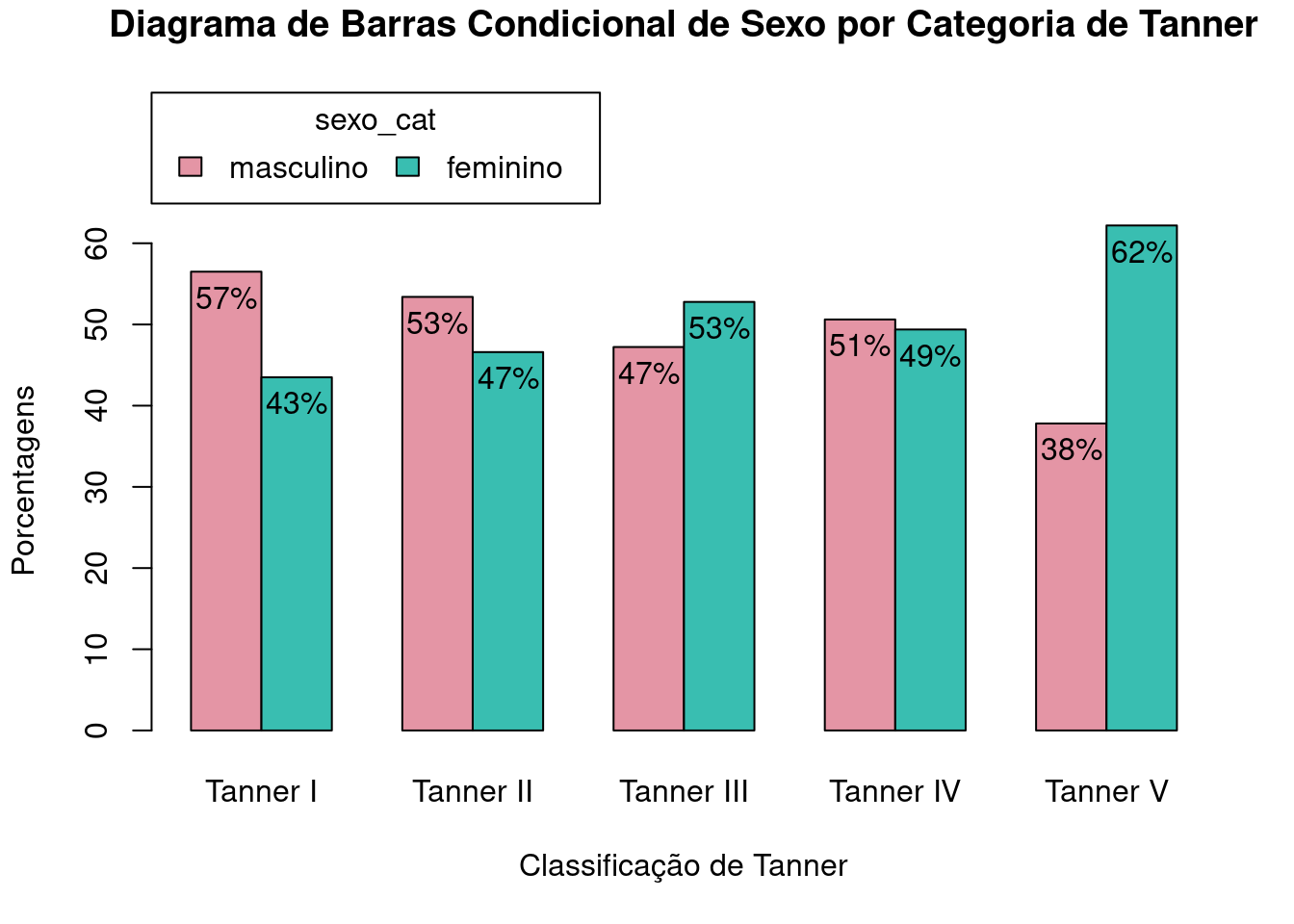
Figura 4.20: Diagrama de barras lado a lado para as porcentagens das categorias da variável sexo_cat em cada categoria da variável tanner_cat.
4.3 Usando a linha de comando
O conteúdo das seções 4.3.2, 4.3.3, 4.3.4, 4.3.5 e 4.3.6 podem ser visualizados neste vídeo.
Vamos aproveitar o comando anterior e verificar como podemos alterar diversos outros aspectos do gráfico, alguns dos quais não podem ser configurados via menu do R Commander. Alguns argumentos apresentados nas funções a seguir são comuns a diversos tipos de gráficos, outros são específicos do diagrama de barras.
4.3.1 Especificação dos rótulos dos eixos x e y e do título
Os argumentos xlab, ylab e main descrevem respectivamente os rótulos dos eixos x, y e título dos gráficos. Eles são comuns a todos os gráficos exibidos pelo R Commander.
4.3.2 Alteração dos tamanhos dos eixos X e Y
O gráfico da figura 4.19 mostra a altura de uma barra maior do que o tamanho do eixo Y. O argumento ylim é usado para alterar os limites do eixo Y. Ele é especificado como um vetor de dois elementos, onde o primeiro elemento representa o limite inferior e o segundo elemento representa o limite superior do eixo.
No comando a seguir, é acrescentado o argumento ylim = c(0, 30) à função Barplot, e as alturas das barras ficarão menor do que o valor máximo do eixo Y (figura 4.21). Um argumento análogo, xlim, seria usado para o eixo X.
with(juul2, Barplot(tanner_cat, by=sexo_cat, style="parallel",
legend.pos="above", xlab="Classificação de Tanner",
ylab="Porcentagens", conditional=FALSE, label.bars=TRUE,
main="Diagrama de Barras de Sexo por Categoria de Tanner",
scale="percent", ylim = c(0, 30)))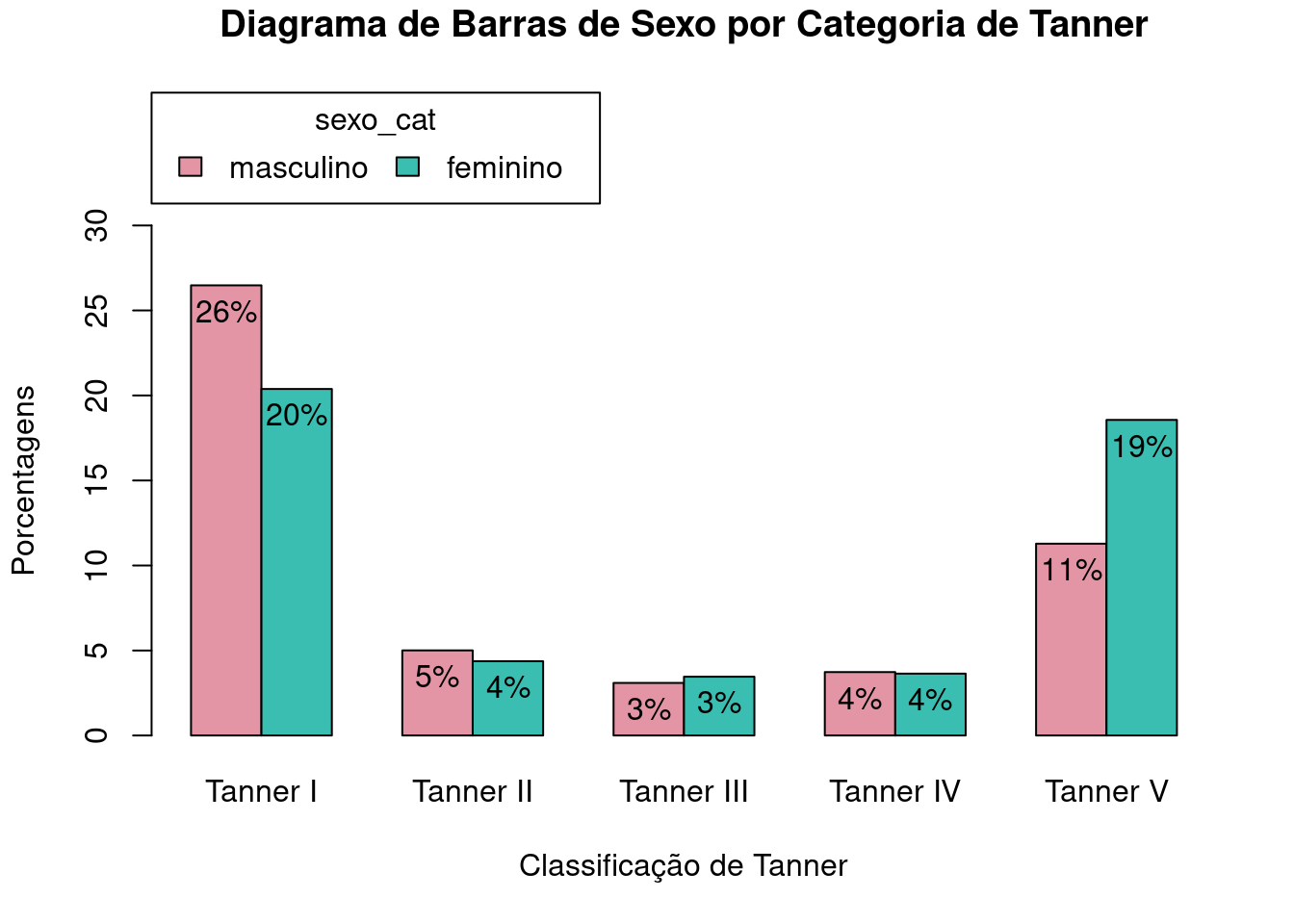
Figura 4.21: Diagrama de barras lado a lado para as porcentagens do total de observações de cada categoria de sexo_cat por categoria da variável tanner_cat, com a altura do eixo Y alterada para uma altura maior do que a altura da maior barra.
4.3.3 Alteração do título da legenda do diagrama
O argumento legend.title permite a alteração do título da legenda de um gráfico. O comando a seguir substitui o título original da legenda (“sexo_cat”) do gráfico 4.21 por “Sexo”. O resultado é mostrado na figura 4.22.
with(juul2, Barplot(tanner_cat, by=sexo_cat, style="parallel",
legend.pos="above", xlab="Classificação de Tanner",
ylab="Porcentagens", conditional=FALSE, label.bars=TRUE,
main="Diagrama de Barras de Sexo por Categoria de Tanner",
scale="percent", ylim = c(0, 30), legend.title = "Sexo"))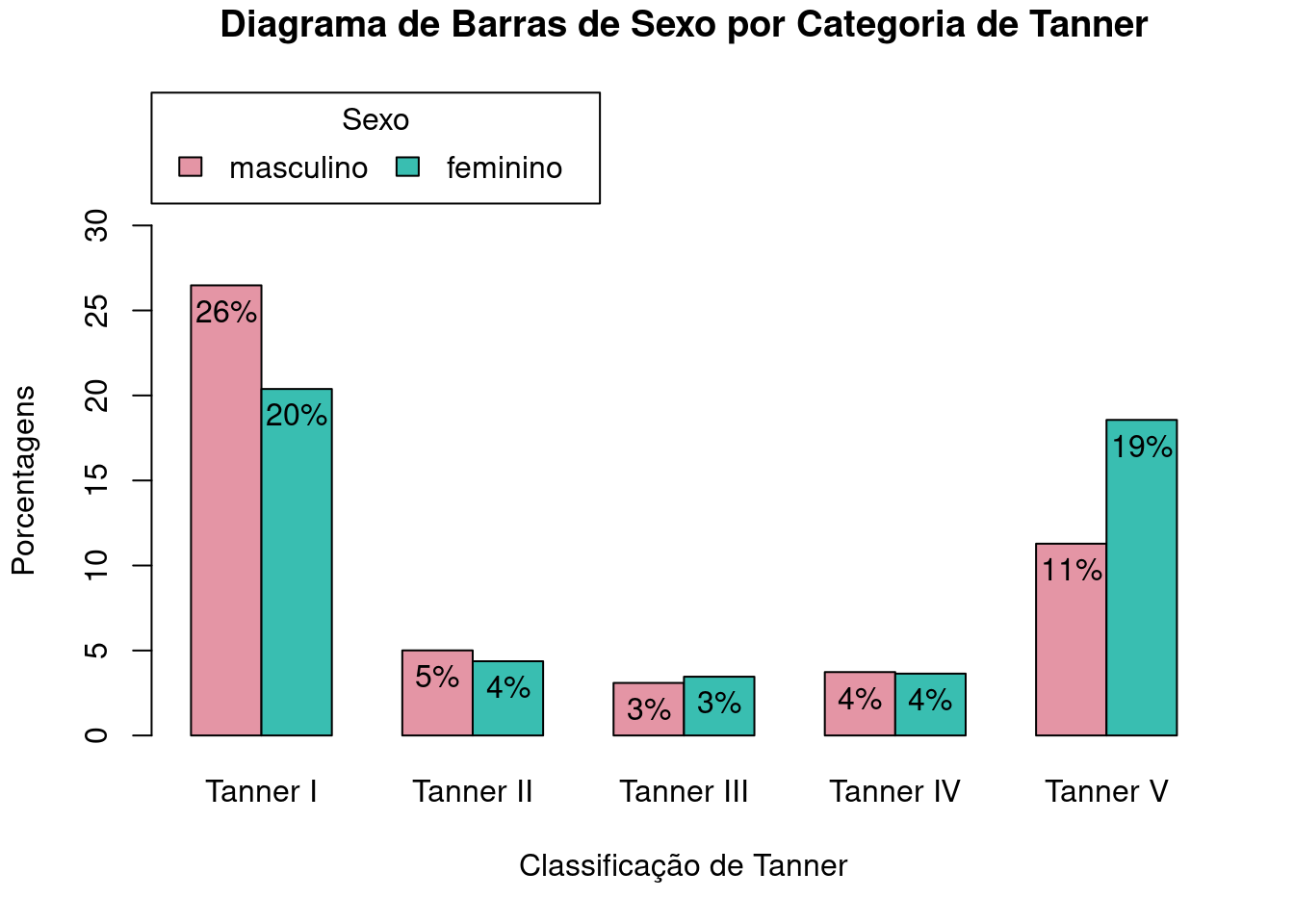
Figura 4.22: Diagrama de barras lado a lado para as porcentagens do total de observações de cada categoria de sexo_cat por categoria da variável tanner_cat, com a alteração do título da legenda.
4.3.4 Alteração do espaçamento entre as barras
O argumento space é utilizado para especificar o espaçamento entre as barras. Indiretamente, ele define a largura das barras. O espaçamento é expresso como uma fração da largura das barras. space pode ser expresso por dois números, sendo o primeiro o espaçamento entre as barras de um mesmo grupo e o segundo o espaçamento entre os grupos. Se space não for especificado, os seguintes valores são assumidos por padrão:
1) se o diagrama de barras incluir mais de um fator e as barras forem desenhadas lado a lado, então space = c(0,1), ou seja, o espaçamento entre os grupos de barras é igual à largura das mesmas;
2) para os demais casos space = 0.2, significando que o espaçamento entre as barras é igual a 20% da largura das barras.
O comando a seguir altera o espaçamento das barras para 20% da largura da barra dentro de cada grupo e para 1,5 vezes a largura da barra para a separação entre os grupos (figura 4.23).
with(juul2, Barplot(tanner_cat, by=sexo_cat, style="parallel",
legend.pos="above", xlab="Classificação de Tanner",
ylab="Porcentagens", conditional=FALSE, label.bars=TRUE,
main="Diagrama de Barras de Sexo por Categoria de Tanner",
scale="percent", ylim = c(0, 30), legend.title = "Sexo",
space = c(.2, 1.5)))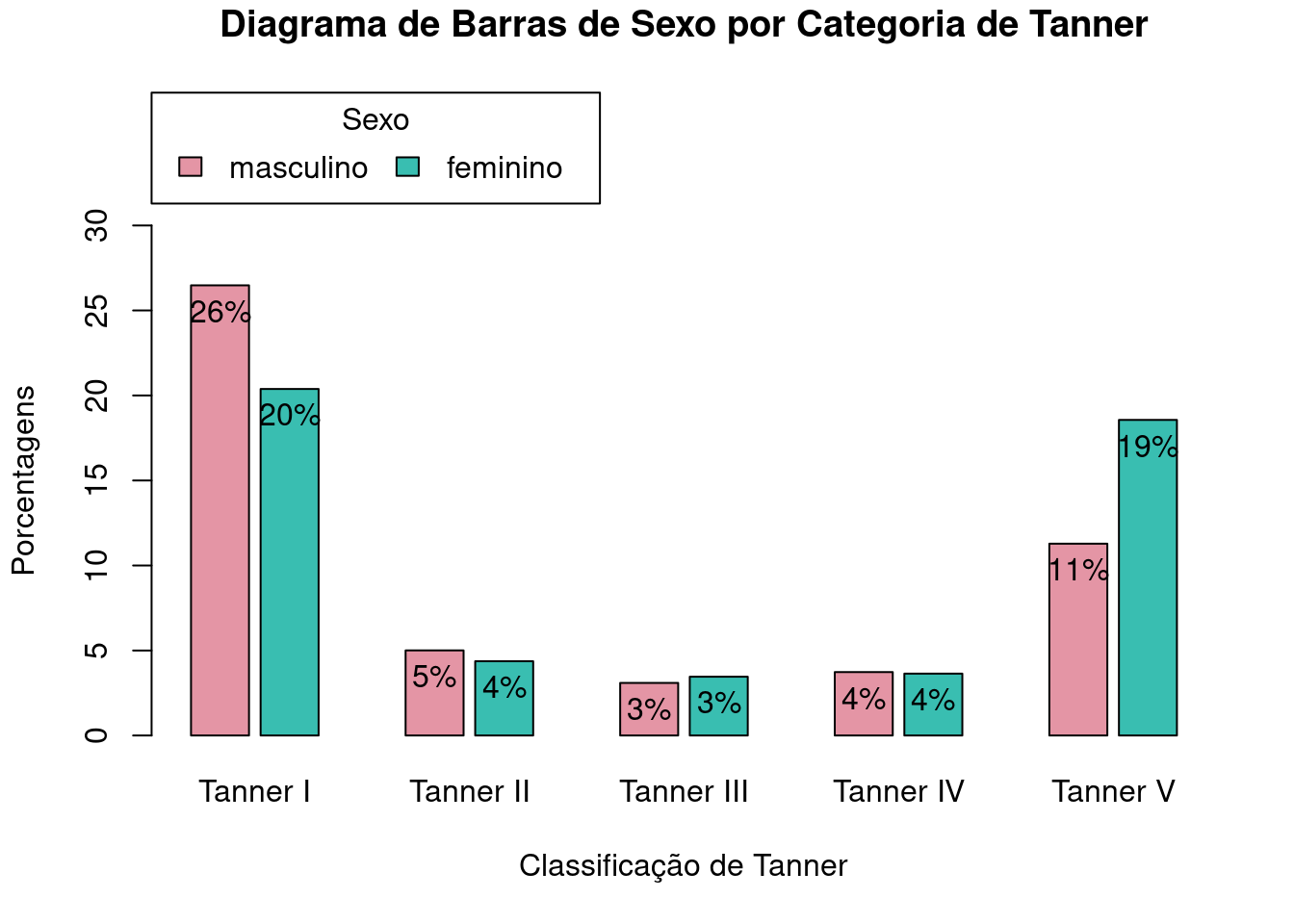
Figura 4.23: Diagrama de barras lado a lado para as porcentagens do total de observações de cada categoria de sexo_cat por categoria da variável tanner_cat, com a alteração do espaçamento entre as barras.
4.3.5 Tamanhos dos rótulos dos eixos X e Y, dos números no eixo Y e das categorias das barras
Para alterar o tamanho dos rótulos que aparecem nos eixos X e Y, o tamanho das categorias da variável do eixo X e o tamanho dos números das escalas dos eixos X e Y, são usados os argumentos cex.lab, cex.names, e cex.axis, respectivamente, sendo o número 1 o padrão.
Ao fazermos os argumentos cex.lab = 1.8, cex.names = 1.2 e cex.axis = 1.5 na função Barplot (comando a seguir), o gráfico resultante mostra os rótulos dos eixos X e Y com tamanho 80% maior, as categorias de Tanner 20% maiores, e os números das escalas do eixo Y 50% maiores (figura 4.24).
with(juul2, Barplot(tanner_cat, by=sexo_cat, style="parallel",
legend.pos="above", xlab="Classificação de Tanner",
ylab="Porcentagens", conditional=FALSE, label.bars=TRUE,
main="Diagrama de Barras de Sexo por Categoria de Tanner",
scale="percent", ylim = c(0, 30), legend.title = "Sexo",
space = c(.2, 1.5),
cex.lab = 1.8, cex.names = 1.2, cex.axis = 1.5))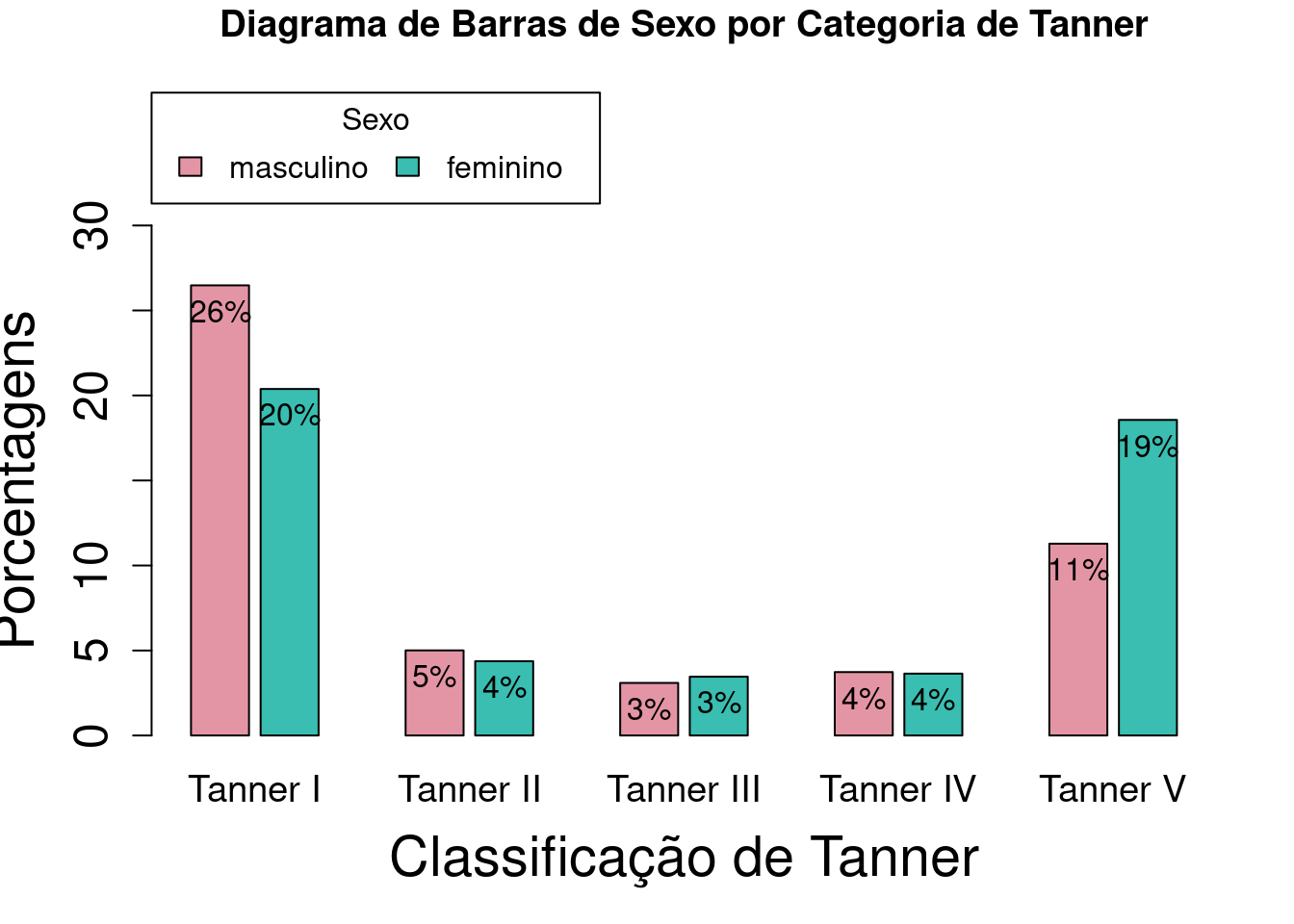
Figura 4.24: Diagrama de barras lado a lado para as porcentagens do total de observações de cada categoria de sexo_cat por categoria da variável tanner_cat, com alterações dos tamanhos dos rótulos dos eixos, das categorias de Tanner e da escala do eixo Y.
4.3.6 Alteração das categorias da variável do eixo X
Os rótulos das categorias da variável do eixo X podem ser alterados por meio do argumento names.arg, o qual deve ser especificado como um vetor com um valor do tipo character para cada categoria, ou seja, cada categoria deve ser especificada entre aspas.
O comando a seguir altera os nomes das categorias de Tanner de I a V para ‘T1’, ‘T2’, ‘T3’, ‘T4’, e ‘T5’, respectivamente. O gráfico resultante é mostrado na figura 4.25.
with(juul2, Barplot(tanner_cat, by=sexo_cat, style="parallel",
legend.pos="above", xlab="Classificação de Tanner",
ylab="Porcentagens", conditional=FALSE, label.bars=TRUE,
main="Diagrama de Barras de Sexo por Categoria de Tanner",
scale="percent", ylim = c(0, 30), legend.title = "Sexo",
space = c(.2, 1.5),
cex.lab = 1.8, cex.names = 1.2, cex.axis = 1.5,
names.arg = c('T1', 'T2', 'T3', 'T4', 'T5')))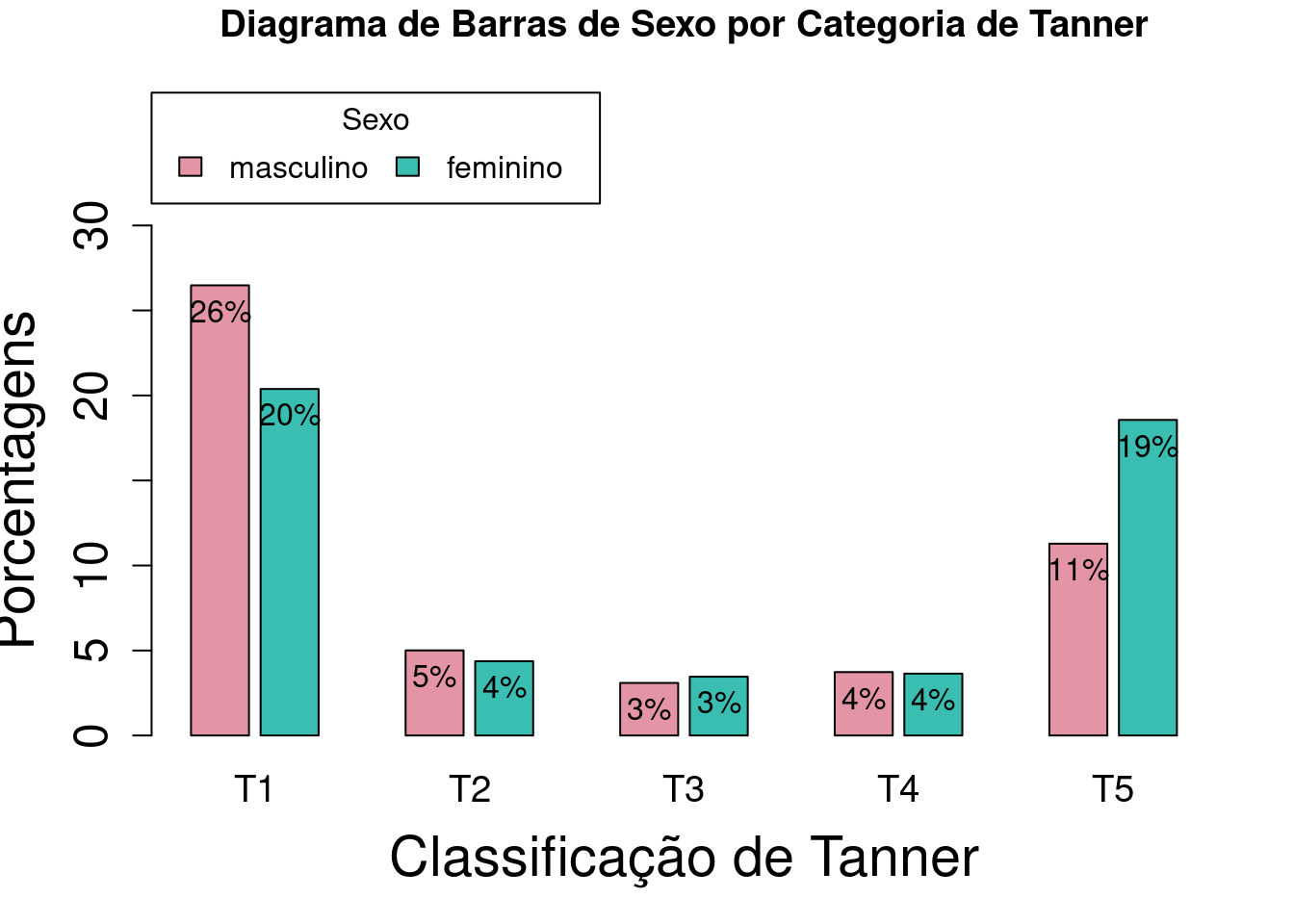
Figura 4.25: Diagrama de barras lado a lado para as porcentagens do total de observações de cada categoria de sexo_cat por categoria da variável tanner_cat, com a alteração dos nomes das categorias de Tanner.
4.3.7 Alteração das cores
O conteúdo desta seção pode ser visualizado neste vídeo.
O gráfico exibido na figura 4.13 mostra as barras na cor cinza. Já o gráfico da figura 4.19 mostra as barras nas cores rosa para o sexo masculino e verde para o feminino.
A função Barplot, por padrão, mostra as barras em cinza se um fator somente for especificado. Se dois fatores forem especificados, o segundo por meio do argumento by, as cores das barras são obtidas por meio da função rainbow_hcl do pacote colorspace.
Como fazer para alterar as cores das barras? O argumento col é usado para alterar as cores. Vamos ver algumas possibilidades.
No comando a seguir, foi acrescentado o argumento col com o valor c("blue”,"orange”), indicando as duas cores que serão utilizadas agora. Também foi acrescentado o argumento ylim = c(0,30) para alterar os limites do eixo Y. Ao executarmos o comando, selecionando todas as linhas do comando e clicando no botão Submeter, obteremos o gráfico da figura 4.26.
with(juul2, Barplot(tanner_cat, by=sexo_cat, style="parallel",
legend.pos="above", xlab="Classificação de Tanner",
ylab="Porcentagens", conditional=FALSE, label.bars=TRUE,
main="Diagrama de Barras de Sexo por Categoria de Tanner",
scale="percent", ylim = c(0, 30), col = c("blue","orange")))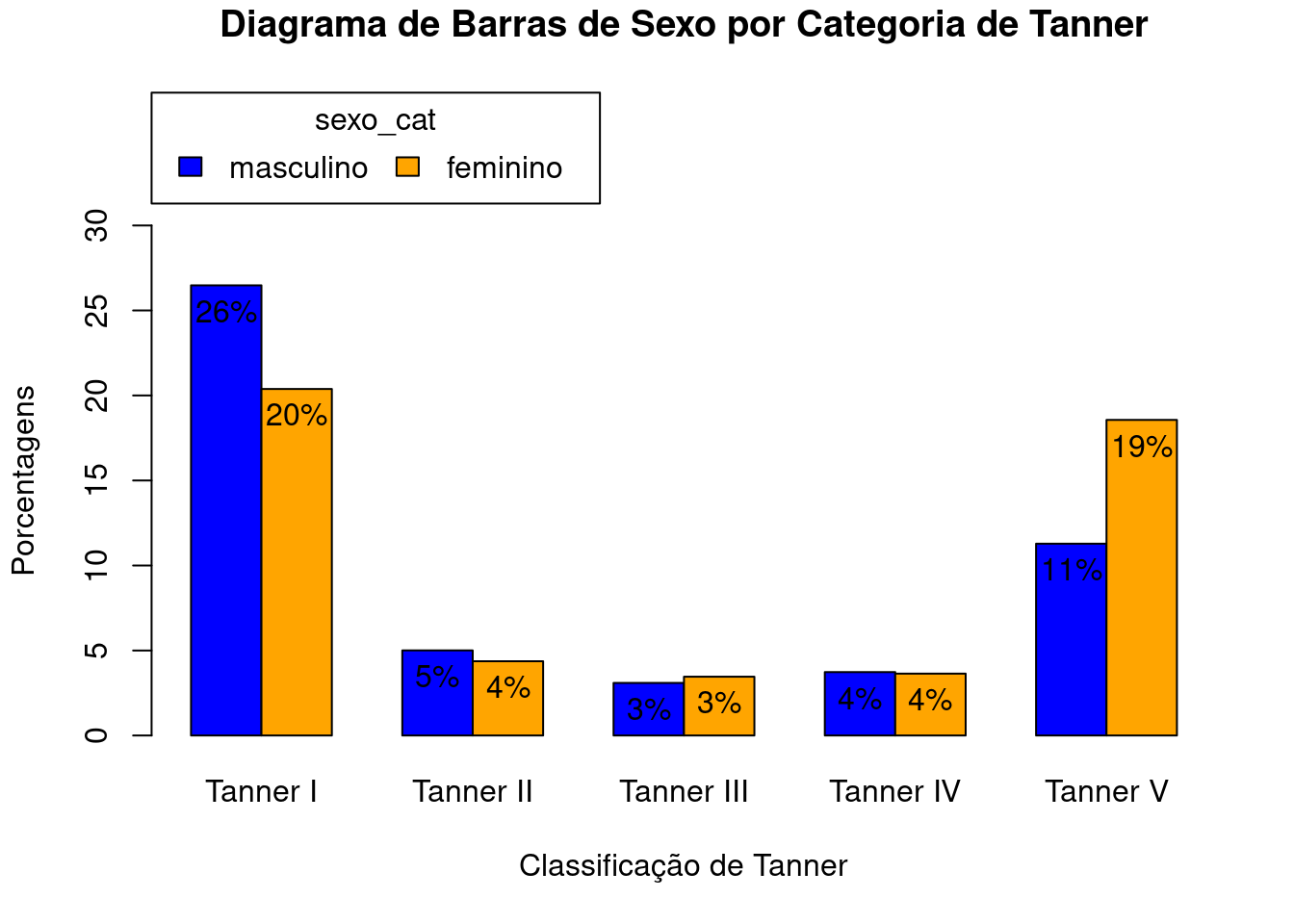
Figura 4.26: Diagrama de barras da figura 4.21, após a alteração das cores das barras.
Caso desejemos alterar as cores das barras em um diagrama de barras simples, sem variável de agrupamento, há diversas opções. Na aba de opções da figura 4.12, podemos marcar a opção From color palette no item Color Selection. O comando resultante é mostrado abaixo e o gráfico com barras vermelhas para cada categoria de Tanner é mostrado na figura 4.27.
with(juul2, Barplot(tanner_cat, xlab="Classificação de Tanner",
ylab="Frequência", label.bars=TRUE,
main="Diagrama de Barras da Classificação de Tanner",
col=palette()[2])
)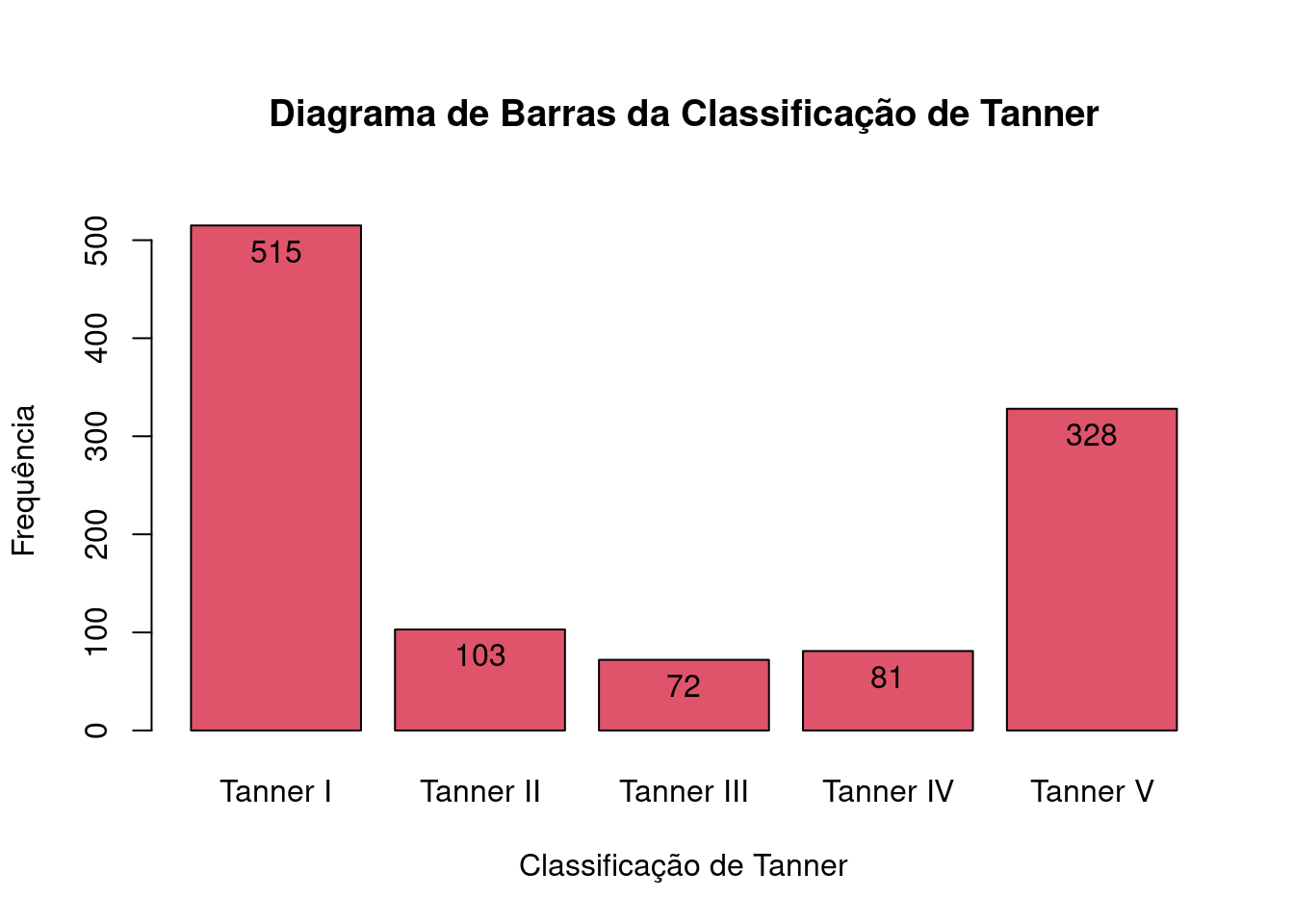
Figura 4.27: Diagrama de barras da figura 4.13, com as barras vermelhas.
A cor vermelha foi selecionada, porque o argumento col no comando anterior especificou a segunda cor da paleta de cores do R Commander (palette()[2]). A função palette retorna a paleta de cores do R Commander e o índice 2 indica a segunda cor desta paleta.
A figura 4.28 mostra a paleta de cores padrão do R Commander. Ela pode ser acessada pela opção do menu:
\[\text{Gráficos} \Rightarrow \text{Gradiente de cores (color palette)}\]
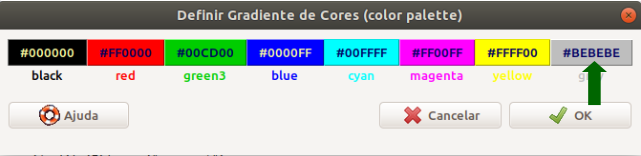
Figura 4.28: Paleta de cores do R Commander. Ao clicarmos na cor indicada pela seta verde, podemos substituí-la por outra.
Se quiséssemos a quarta cor da paleta nas barras, faríamos col = palette()[4] na chamada da função Barplot, ou simplesmente col = 4.
Podemos alterar cada cor dessa paleta, bastando clicar na cor que desejamos alterar. Se clicarmos na cor indicada pela seta verde na figura 4.28, poderemos alterá-la por meio da caixa de diálogo Select a color (figura 4.29). Após selecionarmos a cor e clicarmos no botão OK, a paleta será alterada (figura 4.30).
Figura 4.29: Caixa de diálogo para alterar uma cor da paleta.
Figura 4.30: Paleta com a última cor alterada.
Se fizermos col=c(2:6) para gerar o diagrama de barras das categorias de Tanner, obteremos o comando a seguir, que gera barras com cores diferentes (figura 4.31).
with(juul2, Barplot(tanner_cat, xlab="Classificação de Tanner",
ylab="Frequência", label.bars=TRUE,
main="Diagrama de Barras da Classificação de Tanner",
col=c(2:6)))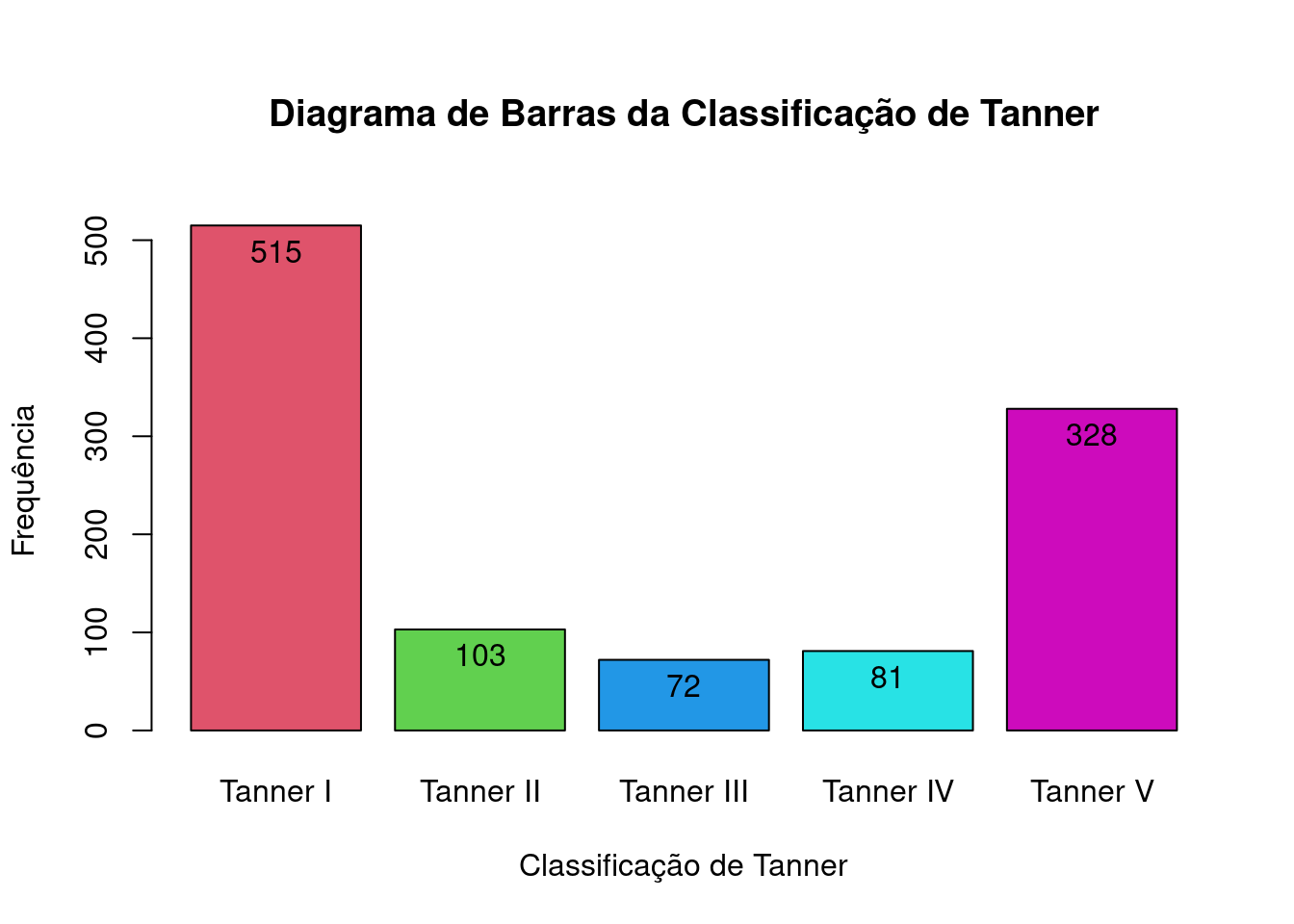
Figura 4.31: Diagrama de barras da figura 4.13, com barras de cores diferentes.
Observem que as cores foram especificadas como c(2:6), significando que foram utilizadas as cores de números 2 a 6 da paleta corrente. Cada barra será de uma cor. Experimentem executar o comando. Outra possibilidade seria especificarmos as cores pelos nomes como mostrado a seguir (figura 4.32).
with(juul2, Barplot(tanner_cat, xlab="Classificação de Tanner",
ylab="Frequência", label.bars=TRUE,
main="Diagrama de Barras da Classificação de Tanner",
col=c("red", "green", "blue", "cyan", "yellow")))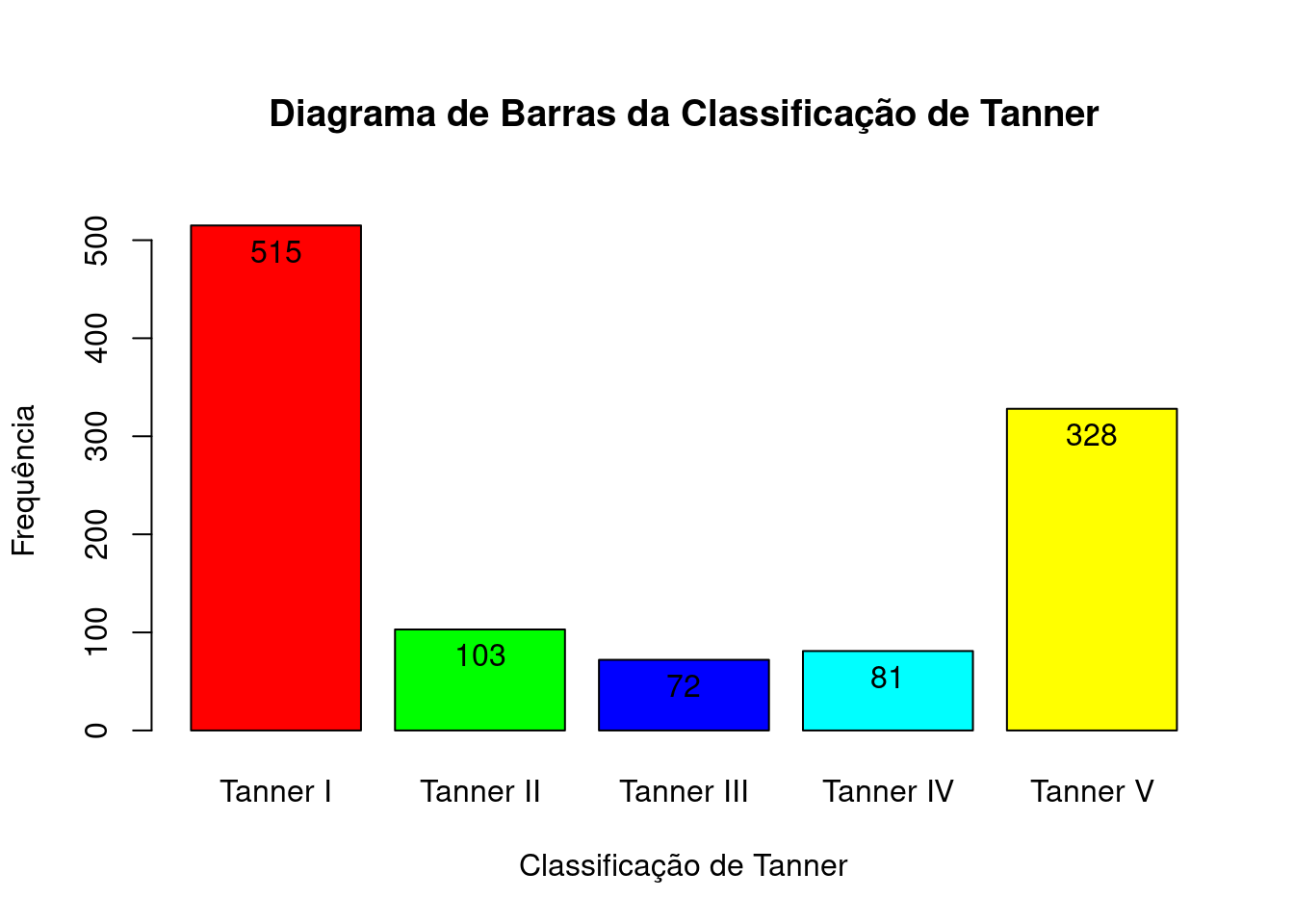
Figura 4.32: Diagrama de barras da figura 4.13, com barras de cores diferentes, especificadas pelo nome.
Observação: As interfaces gráficas não oferecem todos os recursos de cada função gráfica. Para conhecermos os argumentos disponíveis para cada função, usamos help(nome_da_função). A internet é uma excelente fonte de ajuda para entender como conseguir os efeitos desejados.
4.4 Diagrama de setores, torta ou pizza
O conteúdo desta seção pode ser visualizado neste vídeo.
O diagrama de setores também é utilizado para a visualização de variáveis categóricas. Nesse diagrama, um círculo é dividido em fatias, onde a área de cada fatia é proporcional à frequência de cada categoria da variável no conjunto de dados. Essa informação também é transmitida pelo diagrama de barras.
Para construirmos um diagrama de setores no R Commander, selecionamos a opção do menu:
\[\text{Gráficos} \Rightarrow \text{Gráfico de Pizza}\]
Em seguida, selecionamos a variável categórica para a qual o diagrama será construído, digitamos um título para o gráfico e clicamos em OK (figura 4.33). A figura 4.34 mostra o gráfico resultante.
Figura 4.33: Caixa de diálogo para a geração de um diagrama de setores. Selecionamos a variável e digitamos o título do gráfico (opcional).
Observem que o gráfico da figura 4.34 não mostra os percentuais ou as frequências de cada fatia, apesar de dar uma ideia da frequência relativa (ou porcentagens) de cada categoria no conjunto de dados.
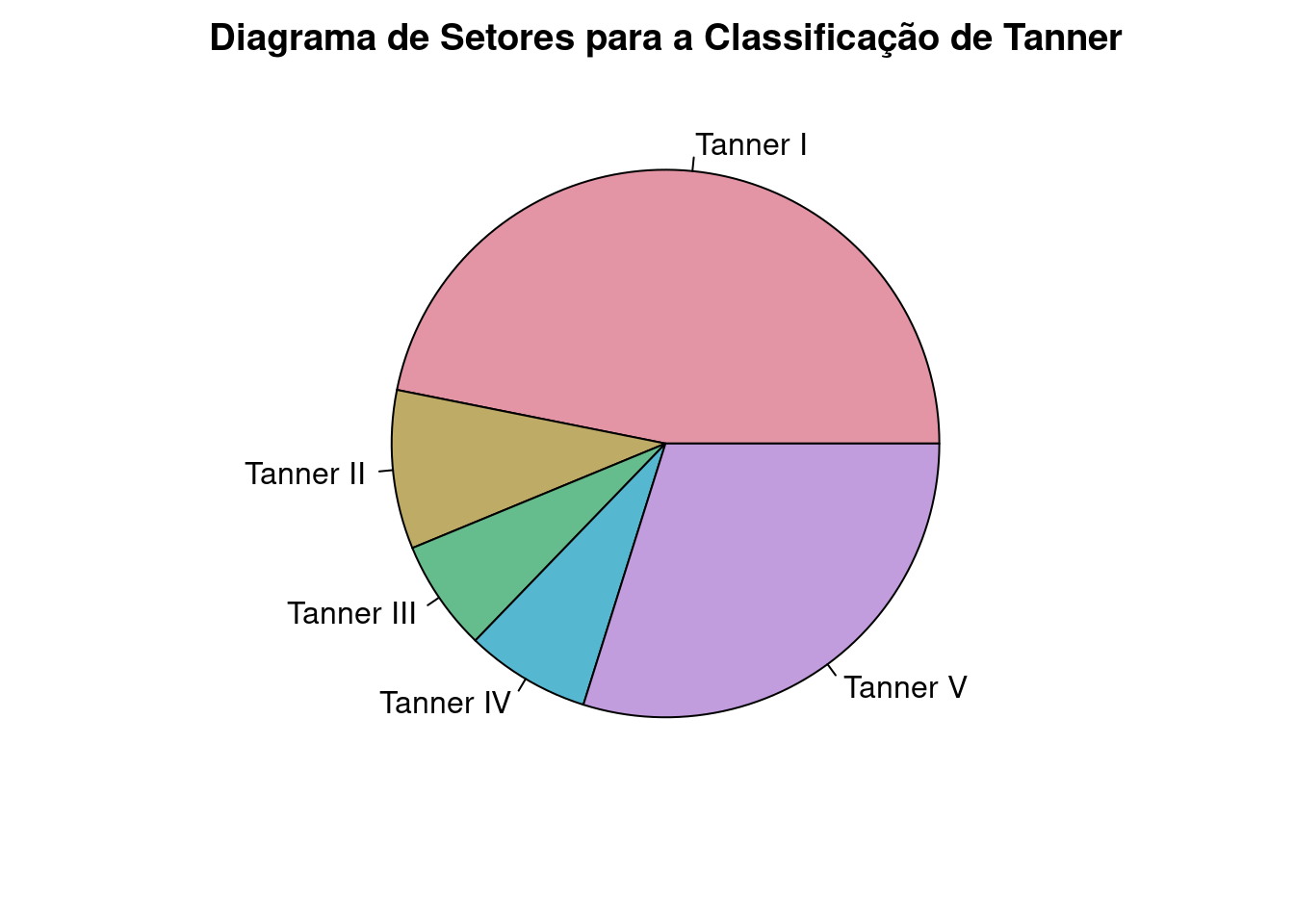
Figura 4.34: Diagrama de setores das categorias de Tanner.
Para obter um gráfico com as frequências (ou percentuais) de cada categoria, podemos utilizar a sequência de comandos a seguir, e o resultado é o gráfico da figura 4.35.
par(mar=c(1,1,1,1))
frequencias <- as.vector(with(juul2, table(tanner_cat)))
piepercent<- paste(as.character(
round(100*frequencias/sum(frequencias), 1)), "%")
with(juul2, pie(table(tanner_cat), labels=piepercent,
main="Classificação de Tanner",
col=c(1:length(levels(tanner_cat)))))
legend(.9, .1, legend=c(levels(juul2$tanner_cat)), cex = 0.7,
fill = c(1:length(levels(juul2$tanner_cat)) ))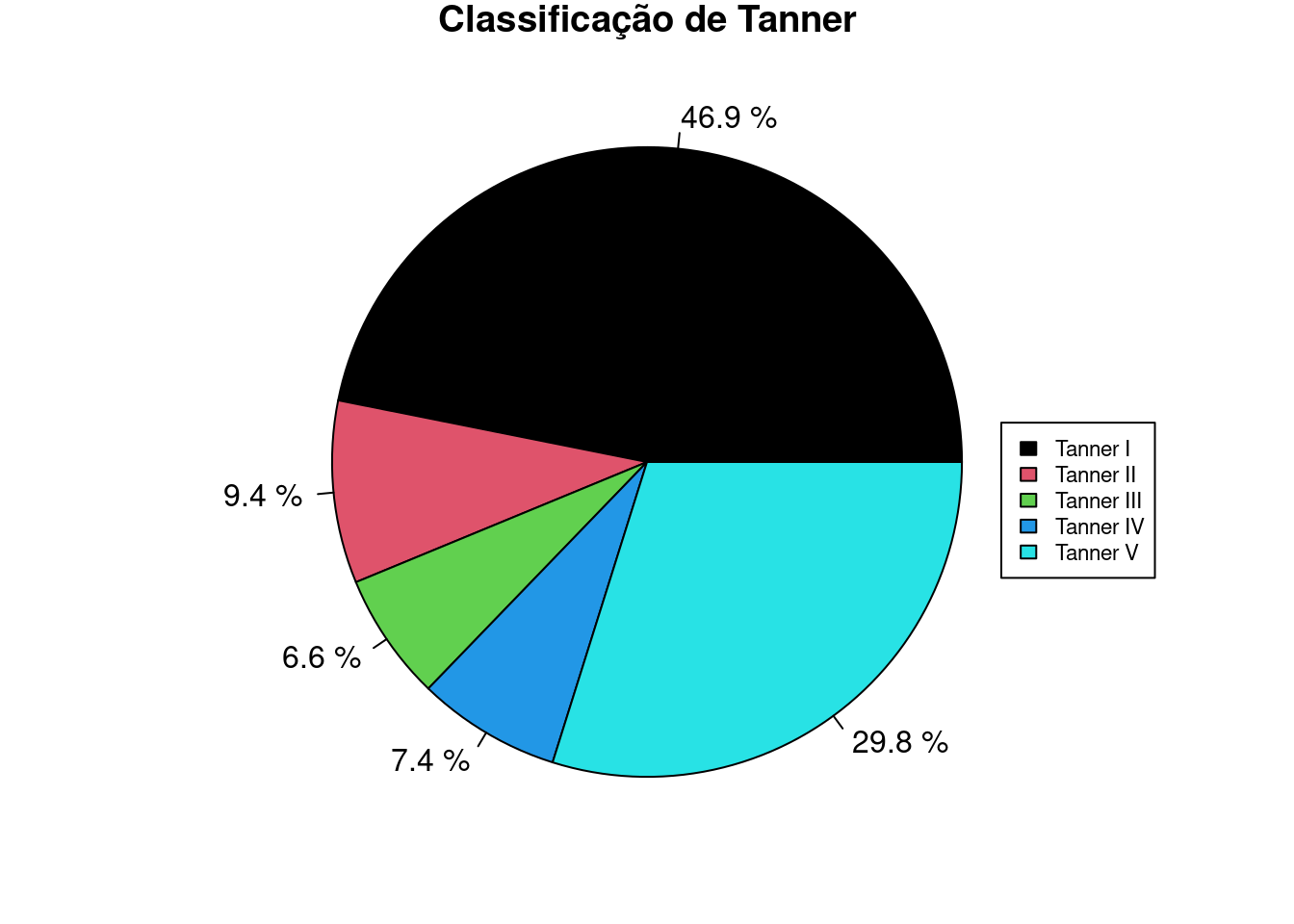
Figura 4.35: Diagrama de setores das categorias de Tanner, com os percentuais de cada categoria.
Vamos entender a sequência de comandos para gerar o gráfico de setores com porcentagens:
- criamos um vetor com as frequências de cada categoria com o comando a seguir:
frequencias <- as.vector(with(juul2, table(tanner_cat)))
A função table cria uma tabela com a frequência de cada categoria de Tanner no conjunto de dados.
- a partir dessas frequências, criamos um outro vetor (chamado piepercent) que fornece os percentuais de cada categoria, com o comando a seguir:
piepercent <- paste(as.character(round(100*frequencias/sum(frequencias), 1)), “%”)
A função round arredonda o número especificado no primeiro argumento de acordo com o número de decimais especificado pelo segundo argumento. A função as.character transforma o número arredondado para character e paste concatena essa string com o sinal de porcentagem.
Então usamos o comando gerado pelo R Commander para a criação do diagrama e o modificamos conforme a seguir. Observem que alteramos o argumento labels, substituindo o seu valor por piepercent:
with(juul2, pie(table(tanner_cat), labels=piepercent, main="Classificação de Tanner", col=c(1:length(levels(tanner_cat)))))Finalmente adicionamos uma legenda, indicando as cores de cada categoria com o comando a seguir:
legend(.9, .1, legend=c(levels(juul2$tanner_cat)), cex = 0.7,
fill = c(1:length(levels(juul2$tanner_cat)) ))
Se for desejado criar um gráfico de pizza com frequências em vez de percentuais, basta alterar o comando do passo 3 acima, substituindo o valor do argumento labels, como a seguir. Lembrem-se de que o vetor frequencias foi obtido no passo 1. O gráfico é exibido na figura 4.36.
par(mar=c(1,1,1,1))
with(juul2, pie(table(tanner_cat), labels=frequencias,
main="Classificação de Tanner",
col=c(1:length(levels(tanner_cat)) )))
legend(.9, .1, legend=c(levels(juul2$tanner_cat)), cex = 0.7,
fill = c(1:length(levels(juul2$tanner_cat)) ))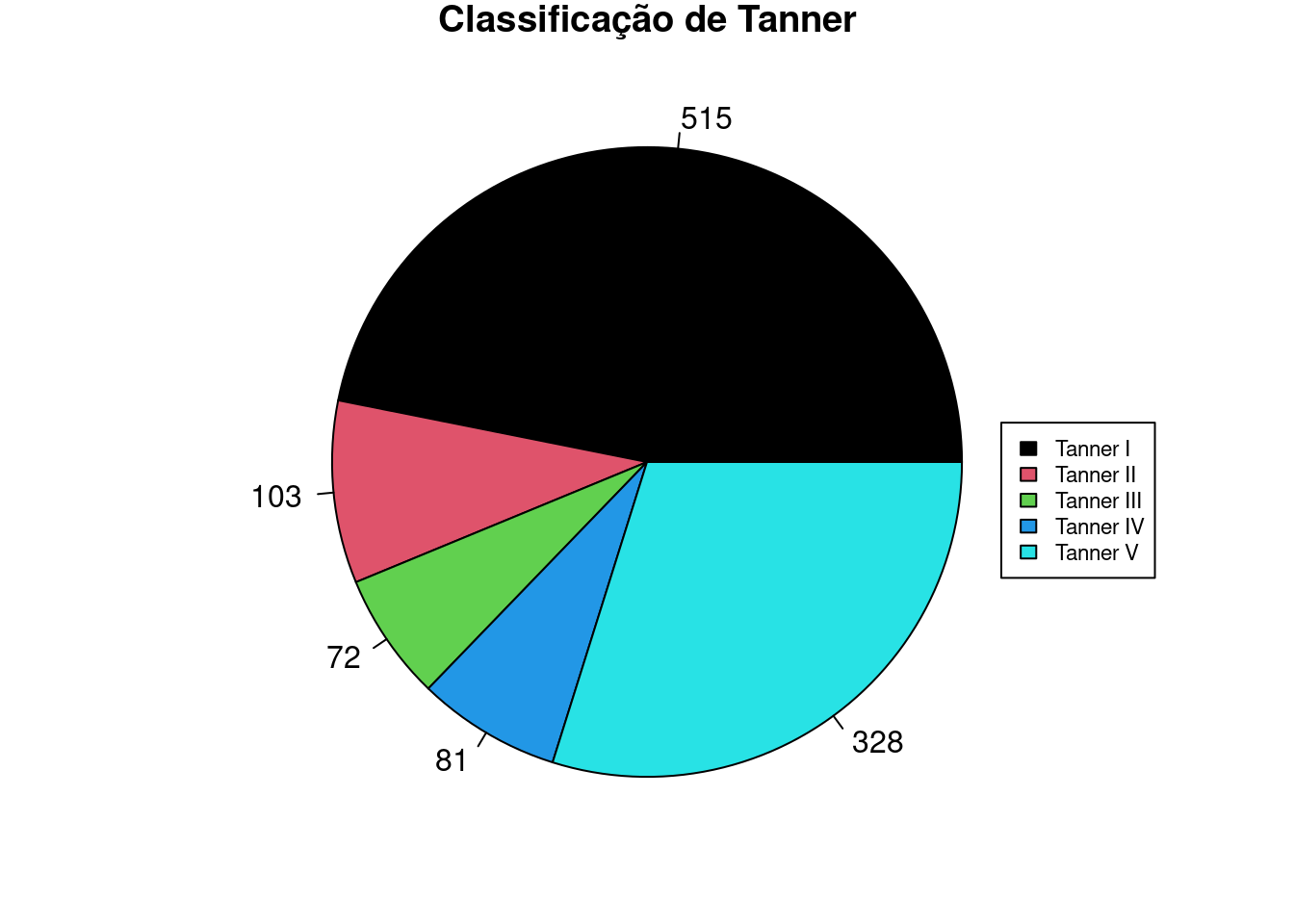
Figura 4.36: Diagrama de setores das categorias de Tanner, com as frequências de cada categoria.
A partir da próxima seção, serão mostrados recursos para a visualização da distribuição dos valores de varíáveis numéricas.
4.5 Diagrama de caixa (boxplot ou box and whisker plot)
O conteúdo desta seção pode ser visualizado neste vídeo, seguido deste vídeo.
O diagrama de caixa (em inglês, box and whisker plot, ou simplesmente boxplot) é um dos mais úteis diagramas para visualizar a distribuição de dados numéricos. Para explicar como o mesmo é construído, vamos criar um diagrama de boxplot, selecionando a opção:
\[\text{Gráficos} \Rightarrow \text{Boxplot}\]
A figura 4.37 mostra a tela de configuração do boxplot. Na aba Dados, selecionamos a variável. Neste exemplo, selecionamos a variável igf1 (fator de crescimento parecido com a insulina tipo 1). Na aba Opções, digitamos um título para o gráfico e marcamos a opção de não identificar os outliers (figura 4.38). O gráfico é mostrado na figura 4.39.
Figura 4.37: Caixa de diálogo para a geração do boxplot. Nesse exemplo, estamos selecionando a variável igf1.
Figura 4.38: Aba Opções da caixa de diálogo para a geração do boxplot.
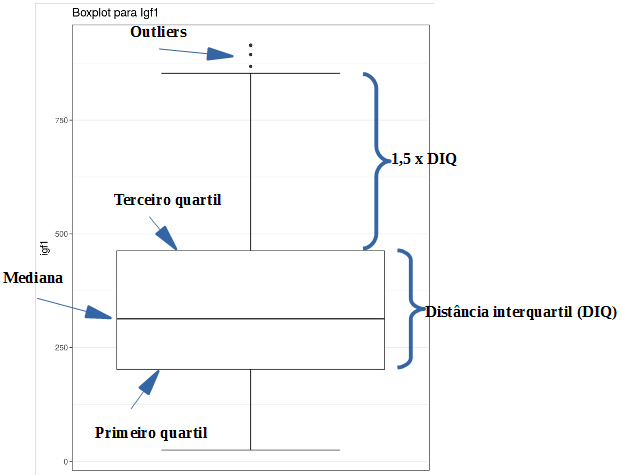
Figura 4.39: Boxplot da variável igf1.
O boxplot consiste de uma caixa cuja linha inferior indica o valor do primeiro quartil da variável, e a linha superior indica o terceiro quartil. Logo a altura da caixa indica a distância interquartil (DIQ). Uma terceira linha horizontal, a mediana, divide a caixa em duas partes. Partindo do meio da linha superior da caixa, uma linha vertical (whisker = bigode) liga o terceiro quartil ao valor imediatamente inferior ou igual ao valor do terceiro quartil somado a 1,5 x DIQ. Valores acima do whisker são considerados outliers e indicados por pontos. De maneira semelhante, uma linha vertical parte do meio da linha inferior da caixa e liga o primeiro quartil ao valor imediatamente acima ou igual ao primeiro quartil subtraído de 1,5 x DIQ. Pontos inferiores a esse valor também seriam considerados outliers e representados por pontos. Nesse exemplo, o menor valor de igf1 está a uma distância do primeiro quartil menor que 1,5 x DIQ. Por isso o whisker inferior não possui o mesmo tamanho do superior e não aparece outliers na porção inferior do diagrama.
O boxplot fornece diversas informações: os valores do primeiro e terceiro quartis, a mediana, a simetria ou assimetria dos dados e a presença de outliers. No diagrama da figura 4.39, verificamos uma certa assimetria dos dados de igf1 e a presença de outliers.
É possível construir os whiskers com diferentes tamanhos do que aqui mostrado, assim como podem ser usados a média e desvio padrão para construir os limites da caixa. Porém o método apresentado acima é o mais utilizado e é o padrão na função Boxplot.
O boxplot da figura 4.39 mostra a distribuição de todos os valores de igf1. Podemos construir um boxplot de igf1 para cada categoria da classificação de Tanner, ou por sexo, ou por cada combinação de sexo e classificação de Tanner.
Para mostrarmos o boxplot de igf1 para cada categoria da classificação de Tanner, clicamos no botão Gráfico por grupos… na caixa de diálogo do boxplot (figura 4.37) e selecionamos a variável tanner_cat para compor os grupos. Na aba Opções (figura 4.38), podemos digitar uma legenda para o eixo X. O resultado é mostrado na figura 4.40.
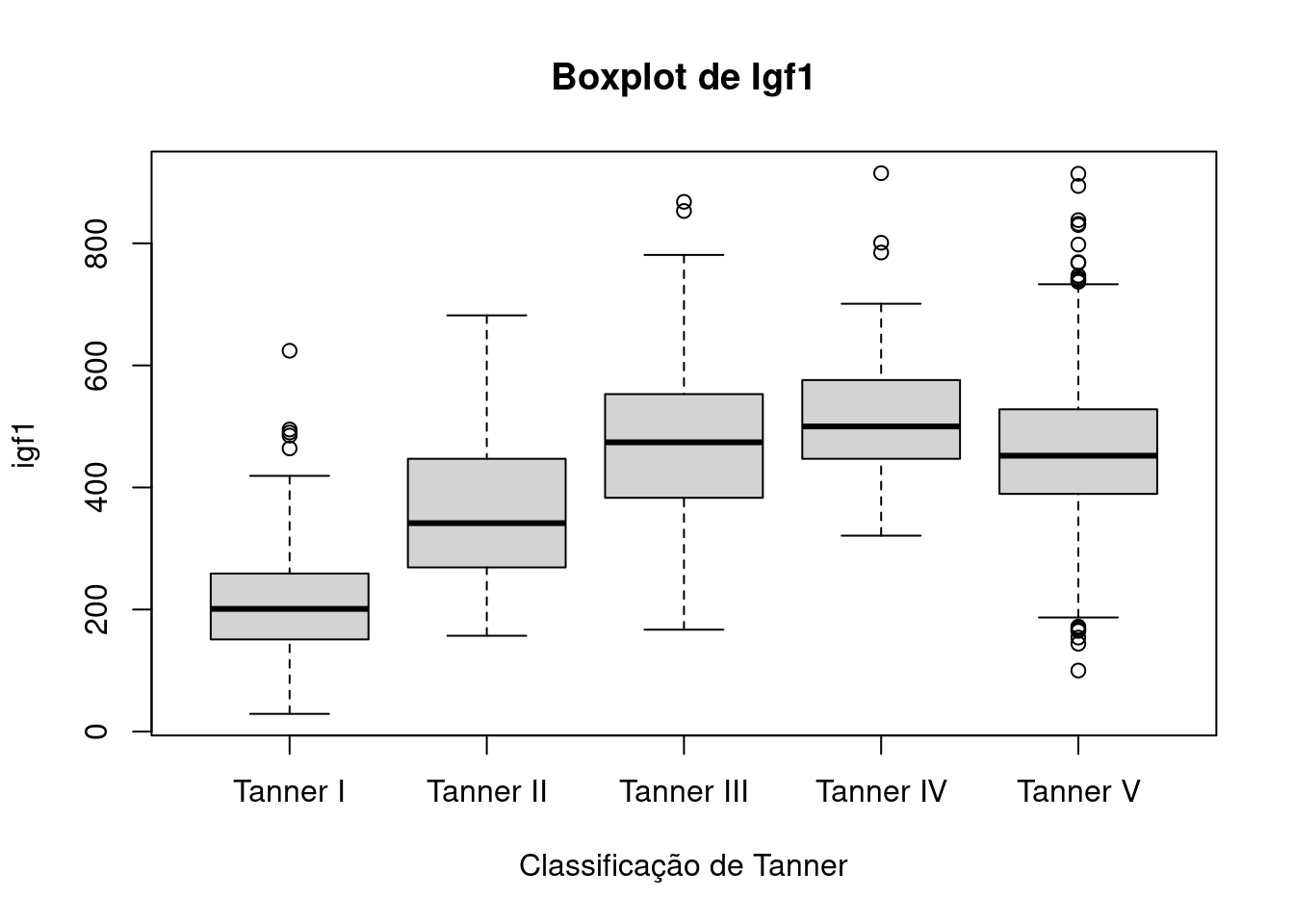
Figura 4.40: Boxplots para a variável igf1 para cada categoria de Tanner.
Esse gráfico nos fornece uma visão melhor de como os valores de igf1 estão distribuídos. À medida que as pessoas vão crescendo, os valores de igf1 tendem a aumentar até o nível III da classificação de Tanner, tendendo a se estabilizarem a partir desta categoria. As distribuições dos valores de igf1 tendem a ser simétricas nas categorias III e V de Tanner e ligeiramente assimétricas nas demais categorias.
Observação: Devemos ter cautela, porém, com as afirmações do parágrafo anterior, porque os dados de igf1 foram coletados a partir de um estudo transversal. Um conjunto de pessoas foram selecionadas e os valores de idade e igf1 foram coletados para cada uma delas. Um estudo mais apropriado para verificar a dependência de igf1 com a idade seria um estudo longitudinal, onde um grupo de pessoas fosse acompanhado ao longo do tempo e os valores de igf1 fossem medidos em diversos instantes para cada indivíduo à medida que ele ou ela fosse envelhecendo.
4.6 Histograma
O conteúdo desta seção pode ser visualizado neste vídeo.
Os histogramas, ao lado dos boxplots, são os gráficos mais utilizados para visualizarmos dados numéricos. Os histogramas são construídos, agrupando os valores numéricos da variável em faixas de valores e desenhando uma barra com largura igual ao tamanho da faixa e com altura, por exemplo, igual à frequência relativa de valores (percentual de valores) na faixa correspondente. As faixas são contíguas e o conjunto de barras compõem o histograma.
Para construirmos um histograma no R Commander, selecionamos a opção:
\[\text{Gráficos} \Rightarrow \text{Histograma}\]
Em seguida, selecionamos a variável desejada, igf1 nesse exemplo (figura 4.41). Na aba Opções (figura 4.42), vamos selecionar percentagens em Escala do eixo e digitar a legenda do eixo Y. Ao clicarmos em OK, o gráfico resultante é mostrado na figura 4.43.
Figura 4.41: Caixa de diálogo para a criação de um histograma. Na aba Dados, selecionamos a variável numérica desejada.
Figura 4.42: Caixa de diálogo para a criação de um histograma. Na aba Opções, podemos especificar o número de faixas de valores (classes), a escala do eixo e as legendas.
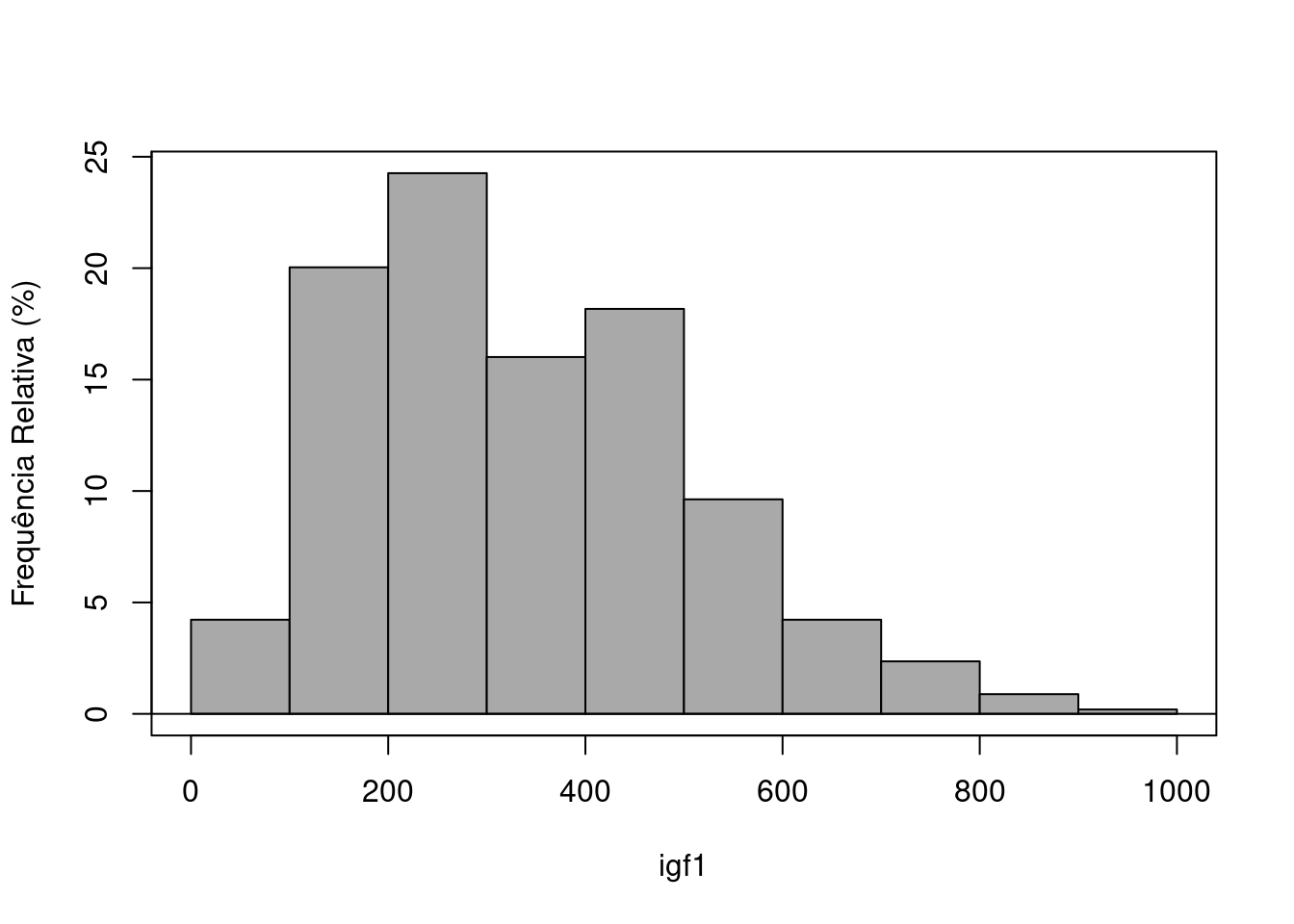
Figura 4.43: Histograma de frequência relativa da variável igf1.
Os passos para a construção de um histograma são:
1) definir um conjunto exaustivo de faixas de valores para a variável em questão. Cada faixa de valores é usualmente denominada classe. No exemplo acima, os valores de igf1 foram distribuídos em 10 classes de amplitude 100 cada uma;
2) para cada classe, calcular a frequência dos valores nela contidas;
3) no caso de um histograma de frequência relativa, dividir a frequência de cada classe pelo número total de valores;
4) plotar uma barra para cada classe, com altura igual à frequência relativa (ou a mesma multiplicada por 100 para mostrar os percentuais de cada classe).
No exemplo dado, os limites das classes são:
0, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000
Os valores da primeira classe são aqueles que pertencem ao intervalo (0, 100]. Desse modo, todos os valores da primeira classe devem satisfazer a seguinte desigualdade: \(0 < x \le 100\). As demais classes devem ser interpretadas de maneira análoga. Essa é a forma padrão que a função hist do R monta as classes do histograma. A tabela 4.1 mostra, para cada classe, os seus limites, contagem de valores (frequência) e a correspondente frequência relativa em porcentagem.
| Classe | Limite Inferior (\(\gt\)) | Limite Superior (\(\leq\)) | Frequência | Frequência Relativa (%) |
|---|---|---|---|---|
| 1 | 0 | 100 | 43 | 4,22 |
| 2 | 100 | 200 | 204 | 20,04 |
| 3 | 200 | 300 | 247 | 24,26 |
| 4 | 300 | 400 | 163 | 16,01 |
| 5 | 400 | 500 | 185 | 18,17 |
| 6 | 500 | 600 | 98 | 9,63 |
| 7 | 600 | 700 | 43 | 4,22 |
| 8 | 700 | 800 | 24 | 2,36 |
| 9 | 800 | 900 | 9 | 0,88 |
| 10 | 900 | 1000 | 2 | 0,2 |
| 1018 | 100 |
No exemplo apresentado, o número de classes utilizado para agrupar os valores de igf1 foi 10, determinado automaticamente pela função de geração do histograma. Entretanto esse número pode ser escolhido pelo usuário: basta digitar o número de classes desejado na opção Numero de classes da figura 4.42. O número de classes não deve ser um número muito baixo, de modo que tenhamos uma visão muito grosseira da distribuição de dados, nem muito alto, de modo que cada classe tenha poucos valores. O número de classes deve fornecer uma boa ideia de como os dados estão distribuídos, geralmente um número entre 10 e 20.
O comando que foi utilizado para a criação do histograma da figura 4.43 é mostrado a seguir:
with(juul2, Hist(igf1, scale="percent", breaks="Sturges", col="darkgray",
ylab="Frequência Relativa (%)"))O argumento breaks indica como as classes serão definidas. O valor nesse exemplo, Sturges, indica o nome de um algoritmo utilizado para calcular o número de classes do histograma. Outros nomes de algoritmos são Scott e Freedman-Diaconis. Não vamos entrar em detalhes desses algoritmos. Além deles, o usuário pode especificar o nome de uma função qualquer que calcule o número de classes, ou fixar o número de classes, ou mesmo especificar os limites das classes. Nós veremos essa última opção mais adiante.
4.6.1 Histograma de frequência x frequência relativa x densidade de frequência relativa
O conteúdo desta seção pode ser visualizado neste vídeo.
Na seção anterior, criamos um histograma de frequência relativa para a variável igf1. Porém um histograma também pode ser criado, partindo-se da frequência ou da densidade de frequência relativa. Quando a amplitude de cada classe é a mesma, a aparência dos histogramas é a mesma, variando apenas a escala do eixo vertical.
Vamos alterar as classes do histograma para a variável igf1 de modo que as suas amplitudes sejam diferentes e vamos ver as diferenças entre os três tipos de histogramas. A tabela 4.2 mostra as classes, a frequência, a frequência relativa e a densidade de frequência relativa para cada classe. Esse último termo será explicado mais adiante. Observem que as classes 1 e 10 possuem amplitude igual a 100, a classe 11 possui amplitude igual a 400 e as demais classes possuem amplitude igual a 50.
| Classe | Limite Inferior (\(\gt\)) | Limite Superior (\(\leq\)) | Frequência | Frequência Relativa (%) | Densidade de Frequência Relativa (x 10-3) |
|---|---|---|---|---|---|
| 1 | 0 | 100 | 43 | 4,22 | 0,42 |
| 2 | 100 | 150 | 74 | 7,27 | 1,45 |
| 3 | 150 | 200 | 130 | 12,77 | 2,55 |
| 4 | 200 | 250 | 129 | 12,67 | 2,53 |
| 5 | 250 | 300 | 118 | 11,59 | 2,32 |
| 6 | 300 | 350 | 69 | 6,78 | 1,36 |
| 7 | 350 | 400 | 94 | 9,23 | 1,85 |
| 8 | 400 | 450 | 93 | 9,14 | 1,82 |
| 9 | 450 | 500 | 92 | 9,04 | 1,80 |
| 10 | 500 | 600 | 98 | 9,63 | 0,96 |
| 11 | 600 | 1000 | 78 | 7,66 | 0,19 |
| 1018 | 100 |
A figura 4.44 mostra diversos histogramas para a variável igf1. Essa figura foi construída com a sequência de comandos a seguir:
par(mfrow = c(2,2))
with(juul2, Hist(igf1, scale="percent", breaks="Sturges", col="darkgray",
ylab="Frequência Relativa (%)"))
text(-150, -80, labels="a)", pos = 1, xpd = T, cex = 1.5)
with(juul2, Hist(igf1, scale="frequency", freq = TRUE,
breaks=c(0,100,150,200,250,300,350,400,450,500, 600, 1000),
col="darkgray", ylab="Frequência"))
text(-150, -40, labels="b)", pos = 1, xpd = T, cex = 1.5)
with(juul2, Hist(igf1, scale="percent", freq = TRUE,
breaks=c(0,100,150,200,250,300,350,400,450,500, 600, 1000),
col="darkgray", ylab="Frequência Relativa(%)"))
text(-150, -40, labels="c)", pos = 1, xpd = T, cex = 1.5)
with(juul2, Hist(igf1, scale="density",
breaks=c(0,100,150,200,250,300,350,400,450,500, 600, 1000),
col="darkgray", ylab="Densidade de Frequência Relativa"))
text(-150, -0.0010, labels="d)", pos = 1, xpd = T, cex = 1.5)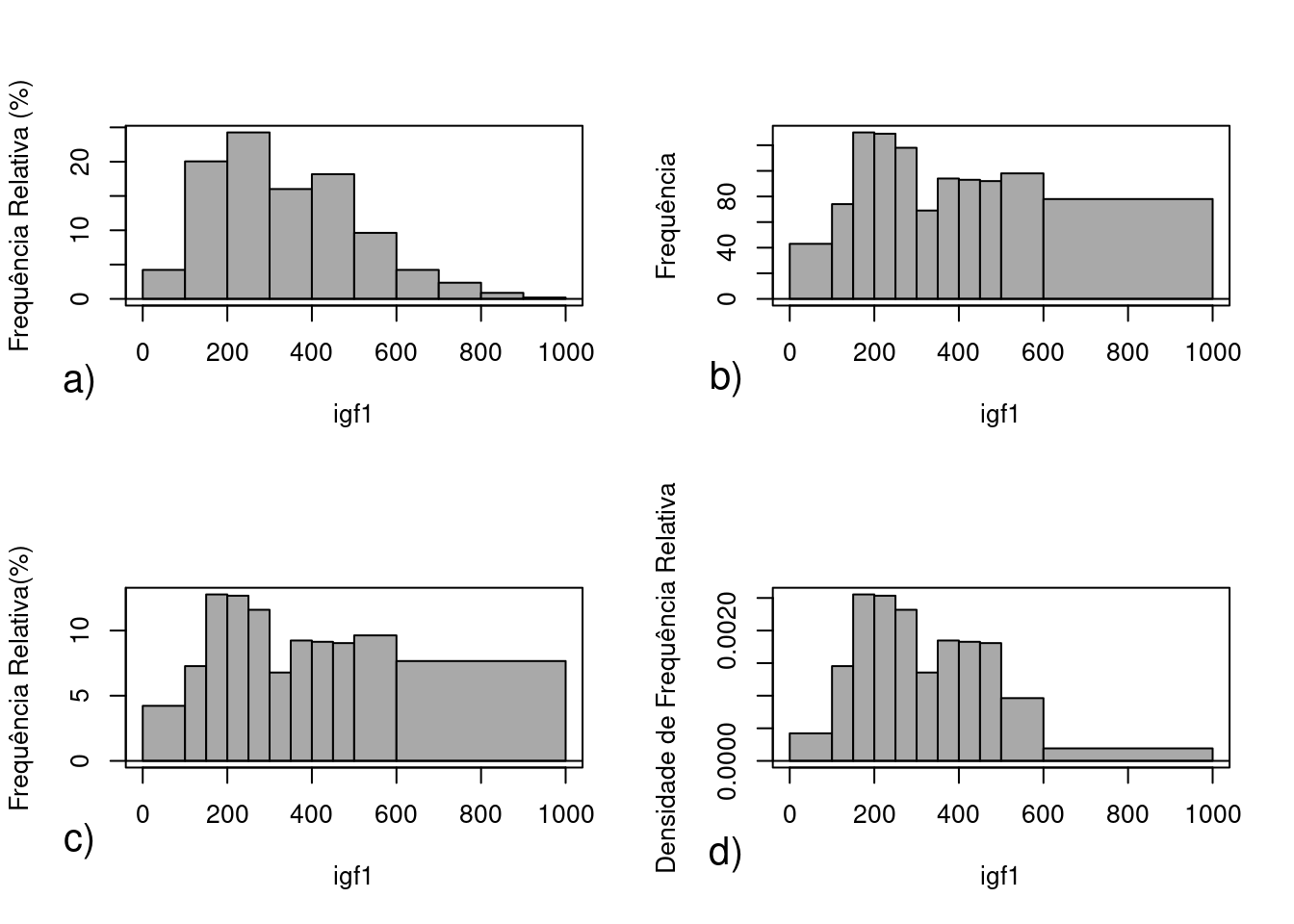
Figura 4.44: a) Histograma de frequência relativa da variável igf1 para 10 classes com igual amplitude (igual ao da figura 4.43); b) histograma de frequência da variável igf1 para as classes definidas conforme a tabela 4.2; c) histograma de frequência relativa da variável igf1 para as classes definidas conforme a tabela 4.2; d) histograma de densidade de frequência relativa da variável igf1 para as classes definidas conforme a tabela 4.2.
A função par(mfrow = c(2,2)) indica que os gráficos serão exibidos em duas colunas sendo cada linha preenchida antes de avançar para a próxima.
O histograma da figura 4.44a é idêntico ao da figura 4.43 (10 classes de mesma amplitude). Repetimos a seguir o comando usado para gerá-lo:
with(juul2, Hist(igf1, scale="percent", breaks="Sturges", col="darkgray",
ylab="Frequência Relativa (%)")) O histograma da figura 4.44b é o histograma de frequência de igf1 para as classes definidas na tabela 4.2 gerado pelo comando:
with(juul2, Hist(igf1, scale="frequency", freq = TRUE,
breaks=c(0,100,150,200,250,300,350,400,450,500, 600, 1000),
col="darkgray", ylab="Frequência")) O histograma da figura 4.44c é o histograma de frequência relativa de igf1 para as classes definidas na tabela 4.2 gerado pelo comando:
with(juul2, Hist(igf1, scale="percent", freq = TRUE,
breaks=c(0,100,150,200,250,300,350,400,450,500, 600, 1000),
col="darkgray", ylab="Frequência Relativa(%)")) No histograma de frequência, a altura de cada classe é igual ao número de valores nela contidos. No histograma de frequência relativa, a altura é a proporção de valores contidos na classe (contagem de valores / número total de valores), eventualmente multiplicada por 100 para ser expressa em porcentagem. Assim tanto o histograma de frequência quanto o de frequência relativa possuem a mesma forma, diferindo apenas na escala do eixo Y.
Quando a amplitude das classes são diferentes, porém, o histograma de frequência (e o de frequência relativa) dão uma visão distorcida da distribuição dos valores da variável. Observem que uma mensagem aparece na área de mensagens para esses dois histogramas com o seguinte teor:
AVISO: Warning in plot.histogram(r, freq = freq1, col = col, border = border, angle = angle, the AREAS in the plot are wrong – rather use ‘freq = FALSE’
Essa mensagem indica que a distorção é causada porque cada classe de um histograma deve ter a altura tal que a área de cada classe (altura x amplitude) deve ser proporcional à frequência (ou frequência relativa) de cada uma delas. Não é o que acontece nos histogramas das figuras 4.44b e 4.44c. Por exemplo, as áreas das classes 10 e 11 na figura 4.44b deveriam ser proporcionais a 78 (frequência da classe 11) e 98 (frequência da classe 1) respectivamente, ou seja, as áreas deveriam ser iguais, respectivamente, a 78 e 98, multiplicadas por uma constante qualquer. No entanto a área da classe 11 é igual a 400 x 78, e a área da classe 10 é 100 x 98, indicando que o número que multiplica a altura da classe 11 é 4 vezes maior do que o número que multiplica a altura da classe 10, distorcendo a distribuição dos valores da variável. Fato semelhante ocorre no histograma de frequência relativa (figura 4.44c). Para contornar esse problema, quando as classes possuem amplitude diferentes, utiliza-se o conceito de densidade de frequência relativa. Nesse caso, para cada classe, divide-se a sua frequência relativa pela sua amplitude, obtendo-se os valores na última coluna da tabela 4.2.
Com o comando a seguir, obtemos o histograma de densidade de frequência relativa para a variável igf1, com as classes definidas na tabela 4.2 (figura 4.44d):
with(juul2, Hist(igf1, scale="density",
breaks=c(0,100,150,200,250,300,350,400,450,500, 600, 1000),
col="darkgray", ylab="Densidade de Frequência Relativa(%)")) Observem agora que a altura da classe 11 é relativamente bem menor do que a das demais classes, refletindo o fato de que os 78 valores dessa classe estão distribuídos em uma faixa maior de valores do que as demais classes.
A execução da função par(mfrow = c(1,1)) a seguir indica que os gráficos voltarão a ser exibidos na forma normal.
4.6.2 Histograma por grupos
Da mesma forma que boxplots, é possível gerar histogramas de uma variável numérica para cada categoria de uma variável categórica. Por exemplo, para criarmos um histograma de igf1 para cada categoria de Tanner, clicamos no botão Gráfico por grupos na figura 4.41 e selecionamos a variável tanner_cat na caixa de diálogo Grupos (figura 4.45). Os histogramas de igf1 para cada categoria de Tanner são mostrados na figura 4.46.
Figura 4.45: Selecionando uma variável de agrupamento para a construção de histogramas.
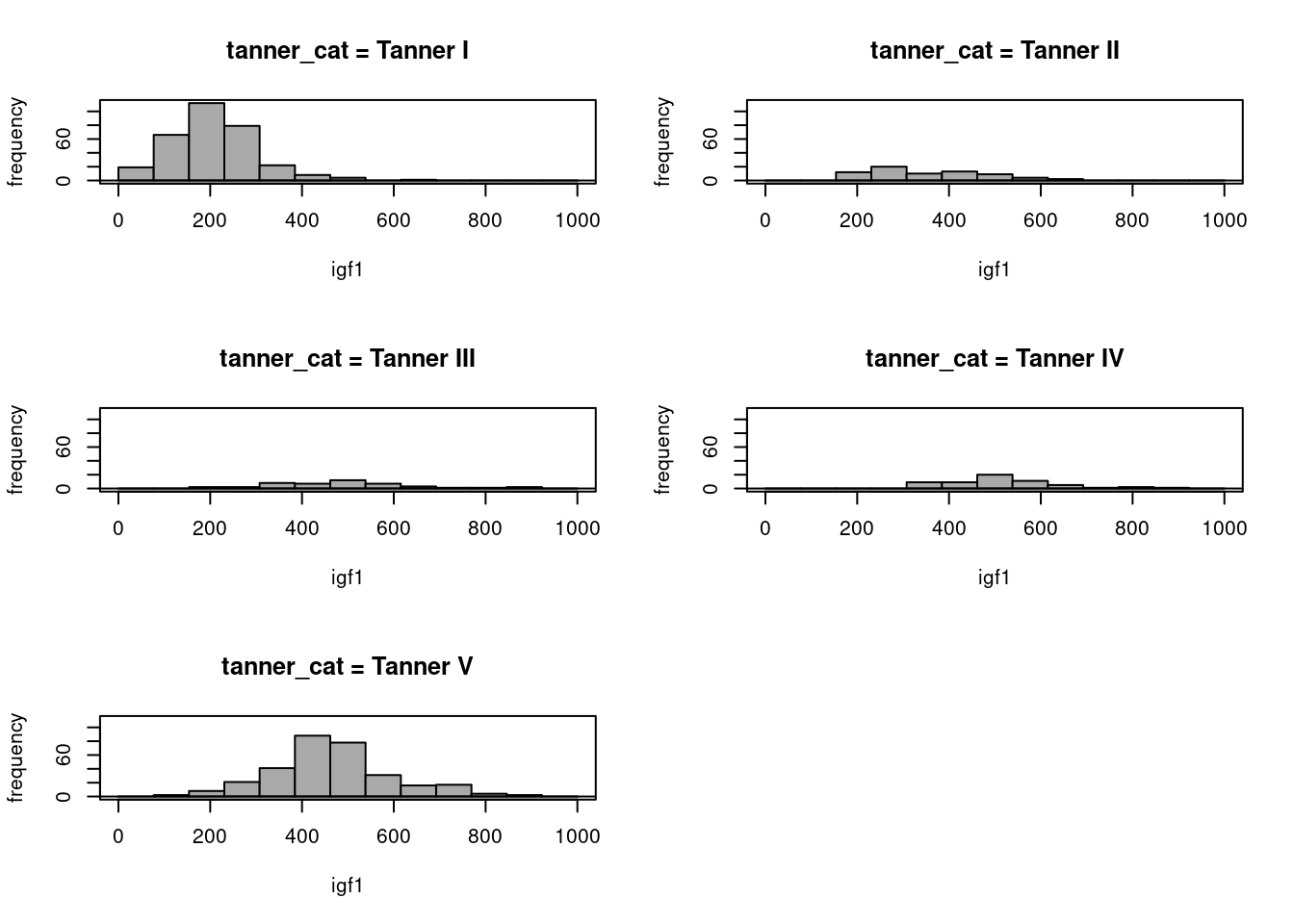
Figura 4.46: Histogramas de igf1 para cada categoria de Tanner.
4.7 Diagrama de pontos e strip chart
O conteúdo desta seção pode ser visualizado neste vídeo.
O diagrama de pontos também fornece um visão da distribuição dos valores de uma variável numérica. Ele pode ser apresentado de formas diferentes. Para criar um diagrama de pontos, acessamos como sempre o menu Gráficos e selecionamos a opção:
\[\text{Gráficos} \Rightarrow \text{Diagrama de Pontos}\]
Na caixa de diálogo do gráfico de pontos (figura 4.47), podemos selecionar a variável desejada e uma variável para criar um gráfico de pontos para cada categoria de outra variável (Gráfico por grupos). Nesse exemplo, selecionamos igf1 como a variável desejada e tanner_cat como a variável de agrupamento. O diagrama resultante é mostrado na figura 4.48.
Figura 4.47: Caixa de diálogo para a criação de um diagrama de pontos. Na aba Dados, selecionamos a variável numérica desejada. Ao clicarmos no botão Gráfico por grupos, podemos selecionar uma variável de agrupamento.
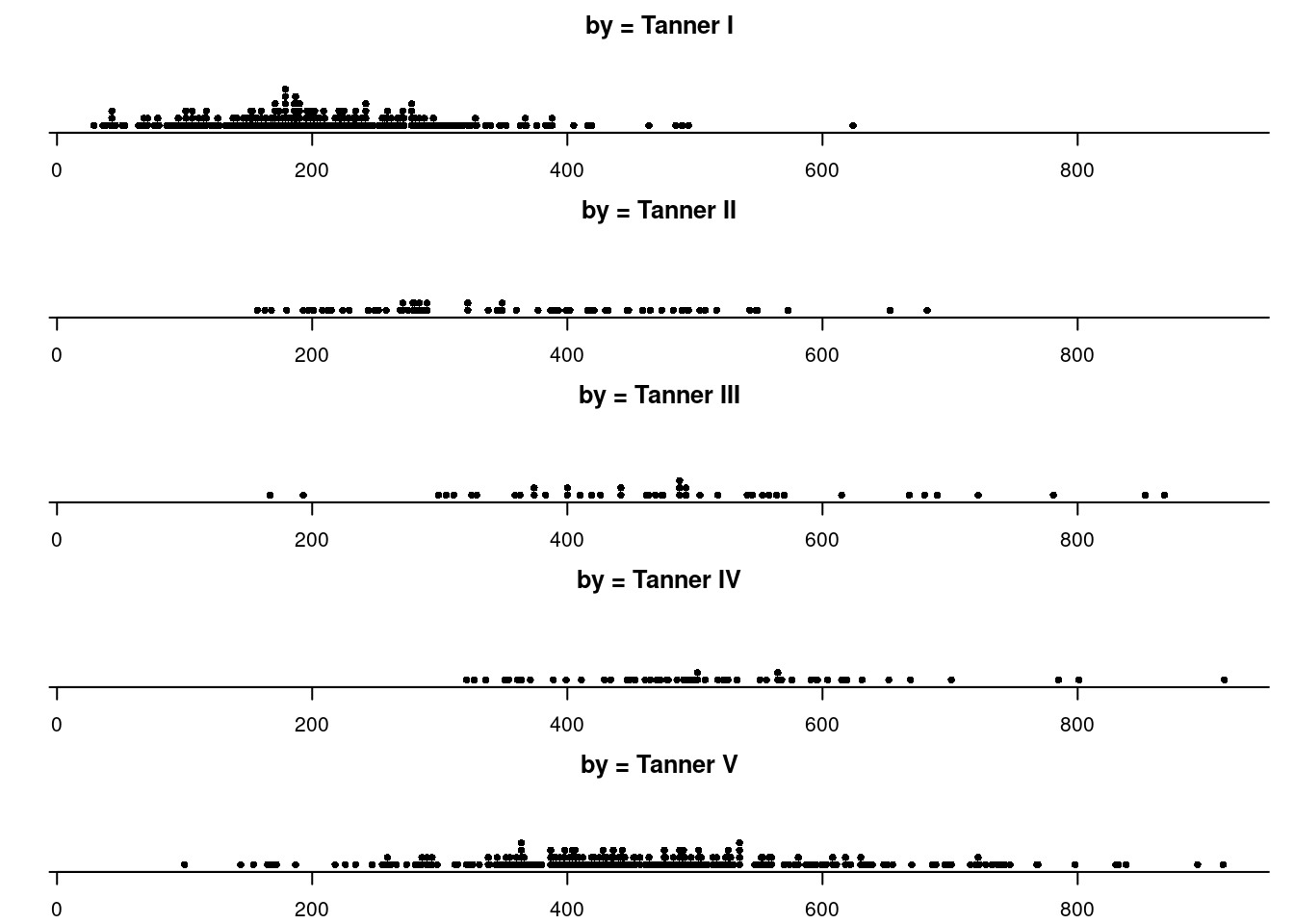
Figura 4.48: Diagrama de pontos de igf1 para cada categoria de Tanner.
Uma forma alternativa de visualizar as distribuições de pontos é plotar os pontos ao longo de uma linha vertical para cada grupo. Isso pode ser feito por meio do diagrama de strip chart, que pode ser configurado com a opção:
\[\text{Gráficos} \Rightarrow \text{Gráfico Strip Chart}\]
Na caixa de diálogo da figura 4.49, selecionamos a variável numérica (variável resposta) e a(s) variável(is) de agrupamento (fatores), se desejado.
Figura 4.49: Caixa de diálogo para a criação de um diagrama de strip chart. Na aba Dados, selecionamos a variável numérica e a variável de agrupamento, se desejado.
O gráfico é mostrado na figura 4.50.
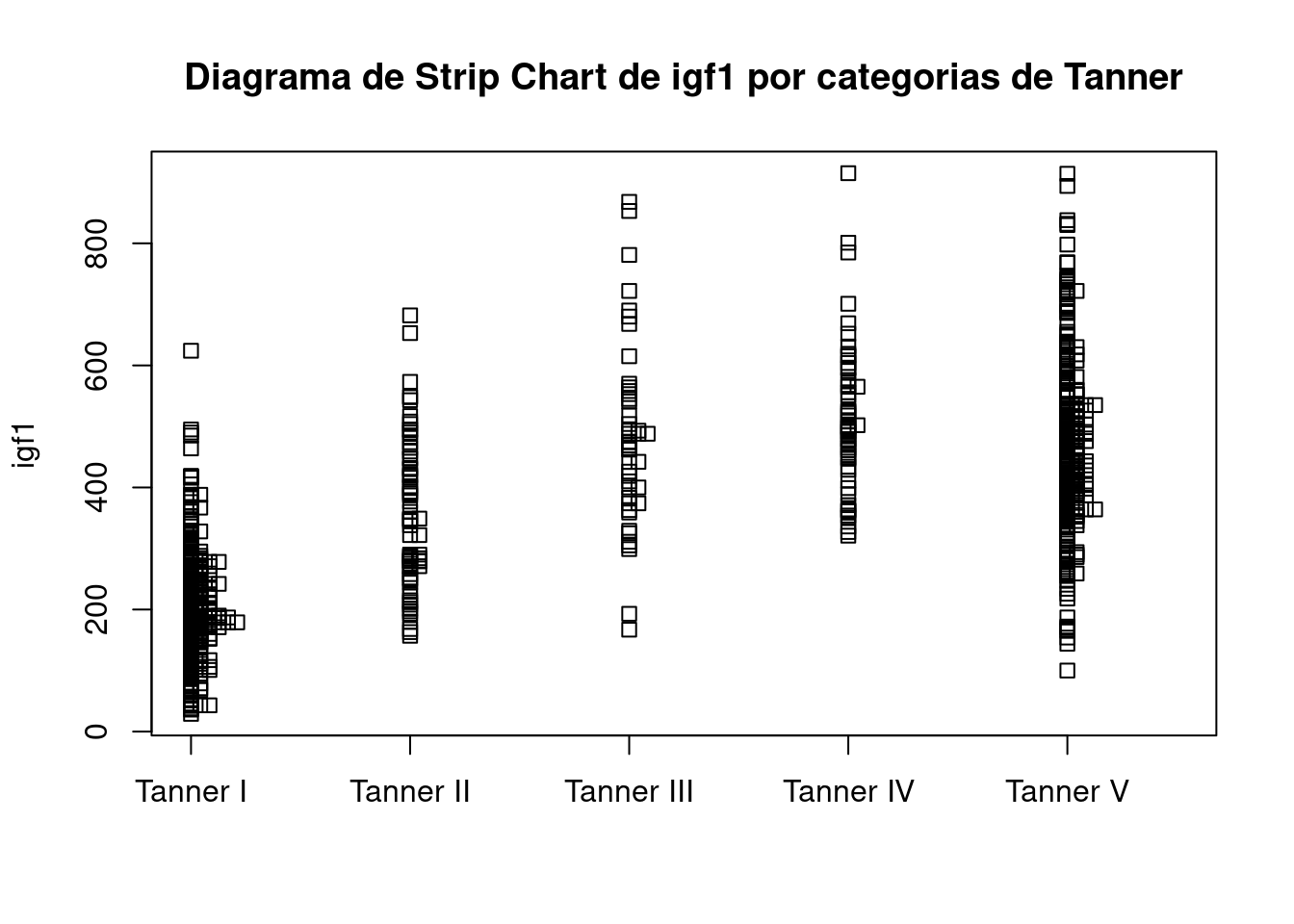
Figura 4.50: Diagrama de strip chart de igf1 para cada categoria de Tanner.
Essencialmente os diagramas 4.48 e 4.50 apresentam a mesma mensagem do que os boxplots da figura 4.40.
4.8 Diagrama de dispersão ou espalhamento
O conteúdo desta seção pode ser visualizado neste vídeo.
O diagrama de dispersão ou espalhamento é bastante utilizado para mostrar o relacionamento entre duas variáveis numéricas. Ele simplesmente plota os pontos no plano de coordenadas XY, sendo uma variável escolhida para o eixo X e outra para o eixo Y. Vamos criar o diagrama de dispersão das variáveis igf1 x idade. No menu Gráficos do R Commander, selecionamos a opção:
\[\text{Gráficos} \Rightarrow \text{Diagrama de Dispersão}\]
Na caixa de diálogo Gráfico de Dispersão, selecionamos as variáveis dos eixo X e Y na aba Dados (figura 4.51). Também podemos selecionar uma variável de agrupamento, para criar um diagrama de dispersão para cada categoria de uma outra variável. Nesse exemplo, não vamos fazer gráficos por grupos. Na aba Opções (figura 4.52), há uma série de opções que podem ser selecionadas. Marquemos a opção Linha de quadrados mínimos. Ao clicarmos em OK, o gráfico resultante é mostrado na figura 4.53.
Figura 4.51: Caixa de diálogo para a criação de um diagrama de dispersão. Na aba Dados, selecionamos as variáveis numéricas dos eixos X e Y.
Figura 4.52: Aba Opções da caixa de diálogo do gráfico de dispersão.
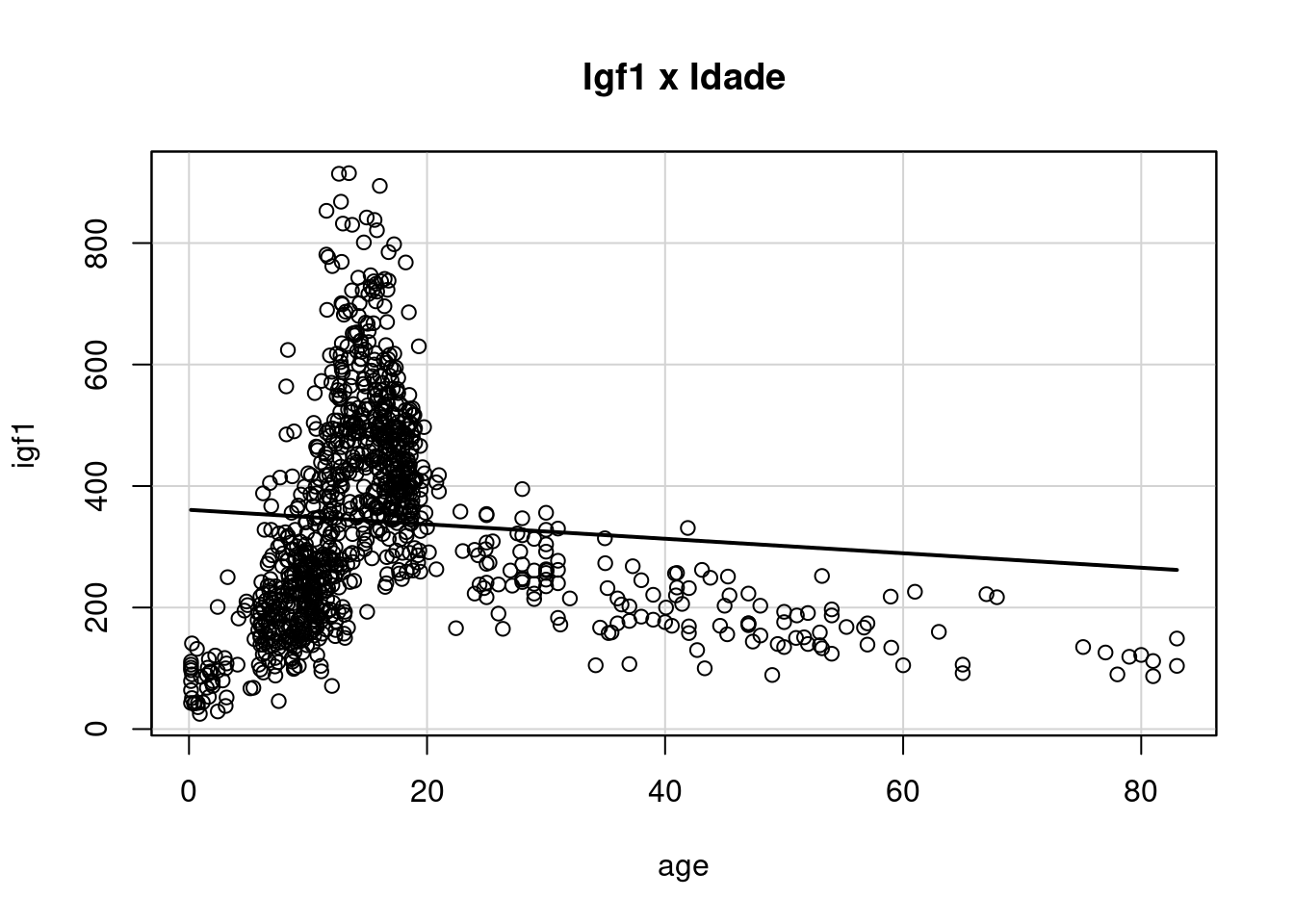
Figura 4.53: Diagrama de dispersão das variáveis igf1 x age.
Esse diagrama de dispersão sugere que o hormônio igf1 tende a aumentar com a idade até o final da adolescência e, após esse período, ele tende a decrescer com a idade. Entretanto a mesma observação ao final da seção do diagrama de boxplot se aplica aqui.
A reta de regressão é construída de modo a ajustar uma reta aos dados em um diagrama de espalhamento. Como visivelmente a idade não está linearmente associada a igf1, a reta de regressão nesse exemplo não reflete como a idade está associada à variável igf1.
4.8.1 Alterando a espessura e cor da linha de regressão e o tipo dos pontos
A espessura e a cor da linha de regressão podem ser alteradas por meio do argumento regLine. Se quisermos fazer a espessura ser o dobro da original e a cor azul, por exemplo, temos que fazer regLine=list(lwd = 4, col = "blue"). O argumento lwd (line width) especifica a espessura e o padrão é igual a 2.
O tipo dos pontos pode ser alterado por meio do argumento pch. Fazendo pch = 19, por exemplo, irá plotar pontos cheios. Esta página mostra uma tabela dos símbolos com os respectivos números. Vide comando a seguir e figura 4.54:
scatterplot(igf1~age, regLine=list(lwd = 2, col = "blue"), smooth=FALSE,
boxplots=FALSE, main="Igf1 x Idade", data=juul2,
col = "black", pch = 19)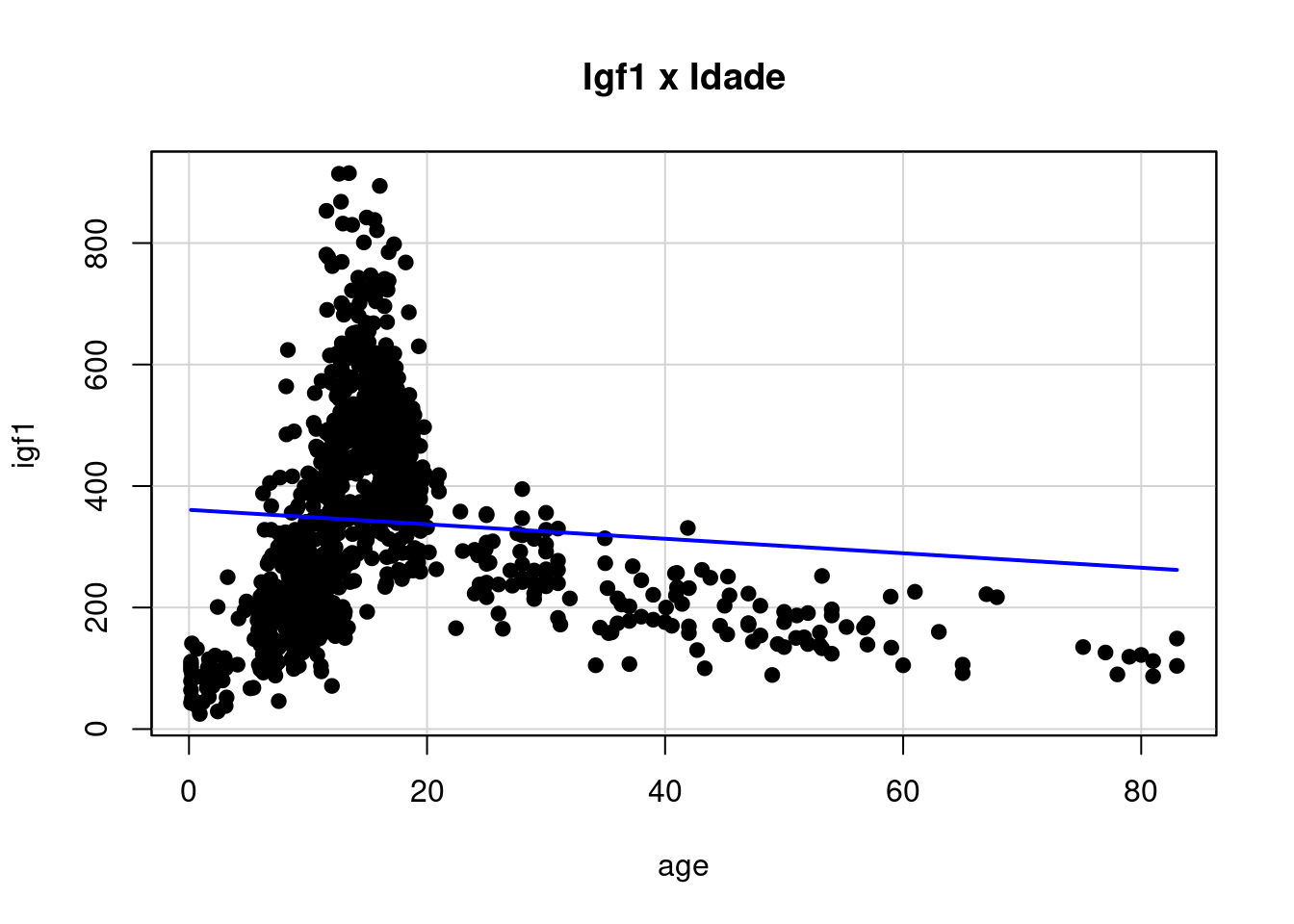
Figura 4.54: Diagrama de dispersão das variáveis igf1 x age, com pontos cheios e reta azul.
Ao selecionarmos as variáveis numéricas que serão plotadas no diagrama de dispersão, podemos distinguir os pontos e as retas de regressão por categorias de uma variável categórica. Ao clicarmos no botão Gráfico por grupos… (figura 4.51), podemos selecionar uma variável de agrupamento. Selecionando a variável tanner_cat e configurando as opções do gráfico como mostra a figura 4.55, o resultado é mostrado na figura 4.56.
Figura 4.55: Aba Opções da caixa de diálogo do gráfico de dispersão.
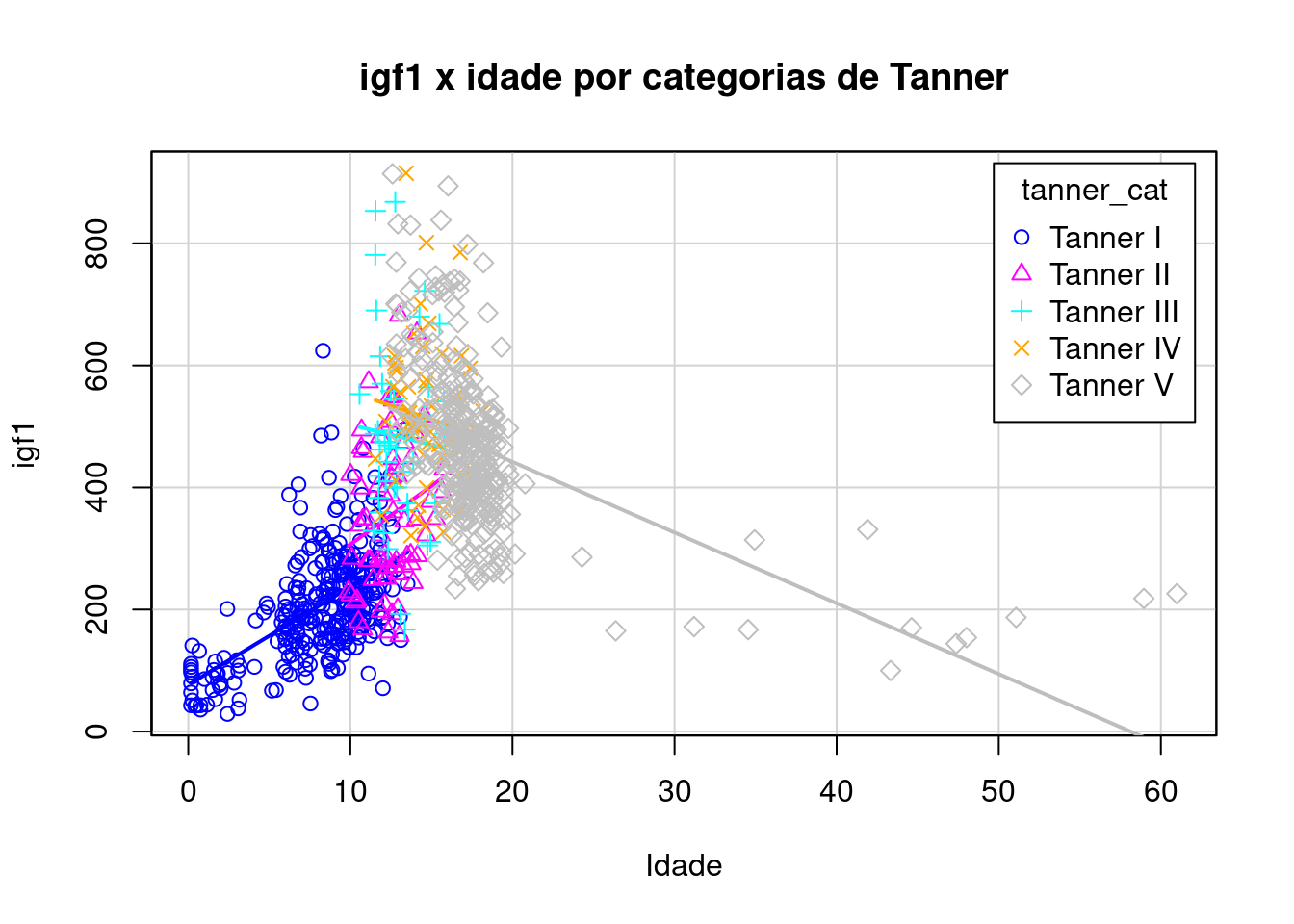
Figura 4.56: Diagrama de dispersão das variáveis igf1 x age por categorias de Tanner.
É possível observar que, dentro de cada categoria de Tanner, com exceção da categoria I, não é tão evidente qual é a relação entre igf1 e a idade. Na categoria I, aparentemente, igf1 tende a aumentar com a idade.
4.9 Salvando gráficos em um arquivo
No RStudio, os gráficos são exibidos na aba Plots (figura 4.57). Nessa aba, o usuário pode navegar entre os diversos gráficos que foram gerados na sessão corrente (seta vermelha na figura), bem como salvar o gráfico como imagem, pdf ou copiar para a área de transferência (seta verde). Ao selecionarmos a opção Salvar como imagem, surge uma tela que permite ao usuário configurar uma série de opções sobre como o gráfico será gravado.
Figura 4.57: Aba Plots do RStudio com opções para navegar pelos gráficos, ampliar e exportar os gráficos para diferentes formatos.
A caixa de diálogo mostrada na figura 4.58 permite ao usuário selecionar o formato da imagem a ser gravada (png, tiff, jpeg, bmp, svg, eps), a largura e a altura da figura, o nome do arquivo e o diretório (pasta) onde o arquivo será gravado. Ao clicarmos em Save, o arquivo será gravado no local especificado.
Figura 4.58: Tela para configurar as opções de exportação de um gráfico no RStudio.
No R Commander, para gravarmos o gráfico em um arquivo, utilizamos a opção:
\[\text{Gráficos} \Rightarrow \text{Salvar Gráfico em arquivo} \Rightarrow \text{Como Bitmap}\]
A caixa de diálogo mostrada na figura 4.59 permite ao usuário selecionar o formato da imagem a ser gravada (png ou jpeg), a largura e a altura da figura, o tamanho do texto e a resolução. Ao clicarmos em OK, será mostrada uma tela para o usuário especificar o nome do arquivo e o local no disco onde o mesmo será gravado.
Figura 4.59: Tela para configurar as opções de exportação de um gráfico no R Commander.
O comando gerado pelo R Commander é mostrado a seguir:
dev.print(png, filename="/home/sergio/temp/grafico.png", width=6, height=6,
pointsize=12, units="in", res=300) Para salvarmos o gráfico com uma resolução maior do que 300 dpi, basta alterarmos o valor do argumento res.
4.10 Recursos gráficos de outros plugins
O R Commander oferece uma maneira fácil de construir alguns tipos de gráficos. Porém cada tipo de gráfico possui diversos outros recursos que podem ser utilizados, mas que não são apresentados na interface gráfica. Nesse caso, há outras possibilidades: a) utilizar outros plugins que possuem mais recursos na sua interface gráfica; b) digitar o comando que cria o gráfico na janela de script, com as alterações para criar o efeito gráfico desejado; c) utilizar outros pacotes com mais recursos, como o ggplot2 (MIT License). Nesta seção, vamos mostrar como carregar outros plugins no R Commander.
Na sua própria interface gráfica, o R Commander pode acrescentar outros plugins, com recursos variáveis, inclusive gráficos. Vamos aqui mostrar um desses plugins, o RcmdrPlugin.KMggplot2. O processo de carregamento desse plugin é semelhante para os demais.
Para carregarmos um novo plugin, é preciso que ele esteja instalado. Para instalarmos um plugin, o procedimento é o mesmo para instalar qualquer pacote do R. Uma vez instalado o plugin, acessamos a opção:
\[\text{Ferramentas} \Rightarrow \text{Carregar plugins do Rcmdr}\]
Na caixa de diálogo Carregar Plug-ins, selecionamos o plugin desejado, ou os plugins, e clicamos em OK (figura 4.60). Caso um plugin desejado não apareça nessa lista, ele precisará ser instalado.
Figura 4.60: Diálogo para selecionar e carregar um novo plugin no R Commander.
Para carregarmos qualquer plugin, será necessário reinicar o R Commander (figura 4.61).
Figura 4.61: É necessário reiniciar o R Commander para carregar um novo plugin.
Ao reiniciarmos o R Commander, se algum conjunto de dados estava sendo usado, ele não está mais ativo. É preciso ativá-lo. Para escolhermos o conjunto de dados que estará ativo no R Commander, selecionamos a opção:
\[\text{Dados} \Rightarrow \text{Conjunto de dados ativo} \Rightarrow\ \text{Selecionar conjunto de dados ativo...}\]
Neste capítulo, estamos trabalhando com o conjunto de dados juul2. Ele aparece na lista de conjuntos de dados disponíveis (figura 4.62). Selecionamos o conjunto juul2 e clicamos no botão OK. juul2 será ativado e poderemos acessar o menu do Kmggplot2 (figura 4.63). Observem as opções de gráficos desse plugin, experimentem e vejam as diferenças em relação aos recursos padrões do R Commander.
Figura 4.62: Seleção do conjunto de dados a ser ativado.
Figura 4.63: Plugin Kmggplot2 com diversos recursos para a criação de gráficos.
4.11 Exercícios
O diagrama de barras da figura 4.64 mostra a porcentagem de mulheres cujos bebês foram internados em uma UTI neonatal em diversas faixas de escolaridade e estratificada de acordo com o critério se tiveram ou não doença hipertensiva específica da gravidez (DHEG). Responda às questões abaixo.
- Qual a faixa de escolaridade mais frequente?
- Qual a porcentagem aproximada da faixa de escolaridade de 4-7 anos?
- Qual a porcentagem aproximada de mulheres na faixa de escolaridade >12 anos e que tiveram DHEG?
- A partir do diagrama, que relação é sugerida entre a escolaridade e a DHEG? Comente sobre essa relação.
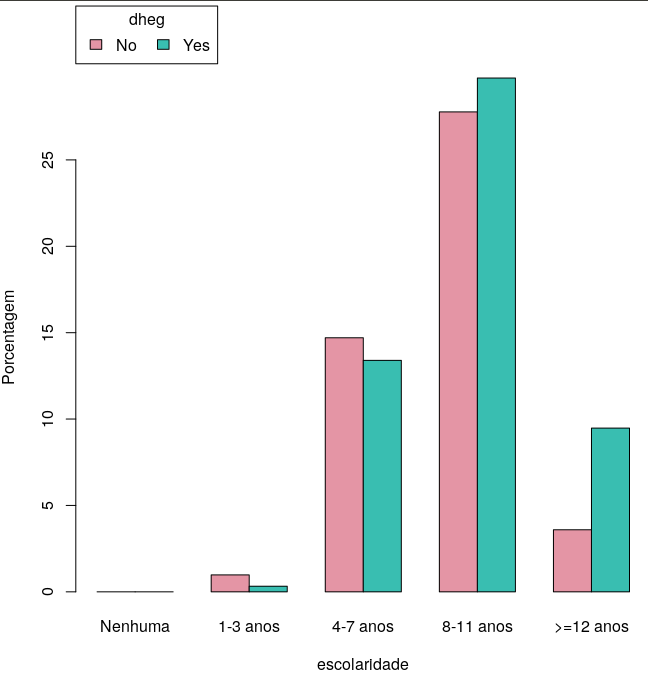
Figura 4.64: Diagrama de barras Escolaridade X DHEG.
Os dois gráficos da figura 4.65 representam um diagrama de barras para as variáveis peso ao nascimento de recém-nascidos internados em uma UTI neonatal e do número de visitas no pré-natal das respectivas mães.
- Faça uma crítica sobre a adequabilidade dos dois gráficos em mostrar a distribuição dos dados das respectivas variáveis.
- Que conclusões você pode tirar sobre o uso do diagrama de barras para ilustrar a distribuição dos dados para variáveis numéricas?
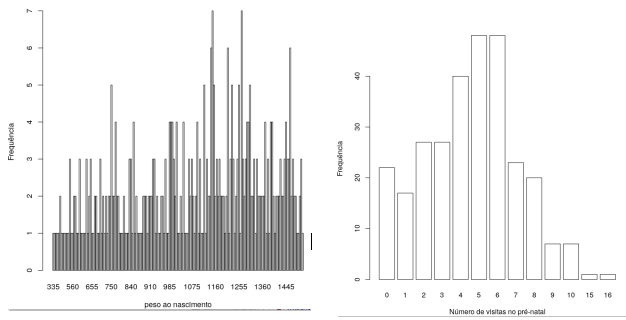
Figura 4.65: Diagrama de barras para variáveis numéricas: a) peso ao nascimento , b) número de visitas no pré-natal.
Os três gráficos da figura 4.66 são histogramas da idade gestacional de recém-nascidos que foram internados em uma UTI neonatal. Todos os histogramas foram criados com classes de mesma amplitude.
- O que representa cada barra no histograma superior à esquerda?
- Qual a diferença entre os histogramas?
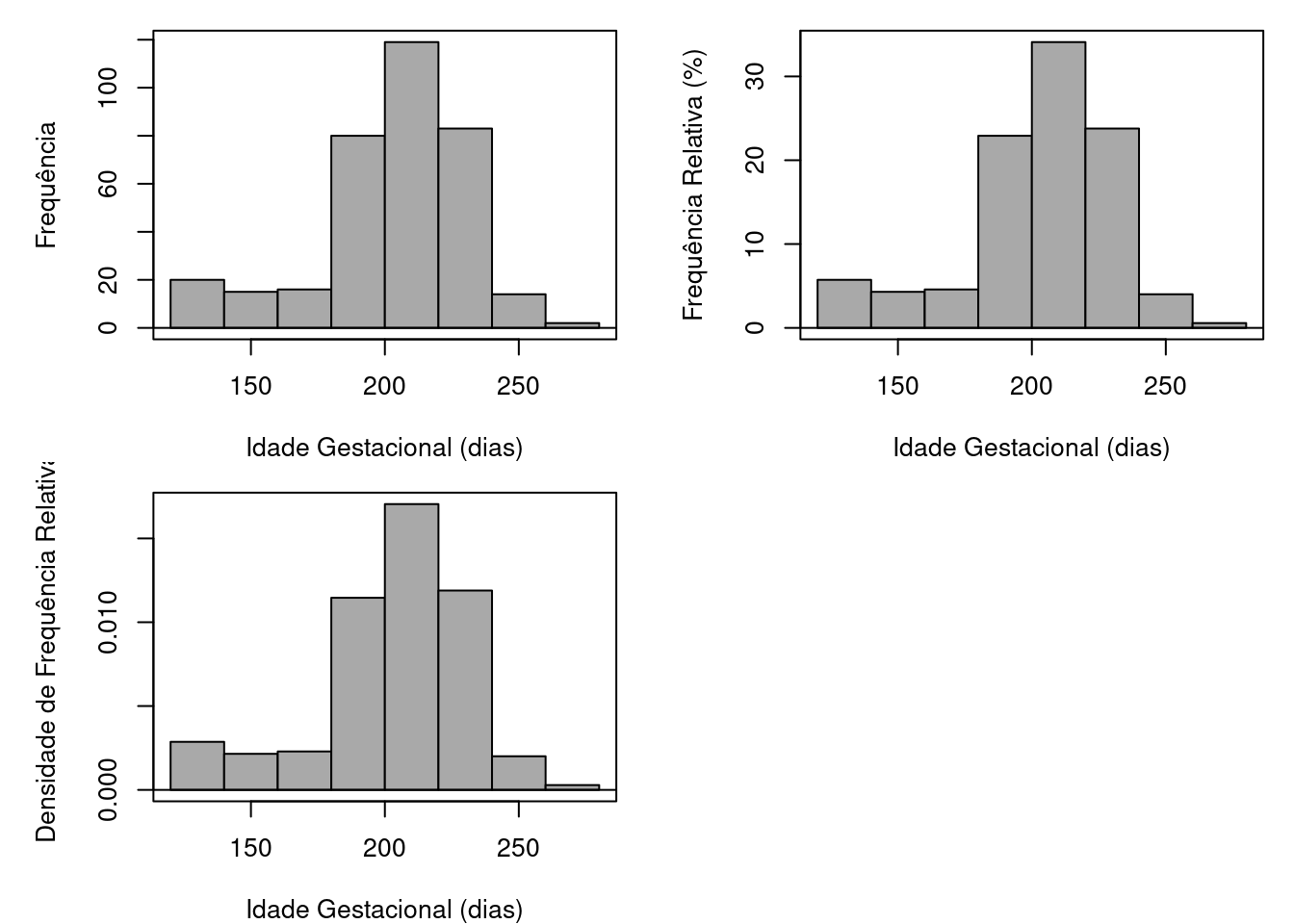
Figura 4.66: Histogramas da idade gestacional de recém-nascidos internados em uma UTI neonatal.
Os quatro gráficos da figura 4.67 são histogramas da idade gestacional de recém-nascidos que foram internados em uma UTI neonatal.
- Quais são as diferenças entre os histogramas?
- Que histogramas melhor refletem a distribuição dos dados? Justifique.
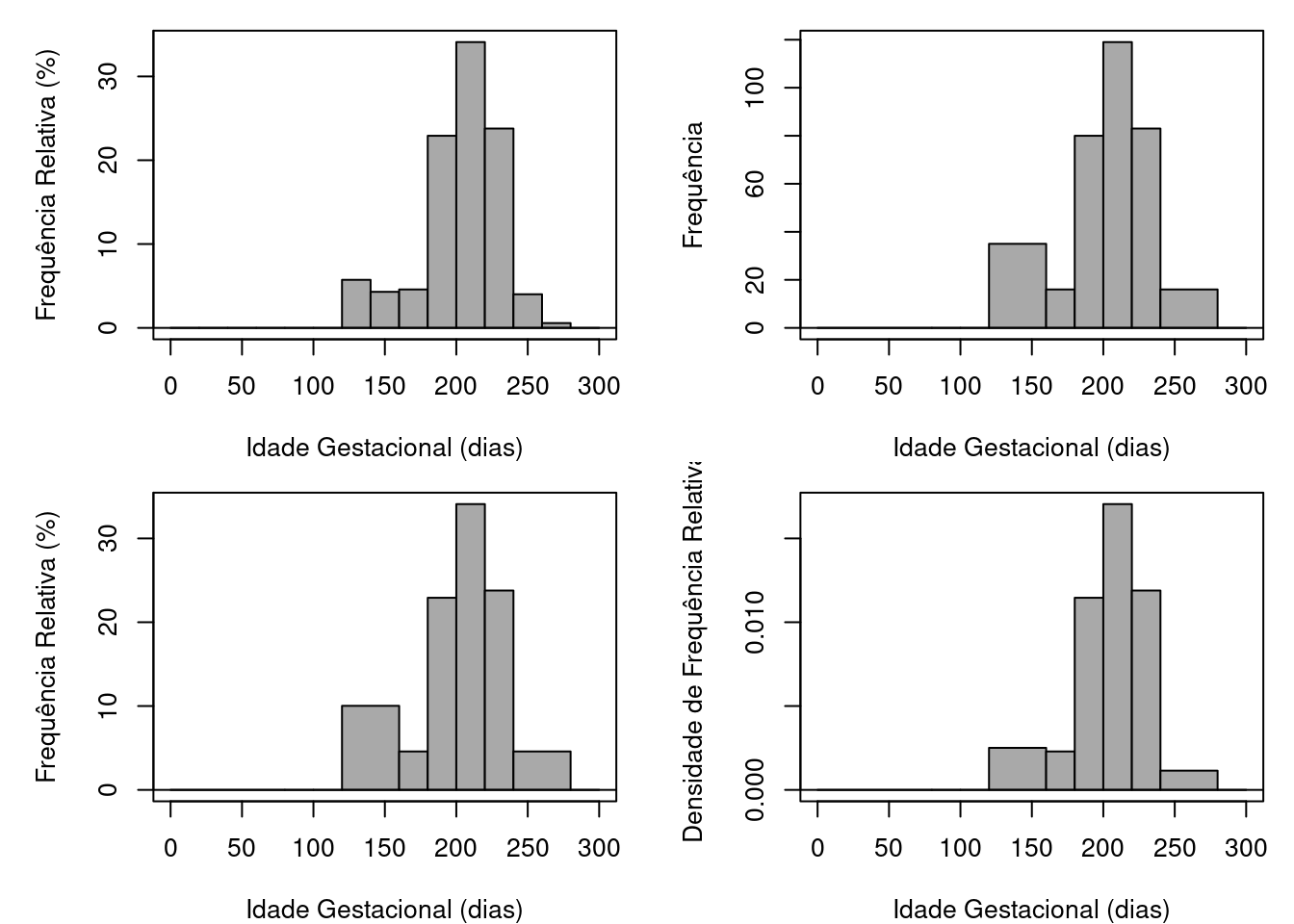
Figura 4.67: Histogramas da idade gestacional de recém-nascidos internados em uma UTI neonatal.
O gráfico da figura 4.68 mostra os resultados de 5 experimentos para medir a velocidade da luz. Responda às questões abaixo.
- O que significa a linha mais espessa no interior de cada caixa?
- O que significam as linhas superior e inferior que delimitam as caixas?
- O que significam as linhas superior e inferior fora das caixas?
- Por que os experimentos 1 e 3 contêm alguns pontos representados por círculos e os demais não?
- Por que as linhas tracejadas no experimento 2 não possuem o mesmo comprimento?
- Qual experimento mostrou maior variabilidade ? E a menor? Que critério você utilizou para avaliar a variabilidade dos dados?
- Que experimento teve a menor mediana? E a maior?
- Indique os experimentos em que a média e o desvio padrão poderiam ser utilizadas como boas medidas de tendência central e dispersão.

Figura 4.68: Boxplots de experimentos para medir a velocidade da luz. Fonte: wikipedia (Domínio Público).
{kind=link}
Carregue o conjunto de dados Pima.te do pacote MASS (GPL-2 | GPL-3).
- Veja a ajuda do conjunto de dados.
- Use o comando ao final do exercício para gerar uma variável, glu_cat, com as seguintes faixas de glicose: (0-99], (99-120] e >120 mg/dl.
- Faça um diagrama de barras diagrama de barras condicional, lado a lado com as porcentagens da variável type para cada categoria da variável glu_cat. Comente o gráfico.
- Faça um boxplot da variável glu para cada categoria da variável type. Comente o diagrama.
- Faça um histograma da variável glu para cada categoria da variável type. Comente o diagrama.
- Faça um diagrama de stripchart da variável bmi por categoria da variável type. Comente o gráfico.
- Faça um diagrama de dispersão de glu por bmi. Comente o gráfico.