12 Avaliação de testes diagnósticos
12.1 Introdução
Os conteúdos desta seção, do início da seção 12.2 e da seção 12.2.1 podem ser visualizados neste vídeo.
Na prática clínica, o uso de um teste diagnóstico necessita de uma avaliação de quanto esse teste é capaz de distinguir quem tem uma doença de quem não tem. Esse teste é comparado com o padrão-ouro, ou seja, o método padrão de diagnóstico utilizado até então.
Na avaliação da qualidade dos estudos de testes diagnósticos, algumas perguntas devem ser respondidas para se conhecer a validade dos resultados:
Foi feita uma comparação independente e cega com o teste padrão (padrão-ouro)?
Os pacientes representam a população do local onde o teste será usado?
O método do teste é adequadamente descrito e permite ser reproduzido?
Nesse sentido, a avaliação de um teste diagnóstico baseia-se na sua relação com algum meio de saber se a doença está ou não realmente presente – um indicador mais fiel da verdade é referido como padrão-ouro.
Critérios e métricas para a avaliação de testes diagnósticos são apresentados em diversas publicações, por exemplo (Fletcher, Fletcher, and Fletcher 2014) e (Guyatt et al. 2008). As métricas mais utilizadas para avaliar quantitativamente a qualidade de testes diagnósticos são a sensibilidade, especificidade, valores preditivos positivo e negativo, ou alternativas como a razão de verossimilhança e chance pós-teste. Os textos apresentam normogramas para obter a chance pós-teste a partir da razão de verossimilhança e a chance pré-teste (Fletcher, Fletcher, and Fletcher 2014), (Guyatt et al. 2008), e gráficos que mostram a influência da probabilidade pré-teste, da sensibilidade e da especificidade sobre os valores preditivos positivo e negativo, bem como a relação entre a sensibilidade e a especificidade para diferentes pontos de corte de um teste cujo resultado é uma variável numérica (curva ROC) (Owens and Sox 2014).
Neste capítulo, serão apresentadas as métricas mais utilizadas para a avaliação de testes diagnósticos, considerando as seguintes situações:
o resultado do teste é expresso por uma variável dicotômica;
o resultado do teste é expresso por uma variável categórica com mais de duas categorias;
o resultado do teste é expresso por uma variável numérica contínua.
12.2 Teste dicotômico
Para avaliar um teste diagnóstico cujo resultado é dicotômico, dois esquemas de amostragem são frequentemente utilizados.
No primeiro esquema, selecionam-se uma amostra de pessoas com a doença e uma outra amostra de pessoas sem a doença, com diagnóstico estabelecido de acordo com o padrão-ouro, às quais são submetidas ao teste diagnóstico a ser avaliado (figura 12.1). Nessa figura, \(a\) pessoas doentes foram consideradas positivas de acordo com o teste, \(c\) pessoas doentes foram consideradas negativas pelo teste, \(b\) pessoas não doentes foram consideradas positivas pelo teste e \(d\) pessoas não doentes foram consideradas negativas pelo teste.
Apesar de a amostragem ser típica de um estudo de caso-controle, as medições são realizadas como em um estudo transversal, ou seja, em um curto lapso de tempo entre uma e outra medição, de modo que as medições possam ser consideradas como contemporâneas.
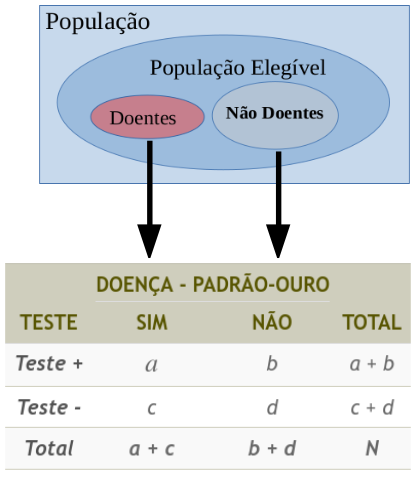
Figura 12.1: Avaliação de um teste diagnóstico com resultado dicotômico, utilizando uma amostragem típica de um estudo de caso-controle.
No segundo esquema, seleciona-se uma amostra de pessoas a partir de uma população elegível, às quais são submetidas tanto ao teste diagnóstico em avaliação quanto ao padrão-ouro (figura 12.2). As frequências das células da tabela 2x2 são calculadas de modo análogo ao da tabela mostrada na figura 12.1.
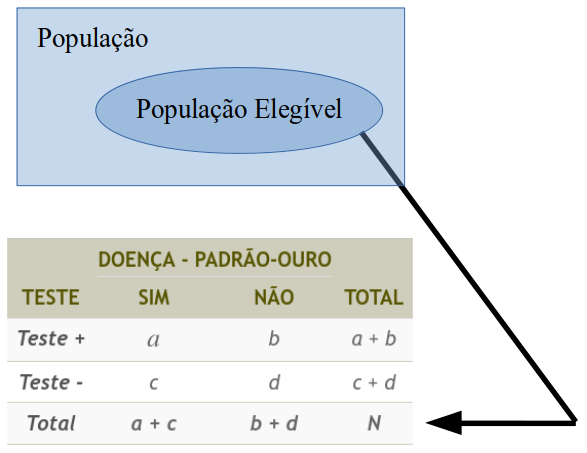
Figura 12.2: Avaliação de um teste diagnóstico com resultado dicotômico, utilizando uma amostragem típica de um estudo transversal.
Independentemente do esquema de amostragem, os resultados podem ser apresentados conforme a tabela 12.1, onde quatro situações podem ocorrer:
o resultado do teste é positivo e a doença está realmente presente: verdadeiro positivo;
o resultado do teste é positivo, mas a doença não está presente: falso positivo;
o resultado do teste é negativo, mas a doença está presente: falso negativo;
o resultado do teste é negativo e a doença realmente não está presente: verdadeiro negativo.
| Presente (D) | Ausente (\(\bar{D}\)) | ||
|---|---|---|---|
| Teste | Positivo (T+) | Verdadeiro Positivo (\(a\)) | Falso Positivo (b) |
| Teste | Negativo (T-) | Falso Negativo (c) | Verdadeiro Negativo (d) |
Duas medidas intrínsecas ao teste frequentemente usadas são: a sensibilidade e a especificidade.
12.2.1 Sensibilidade e especificidade
A sensibilidade é a fração dos pacientes doentes que tiveram resultado positivo no teste:
\[\begin{align} \boldsymbol{Sensibilidade} = S = P(T^+|D) = \frac{a}{a+c} \tag{12.1} \end{align}\]
A especificidade é a fração dos pacientes não doentes que tiveram resultado negativo no teste:
\[\begin{align} \boldsymbol{Especificidade} = E = P(T^-|\bar{D}) = \frac{d}{b+d} \tag{12.2} \end{align}\]
Ao realizar um teste diagnóstico, o médico está interessado em saber qual é a probabilidade de o paciente ter a doença se o teste for positivo ou a probabilidade de o paciente não ter a doença se o teste for negativo. Essas duas probabilidades são conhecidas como valor preditivo positivo (VPP) e valor preditivo negativo (VPN), respectivamente. Elas não podem ser obtidas diretamente a partir da tabela 12.1 quando os grupos de doentes e não doentes são gerados por meio uma amostragem como em um estudo de caso-controle, porque as duas amostras utilizadas para gerar a tabela (doentes e não doentes) permitem estimar a sensibilidade (P[T+|D]) e a especificidade (P[T-|\(\bar{D}\)]), mas não o VPP (P[D|T+]) ou o VPN (P[\(\bar{D}\)|T-]).
Os valores preditivos positivo e negativo também não podem ser obtidos diretamente a partir da tabela 12.1 quando os grupos de doentes e não doentes são gerados por meio de uma amostragem típica de estudos transversais, se a prevalência da doença na população à qual o paciente pertence é diferente da prevalência da doença na população alvo do estudo a partir do qual as métricas de sensibilidade e especificidade foram obtidas.
12.2.2 Valores preditivo positivo e negativo
O conteúdo desta seção pode ser visualizado neste vídeo.
O valor preditivo positivo (VPP) é a probabilidade de o paciente ter a doença se o teste for positivo:
\[\begin{align} \boldsymbol{Valor\ Preditivo\ Positivo} = VPP = P(D|T^+) \tag{12.3} \end{align}\]
A expressão P(D) representa a propabilidade de o paciente ter a doença antes de realizar o teste, ou seja, a prevalência da doença (ou a probabilidade pré-teste) em um determinado contexto.
Como visto no capítulo 7, seção 7.6, o valor preditivo positivo pode ser calculado por meio do teorema de Bayes, se supusermos que os valores de sensibilidade e especificidade são independentes da probabilidade pré-teste:
\(P(D|T^+) = \frac{P(T^+|D)P(D)}{P(T^+)}\)
\(\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ = \frac{P(T^+|D)P(D)}{P(T^+ \cap D)+P(T^+ \cap \bar{D})}\)
\(\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ = \frac{P(T^+|D)P(D)}{P(T^+|D)P(D)+P(T^+|\bar{D})P(\bar{D})}\)
Portanto:
\[\begin{align} VPP = \frac{S\ .\ P_{pre-teste}}{S\ .\ P_{pre-teste}+(1-E)\ .\ (1-P_{pre-teste})} \tag{12.4} \end{align}\]
O valor preditivo negativo (VPN) é a probabilidade de o paciente não ter a doença se o teste for negativo:
\[\begin{align} \boldsymbol{Valor\ Preditivo\ Negativo} = VPN = P(\bar{D}|T^-) \tag{12.5} \end{align}\]
Seguindo um raciocínio semelhante ao utilizado para obter a expressão do VPP, chegamos à expressão para o VPN:
\(VPN = P(\bar{D}|T^-) = \frac{P(T^-|\bar{D})P(\bar{D})}{P(T^-|D)P(D)+P(T^-|\bar{D})P(\bar{D})}\)
\[\begin{align} VPN &= \frac{E\ .\ (1-P_{pre-teste})}{E(1-P_{pre-teste})+(1-S)\ .\ P_{pre-teste}} \tag{12.6} \end{align}\]
Exemplo: Vamos considerar o estudo de Malacarne et al. (Malacarne et al. 2019), que avaliou o desempenho de testes para o diagnóstico de tuberculose pulmonar em populações indígenas no Brasil. Os resultados para o teste rápido molecular (TRM) em comparação à cultura de escarro (teste padrão) para todas as amostras de escarro combinadas são mostrados na tabela 12.2.
| Teste Rápido Molecular (TRM) | Com TB (D) | Sem TB (\(\bar{D}\)) | Totais |
|---|---|---|---|
| Teste positivo (T+) | 54 | 7 | 61 |
| Teste negativo (T-) | 4 | 401 | 405 |
| 58 | 408 | 466 |
A partir da tabela 12.2, podemos calcular a sensibilidade e a especificidade do teste:
\(S = P(T^+|D)\) = 54/58 = 0,931
\(E = P(T^-|\bar{D})\) = 401/408 = 0,983
Supondo que a prevalência seja P(D) = 0,1 = 10% e substituindo os valores de S, E e P(D) na fórmula do valor preditivo positivo, temos:
\[VPP = \frac{0,931\ . 0,10}{0,931\ . 0,10+(1-0,983)(1-0,10)} = 0,858 = 85,8\%\] O fato de o teste diagnóstico dar positivo elevou a probabilidade de o paciente estar doente de 10% para 85,8%. Assim o VPP é influenciado pelos valores da sensibilidade, especificidade e da probabilidade pré-teste.
Substituindo os valores de S, E e P(D) na fórmula do valor preditivo negativo, temos:
\[VPN = \frac{0,983\ .(1- 0,10)}{0,983\ .(1- 0,10)+(1-0,931) \ . \ 0,10} = 0,992 = 99,2\%\] O fato de o teste diagnóstico ter dado negativo elevou a probabilidade de o paciente não estar doente de 90% para 99,2%. Nesse caso, como a probabilidade pré-teste de o indivíduo não ter a doença já era elevada, o fato de o teste dar negativo não alterou muito a probabilidade de o indivíduo estar doente.
12.2.3 Influência dos fatores que afetam os valores preditivos positivo e negativo
Os conteúdos desta seção e da seção 12.2.4 podem ser visualizados neste vídeo.
Para entendermos melhor a influência dos fatores que afetam os valores preditivos positivo e negativo, vamos reconstruir a tabela 12.1, mas agora expressando as suas células em termos de probabilidades (figura 12.3). Assim, na tabela 12.1, substituímos a célula 1 pela sensibilidade e a célula 3 pelo seu complemento. Analogamente, substituímos a célula 4 pela especificidade e a célula 2 pelo seu complemento.
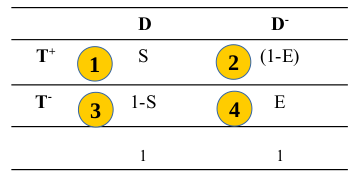
Figura 12.3: Preparação da tabela 12.1 para o cálculo do VPP e do VPN.
A partir da figura 12.3, o teorema de Bayes ajusta as células 1 e 3 de modo que a soma das duas probabilidades seja igual à probabilidade pré-teste (P[D]) e as células 2 e 4, de modo que as somas das duas probabilidades seja 1 - Ppre-teste (figura 12.4). Esse ajuste faz que com as células 1 a 4 reflitam a distribuição na população que tivesse a prevalência dada por Ppre-teste e os valores de sensibilidade e especificidade estimados a partir da tabela 12.1.
Na figura 12.4, pode-se estimar o VPP a partir das células 1 e 2, dividindo-se o valor da célula 1 pela soma das células 1 e 2, como mostrado na quarta coluna da tabela. Analogamente, pode-se estimar o VPN a partir das células 3 e 4, dividindo-se o valor da célula 3 pela soma das células 3 e 4.
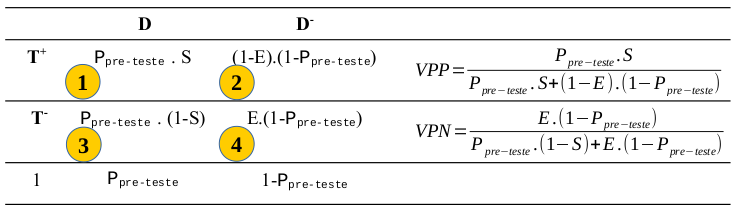
Figura 12.4: Utilização do teorema de Bayes para calcular o VPP e o VPN.
A tabela 12.3 mostra os dados do exemplo, substituídos na tabela mostrada na figura 12.4.
| D | \(\boldsymbol{\bar{D}}\) | ||
|---|---|---|---|
| T+ | 0,10 . 0,931 | (1 - 0,983).(1 - 0,10) | \(VPP = \frac{0,931\ . 0,10}{0,931\ . 0,10+(1-0,983)(1-0,10)} = 0,858\) |
| T- | 0,10 . (1 - 0,931) | 0,983(1 - 0,10) | \(VPN = \frac{0,983\ .(1- 0,10)}{0,983\ .(1- 0,10)+(1-0,931) \ . \ 0,10} = 0,992\) |
| 1 | 0,10 | 1 - 0,10 |
Os mesmos valores de VPP e VPN seriam obtidos se multiplicássemos os valores das células 1, 2, 3 e 4 pela mesma quantidade, por exemplo 100, já que essa constante será cancelada nas expressões para o VPP e VPN (tabela 12.4). Apesar de ser apenas uma mudança cosmética, é mais fácil trabalharmos com quantidades inteiras do que fracionárias.
| D | \(\boldsymbol{\bar{D}}\) | ||
|---|---|---|---|
| T+ | 10 . 0,931 | (1 - 0,983) . 90 | \(VPP = \frac{0,931\ . 10}{0,931\ . 10+(1-0,983)\ .\ 90} = 0,858\) |
| T- | 10 . (1 - 0,931) | 0,983 . 90 | \(VPN = \frac{0,983\ .\ 90}{10\ .\ (1-0,931)+0,983\ .\ 90} = 0,992\) |
| 100 | 10 | 90 |
Quanto maior o valor da sensibilidade (menor a probabilidade de falsos negativos) e maior o valor da especificidade (menor a probabilidade de falsos positivos), mais acurado o teste.
Quanto maior o valor da sensibilidade (mais próximo de 1), mais o valor da célula 3 na figura 12.4 se aproxima de zero e o VPN vai se aproximando de 1.
Assim um teste muito sensível é útil para descartar o diagnóstico se ele der negativo.
Por outro lado, quanto maior o valor de especificidade (mais próximo de 1), mais o valor da célula 2 na figura 12.4 se aproxima de zero e o VPP vai se aproximando de 1.
Assim um teste muito específico é útil para confirmar o diagnóstico se ele der positivo.
Em um processo de triagem para uma certa doença, onde se procura detectar pessoas que possam ter a doença, é interessante a utilização de testes sensíveis e que possam ser utilizados em escala mais ampla de modo a termos poucos falsos negativos. Os indivíduos que forem considerados positivos no teste serão então submetidos a um teste mais específico para confirmar o diagnóstico.
Apesar de a montagem da tabela mostrada na figura 12.4 ser equivalente à aplicação direta das fórmulas (12.4) e (12.6) para os valores VPP e VPN, respectivamente, essa tabela pode ser programada numa planilha eletrônica, por exemplo, de modo a obter rapidamente o VPP e o VPN para quaisquer combinações de sensibilidade, especificidade e probabilidade pré-teste.
12.2.4 Aplicações que mostram a influência dos determinantes de VPP e VPN
As fórmulas (12.4) e (12.6) também podem ser programadas em aplicações que permitem visualizar a influência desses parâmetros sobre o VPP e o VPN, como será mostrado nas subseções seguintes.
12.2.4.1 Influência da probabilidade pré-teste sobre os valores preditivos positivo e negativo
A figura 12.5 mostra a tela inicial da aplicação Probabilidade Pós-Teste x Probabilidade Pré-teste, Sensibilidade e Especificidade. Essa aplicação permite ao usuário visualizar como as probabilidades pós-teste (VPP e VPN) variam com a prevalência (probabilidade pré-teste) para diferentes valores de sensibilidade e especificidade.
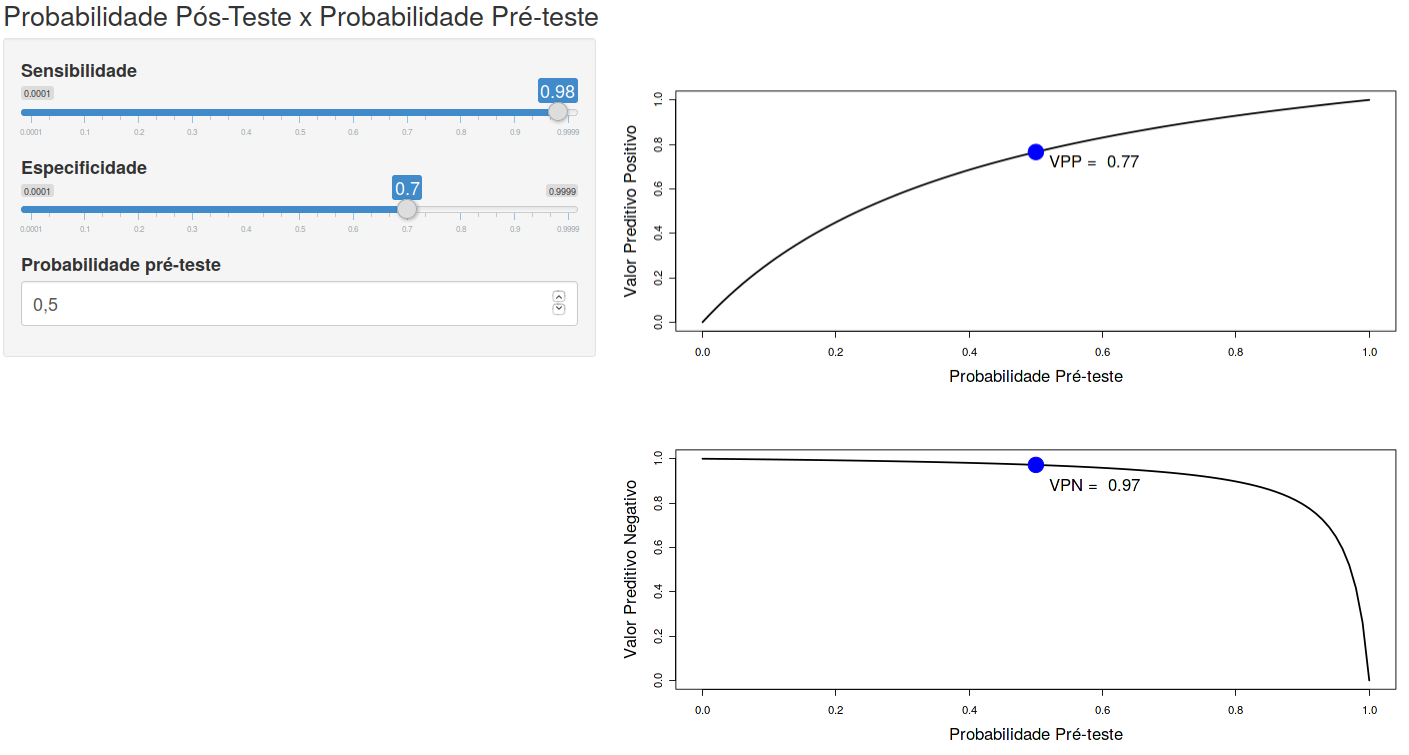
Figura 12.5: Aplicação que permite visualizar a dependência das probabilidades pós-teste em relação à prevalência para valores de sensibilidade e especificidade selecionados pelo usuário.
Para cada valor de sensibilidade e especificidade selecionados no painel à esquerda, a curva no gráfico superior mostra como o valor preditivo positivo, ou a probabilidade pós-teste se relaciona com a probabilidade pré-teste.
A curva no gráfico inferior mostra como o valor preditivo negativo se relaciona com a probabilidade pré-teste.
Os pontos em azul nos gráficos mostram os valores preditivos positivos e negativos, respectivamente, para o valor de probabilidade pré-teste selecionado no painel à esquerda.
Assim os valores de sensibilidade e especificidade determinam a curva nos gráficos à direita e o valor de probabiliade pré-teste determina o ponto azul.
É possível observar que as probabilidades pós-teste são fortemente influenciadas pela probabilidade pré-teste da doença. Mesmo se a sensibilidade e a especificidade forem altas, o VPP pode ser baixo se aplicado em uma população com baixa prevalência da doença.
12.2.4.2 Influência da sensibilidade sobre os valores das probabilidades pós-teste
A figura 12.6 mostra a tela inicial da aplicação Influência da Sensibilidade sobre a Probabilidade Pós-Teste. Essa aplicação permite ao usuário visualizar como a sensibilidade afeta a relação das probabilidades pós-teste (VPP e VPN) e a probabilidade pré-teste para diferentes valores de especificidade.
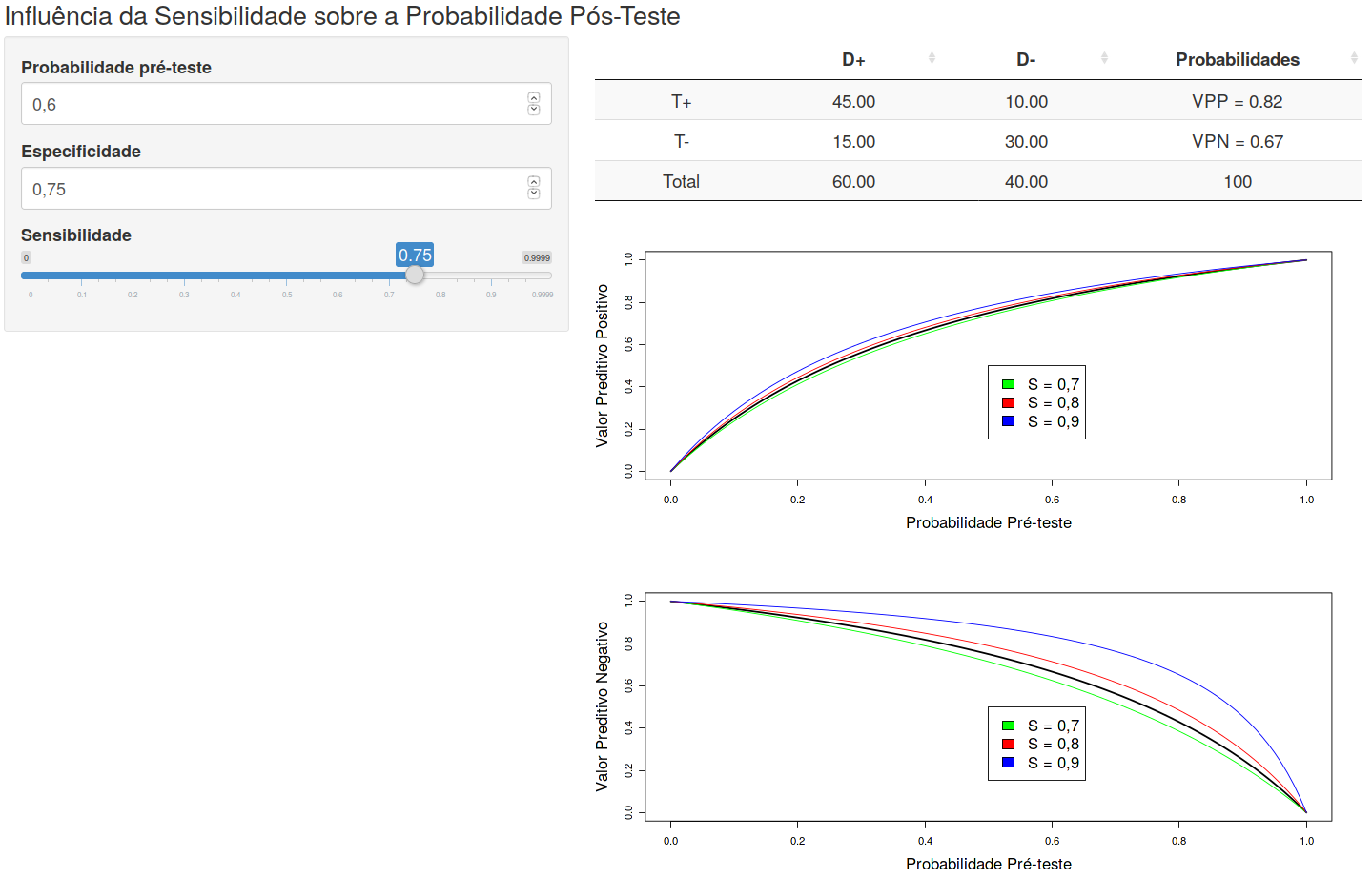
Figura 12.6: Aplicação que mostra a influência da sensibilidade sobre as curvas da probablidade pós-teste em função da prevalência.
Três curvas de referência foram plotadas em cada gráfico, cada uma com um valor diferente de sensibilidade (curvas nas cores vermelho, verde e azul). Para os valores de sensibilidade e especificidade selecionados, as curvas em preto mostram a relação das probabilidades pós-teste e a probabilidade pré-teste.
É possível observar que, para um valor fixo de especificidade, variando a sensibilidade, a curva VPN x probabilidade pré-teste sofre um maior deslocamento do que a curva VPP x probabilidade pré-teste.
A tabela na figura mostra os valores de VPP e VPN para os valores de sensibilidade, especificidade e probabilidade pré-teste selecionados. Quando a sensibilidade se aproxima de 1, a parcela do denominador da fórmula do VPN (indicada pelo círculo 3 na tabela da figura 12.4) se aproxima de 0 e o VPN se aproxima de 1 (100%).
Assim um teste com maior sensibilidade tem maior resolução quando o seu resultado é negativo, aumentando o VPN, mas também, por tender a ter menos falsos negativos, ele poderia ser aplicado na triagem para detectar pessoas com teste positivo e que possam ter a doença confirmada por um teste mais específico.
12.2.4.3 Influência da especificidade sobre os valores das probabilidades pós-teste
A figura 12.7 mostra a tela inicial da aplicação Influência da Especificidade sobre a Probabilidade Pós-Teste. Essa aplicação permite ao usuário visualizar como a especificidade afeta a relação das probabilidades pós-teste (VPP e VPN) e a probabilidade pré-teste para diferentes valores de sensibilidade.
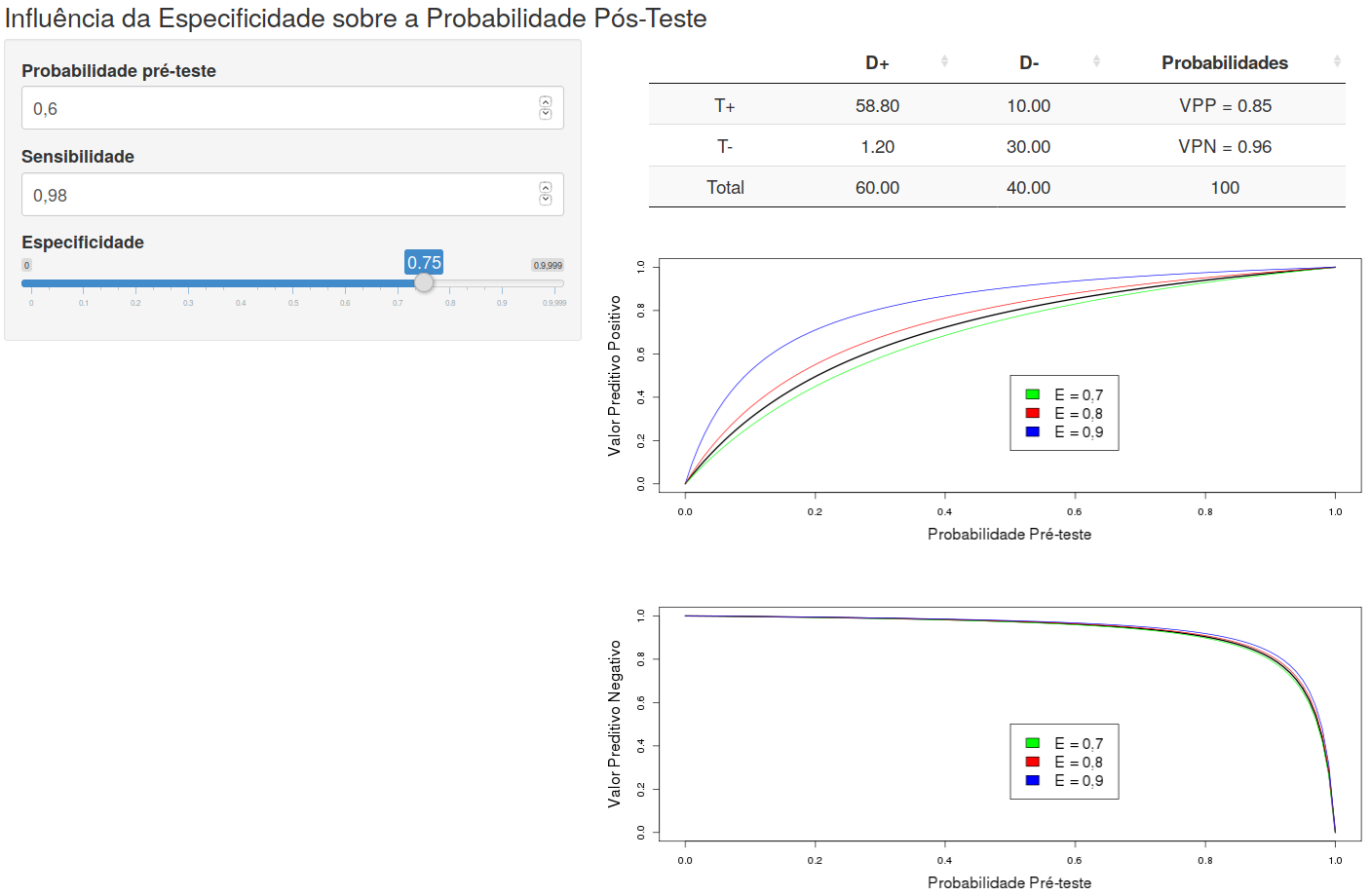
Figura 12.7: Aplicação que mostra a influência da especificidade sobre as curvas da probablidade pós-teste em função da prevalência.
Três curvas de referência foram plotadas em cada gráfico, cada uma com um valor diferente de especificidade (curvas nas cores vermelho, verde e azul). Para os valores de sensibilidade e especificidade selecionados, as curvas em preto mostram a relação das probabilidades pós-teste e a probabilidade pré-teste.
É possível observar que, para um valor fixo de sensibilidade, variando a especificidade, a curva VPP x probabilidade pré-teste sofre um maior deslocamento do que a curva VPN x probabilidade pré-teste.
A tabela na figura mostra os valores de VPP e VPN para os valores de sensibilidade, especificidade e probabilidade pré-teste selecionados. Quando a especificidade se aproxima de 1, a parcela do denominador da fórmula do VPP (indicada pelo círculo 2 na tabela da figura 12.4) se aproxima de 0 e o VPP se aproxima de 1 (100%).
Assim um teste com maior especificidade tem maior resolução quando o seu resultado é positivo, aumentando o VPP, e deve ser utilizado para confirmar o diagnóstico de uma doença.
Uma outra maneira de caracterizar a eficácia de um teste diagnóstico é por meio da medida conhecida como razão de verossimilhança, explicada a seguir.
12.2.5 Razão de verossimilhança
Os conteúdos desta seção e das seções 12.2.6 e 12.3 podem ser visualizados neste vídeo.
Teste positivo
Supondo que o resultado do teste seja positivo e, a partir do teorema de Bayes, temos:
\(\begin{aligned} &\ P(D|T^+) = \frac{P(T^+|D)P(D)}{P(T^+)} \end{aligned}\)
Essa expressão pode ser manipulada da seguinte forma:
\(\begin{aligned} \frac{P(D|T^+)}{1-P(D|T^+)} &= \frac{P(T^+|D)P(D)}{P(T^+)(1-P(D|T^+)}=\frac{P(T^+|D)P(D)}{P(T^+)P(\bar{D}|T^+)} = \\ &=\frac{P(T^+|D)P(D)}{P(T^+|\bar{D})P(\bar{D})} \end{aligned}\)
Logo:
\[\begin{align} \frac{P(D|T^+)}{1-P(D|T^+)} &= \frac{P(T^+|D)}{P(T^+|\bar{D})}\frac{P(D)}{1-P(D)} \end{align}\]
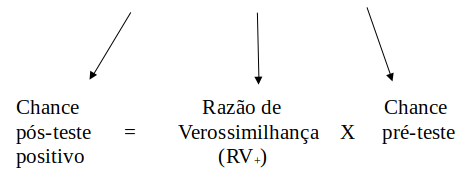
A chance pós-teste positivo é a chance de o indivíduo ter a doença em caso de um resultado positivo do teste. Ela é o produto da razão de verossimilhança para o resultado positivo do teste (RV+) pela chance pré-teste. Podemos escrever a razão de verossimilhança para o resultado positivo do teste como:
\[\begin{align} RV_+ = \frac{P(T^+|D)}{P(T^+|\bar{D})}= \frac{S}{1-E} \tag{12.7} \end{align}\]
Uma vez calculada a chance pós-teste, o valor preditivo positivo será dado por:
\[\begin{align} \frac{P(D|T^+)}{1-P(D|T^+)} = \text{Chance pós-teste} = \frac{VPP}{1-VPP}\ \Rightarrow\ VPP = \frac{\text{Chance pós-teste}}{1+\text{Chance pós-teste}} \end{align}\]
Teste negativo
Supondo que o resultado do teste seja negativo e seguindo um processo semelhante ao descrito para o teste positivo, seguimos os seguintes passos:
\(\begin{aligned} &\ P(D|T^-) = \frac{P(T^-|D)P(D)}{P(T^-)} \end{aligned}\)
que pode ser manipulada da seguinte forma:
\(\begin{aligned} \frac{P(D|T^-)}{1-P(D|T^-)} &= \frac{P(T^-|D)P(D)}{P(T^-)(1-P(D|T^-)}=\frac{P(T^-|D)P(D)}{P(T^-)P(\bar{D}|T^-)} = \\ &=\frac{P(T^-|D)P(D)}{P(T^-|\bar{D})P(\bar{D})} \end{aligned}\)
Logo:
\[\begin{align} \frac{P(D|T^-)}{1-P(D|T^-)} &= \frac{P(T^-|D)}{P(T^-|\bar{D})}\frac{P_{\text{pré-teste}}}{1-P_{\text{pré-teste}}} \end{align}\]
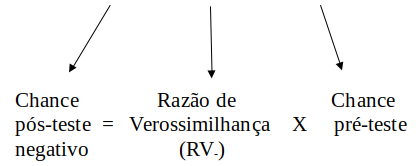
A chance pós-teste negativo é a chance de o indivíduo ter a doença em caso de resultado negativo do teste. Ela é o produto da razão de verossimilhança para o resultado negativo do teste (RV-) pela chance pré-teste. Podemos escrever a razão de verossimilhança para o resultado negativo do teste como:
\[\begin{align} RV_- = \frac{P(T^-|D)}{P(T^-|\bar{D})}= \frac{1-S}{E} \tag{12.8} \end{align}\]
Para o resultado negativo do teste, a chance pós-teste é dada por:
\[\begin{align} \frac{P(D|T^-)}{1-P(D|T^-)} = \frac{1-VPN}{VPN} \Rightarrow 1-VPN = \frac{\text{Chance pós-teste}}{1+\text{Chance pós-teste}} \end{align}\]
Em ambos os casos, chamando de T o resultado do teste (positivo ou negativo), podemos escrever:
\[\begin{align} \frac{P(D|T)}{1-P(D|T)} = \frac{P(T|D)}{P(T|\bar{D})}\frac{P_{\text{pré-teste}}}{1-P_{\text{pré-teste}}} \end{align}\]
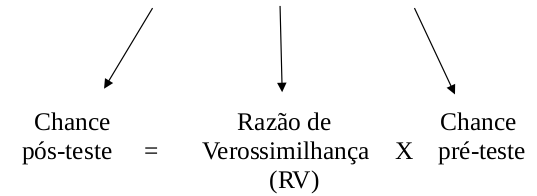
A chance pós-teste é a chance de o indivíduo ter a doença após o resultado do teste. Ela é o produto da razão de verossimilhança pela chance pré-teste.
\[\frac{P(D|T)}{1-P(D|T)} = \text{Chance pós-teste} \Rightarrow P(D|T) = \frac{\text{Chance pós-teste}}{1+\text{Chance pós-teste}}\]
A figura 12.8 mostra os cálculos da razão de verossimilhança, tanto para o resultado positivo do teste quanto para o resultado negativo. Para o resultado positivo, calculamos, em primeiro lugar, as proporções de resultados positivos em cada coluna (setas vermelhas). Em seguida, dividimos as duas proporções para obtermos a razão de verossimilhança para o resultado positivo do teste (seta verde). Analogamente, se procede para o cálculo da razão de verossimilhança para o resultado negativo do teste.
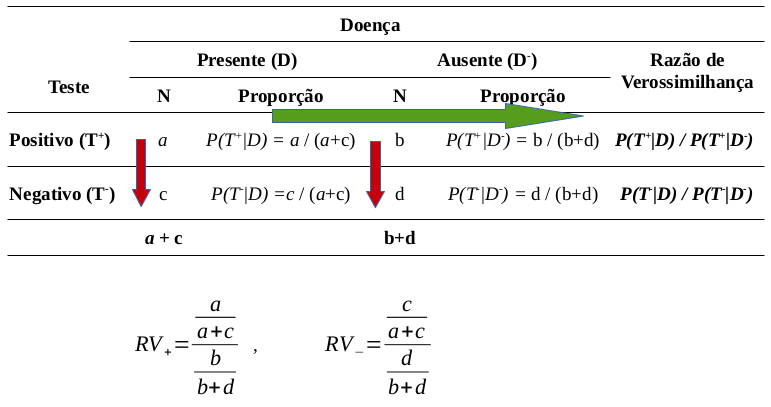
Figura 12.8: Cálculo da razão de verossimilhança. As setas vermelhas e verdes indicam como calcular as razões de verossimilhança para cada resultado do teste.
A tabela 12.5 mostra os cálculos da razão de verossimilhança para os dados do teste rápido molecular (TRM) para detectar a tuberculose. Para um resultado positivo do teste, a chance pós-teste é 54,3 vezes maior do que a chance pré-teste, enquanto que, para um resultado negativo, a chance pós-teste é apenas 0,07 vezes a chance pré-teste.
Este vídeo mostra como calcular os valores de sensibilidade, especificidade e razão de verossimilhança para um teste dicotômico no R.
| D | \(\boldsymbol{\bar{D}}\) | Razão de Verossimilhança | |
|---|---|---|---|
| T+ | 54 | 7 | \(RV_+ = \frac{\frac{54}{58}}{\frac{7}{408}} = 54,3\) |
| T- | 4 | 401 | \(RV_- = \frac{\frac{4}{58}}{\frac{401}{408}} = 0,07\) |
| 58 | 408 |
12.2.6 Influência da razão de verossimilhança sobre a probabilidade pós-teste
A figura 12.9 mostra a tela inicial da aplicação Probabilidade Pós-Teste x Probabilidade Pré-teste e Razão de Verossimilhança. Essa aplicação permite ao usuário visualizar como a razão de verossimilhança afeta a relação da probabilidade de doença pós-teste e a probabilidade pré-teste. O usuário pode variar os valores da razão de verossimilhança e visualizar como se altera o gráfico da probabilidade de doença pós-teste x probabilidade pré-teste. Para um dado valor de probabilidade pré-teste e razão de verossimilhança, o valor da probabilidade de doença pós-teste é apresentado no gráfico. A razão de verossimilhança pode assumir valores entre 0 e infinito, sendo o valor 1 aquele que não afeta a chance pós-teste.
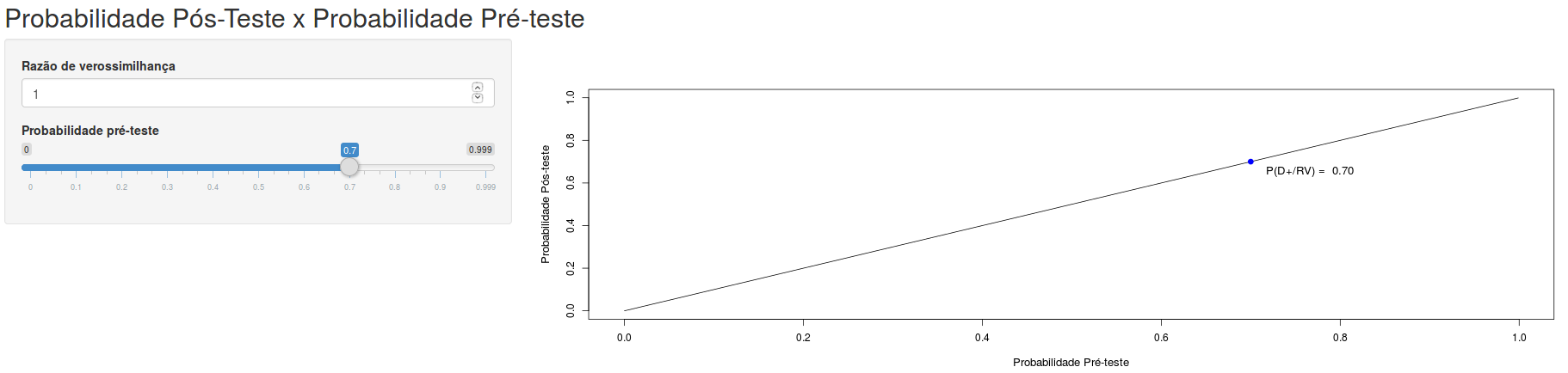
Figura 12.9: Aplicação que permite ao usuário visualizar a influência da razão de verossimilhança sobre a curva probabilidade de doença pós-teste x probabilidade pré-teste.
Quanto mais aumentamos o valor da razão de verossimilhança para o resultado de um teste, mais a curva da probabilidade de doença pós-teste x probabilidade pré-teste se desloca para cima e para a esquerda (figura 12.10). Quanto mais diminuirmos o valor da razão de verossimilhança para o resultado de um teste, mais a curva da probabilidade de doença pós-teste x probabilidade pré-teste se desloca para baixo e para a direita (figura 12.11). Assim um bom teste é aquele que possui alto valor de razão de verossimilhança (bem acima de 1) para o resultado positivo e baixo valor da razão de verossimilhança para o resultado negativo (bem abaixo de 1).
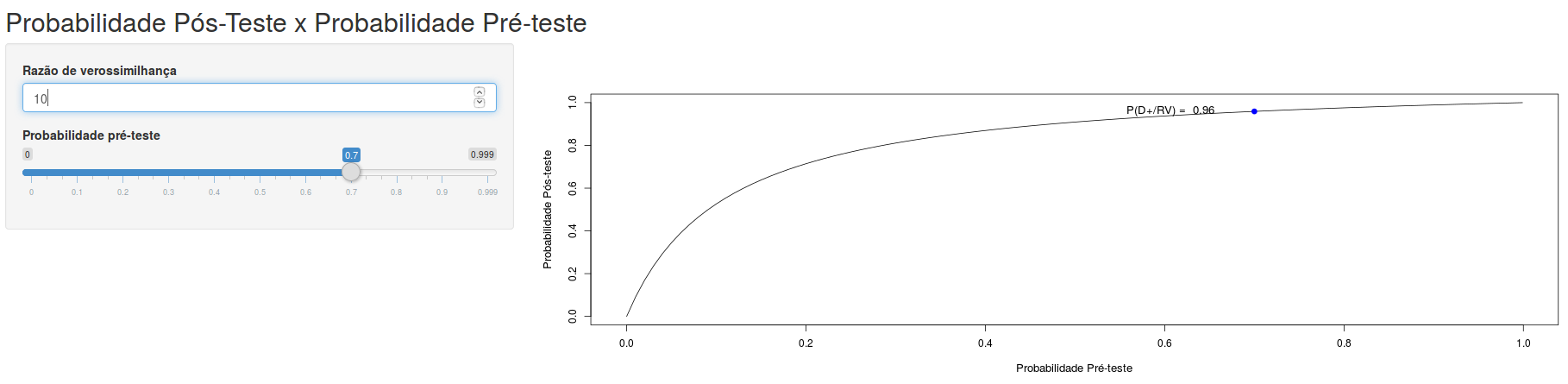
Figura 12.10: Quanto maior a razão de verossimilhança do resultado de um teste, mais a curva da probabilidade de doença pós-teste x prevalência se desloca para cima e para a esquerda.
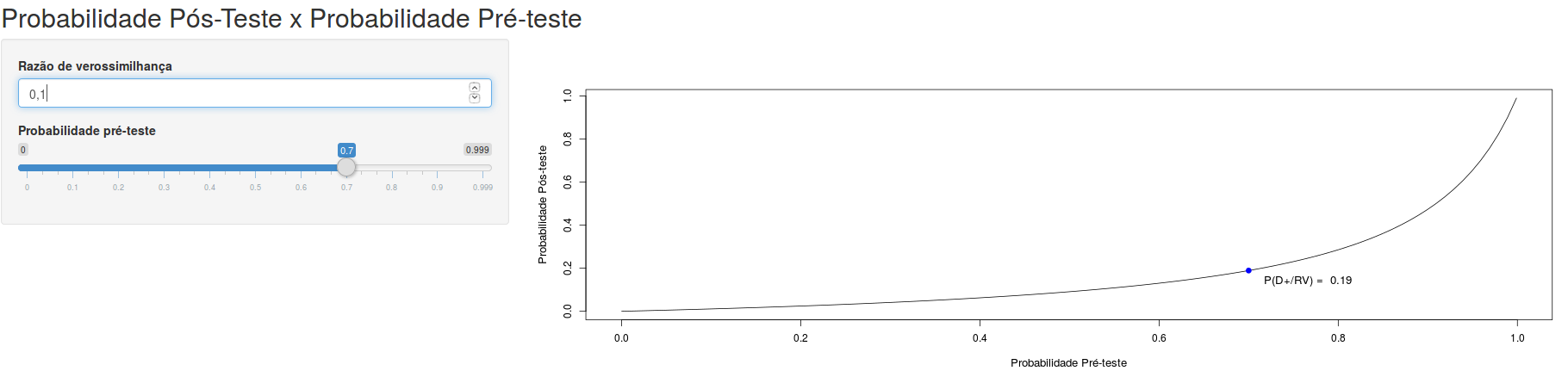
Figura 12.11: Quanto menor a razão de verossimilhança do resultado de um teste, mais a curva da probabilidade de doença pós-teste x prevalência se desloca para baixo e para a direita.
12.3 Variável de teste categórica ordinal
A tabela 12.6 mostra a distribuição de valores da glicemia em 2 horas em um teste de tolerância à glicose de mulheres com herança dos indígenas Pima, diabéticas e não diabéticas. Essa tabela foi construída a partir do conjunto de dados PimaIndiansDiabetes2, disponível no pacote mlbench (Leisch and Dimitriadou 2010) (GPL-2).
Nessa tabela, o resultado do teste diagnóstico é expresso por uma variável categórica ordinal, com 4 categorias e não como uma variável binária. Se esse estudo fosse analisado em termos de sensibilidade e especificidade, teríamos que dicotomizar o resultado do teste, escolhendo uma categoria de corte. Uma possibilidade seria considerar como positivo somente os testes com valores de glicemia de 2 horas acima de 160 mg/dl e como negativo os demais resultados. Uma alternativa seria considerar como positivo os testes com valores de glicemia de 2 horas acima de 120 mg/dl e como negativo os demais resultados. Em quaisquer dos casos, a escolha irá considerar como do mesmo grupo (positivo ou negativo) resultados em diferentes faixas de glicema de 2 horas.
| Faixas de valores da glicemia em 2 horas (mg/dl) | Diabetes Presente | Diabetes Ausente |
|---|---|---|
| (160 - 200] | 83 | 18 |
| (120 - 160] | 112 | 136 |
| (80 - 120] | 69 | 303 |
| (40 - 80] | 2 | 40 |
| 266 | 497 |
O uso da razão de verossimilhança evita esse problema. Generalizando o resultado mostrado na seção 12.2.5, a razão de verossimilhança pode ser calculada para cada resultado do teste separadamente, pela fórmula abaixo, onde T é o correspondente resultado do teste:
\[\begin{align} RV = \frac{P(T|D)}{P(T|\bar{D})} \tag{12.9} \end{align}\]
A chance de o paciente ter a doença para um determinado resultado do teste é dada pela expressão

A figura 12.12 ilustra o cálculo da razão de verossimilhança para cada uma das faixas de glicemia em 2 horas em um teste de tolerância à glicose da tabela 12.6. Observem como a razão de verossimilhança preserva o carater discriminatório de cada categoria do resultado. Usando a aplicação da figura 12.9, podemos obter a probabilidade de o paciente ter a doença para cada valor de RV e probabilidade pré-teste.
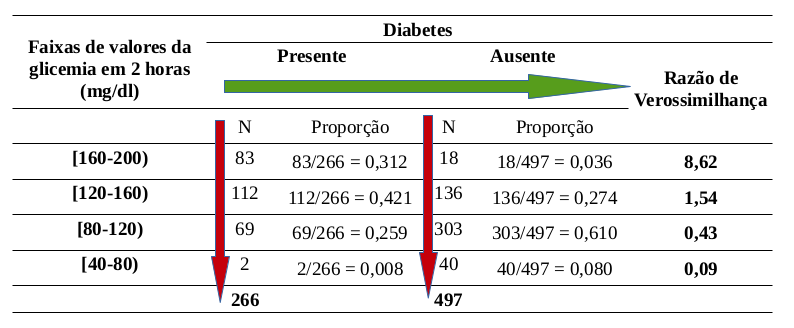
Figura 12.12: Uso da razão de verossimilhança para avaliar a glicemia em 2 horas em um teste de tolerância à glicose para o diagnóstico de diabetes.
12.4 Variável de teste contínua
Os conteúdos das seções 12.4.1 e 12.4.2 podem ser visualizados neste vídeo.
Para variáveis contínuas, como glicemia, pressão arterial sistólica, etc., as medidas de sensibilidade, especificidade, razão de verossimilhança, valores preditivos positivos e negativos também podem ser utilizadas, porém os resultados possíveis terão que ser agrupados em categorias. Para se trabalhar com a especificidade e a sensibilidade, um ponto de corte terá que ser estabelecido, sendo resultados de um lado do ponto de corte considerado como negativo e do outro lado, positivo. Para se trabalhar com a razão de verossimilhança, pode-se dividir a variável de teste em faixas, sendo a razão de verossimilhança calculada para cada faixa do resultado.
Inicialmente será apresentado o conceito da curva ROC.
12.4.1 Curva ROC
A figura 12.13 mostra histogramas da concentração de glicose no plasma em 2 horas em um teste de tolerância à glicose de mulheres com herança dos indígenas Pima, diabéticas e não diabéticas. Esses histogramas foram construídos a partir do conjunto de dados PimaIndiansDiabetes2, disponível no pacote mlbench (GPL-2).
É possível observar que o histograma das diabéticas está deslocado para a direita em relação ao histograma das não diabéticas, mas há uma superposição entre os dois histogramas, que é melhor visualizada quando os dois histogramas são apresentados no mesmo gráfico (figura 12.14). Em ambas as figuras, uma função densidade de probabilidade foi ajustada a cada histograma.
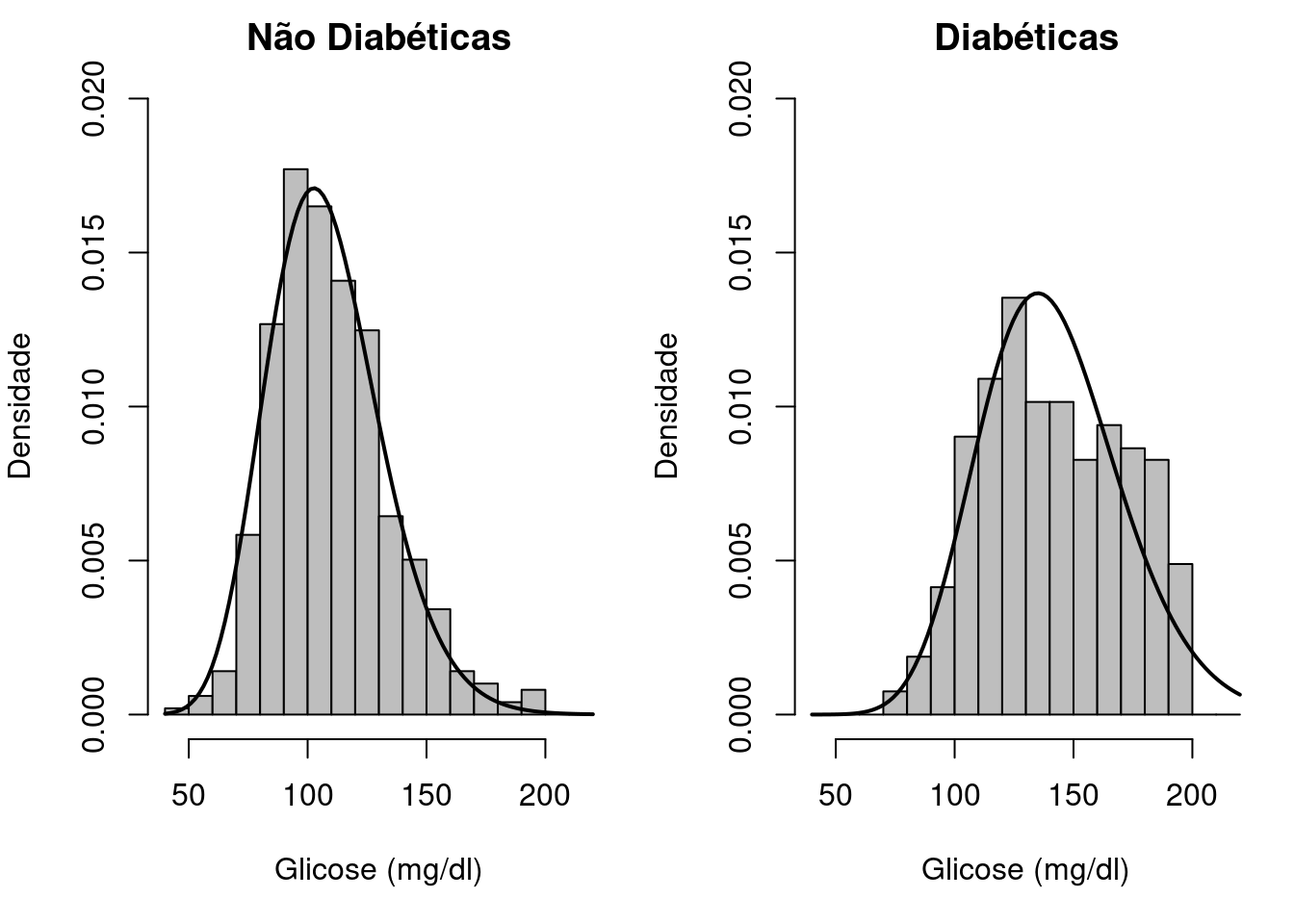
Figura 12.13: Histogramas da glicose de pacientes diabéticas e não diabéticas. Conjunto de dados: PimaIndiansDiabetes2 do pacote mlbench (GPL-2).
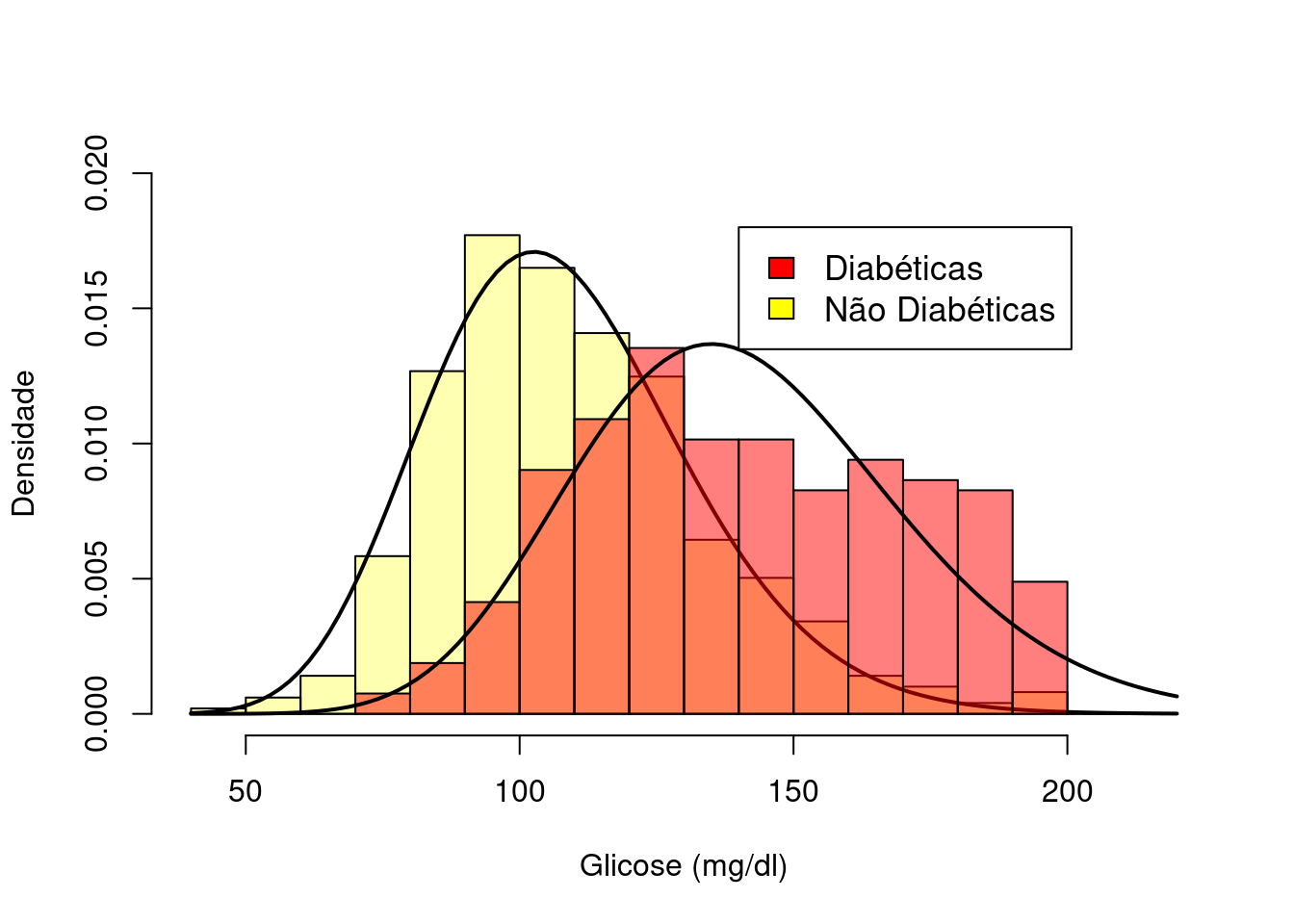
Figura 12.14: Histogramas da glicose de pacientes diabéticas e não diabéticas sobrepostos. Conjunto de dados: PimaIndiansDiabetes2 (Leisch and Dimitriadou 2010) (GPL-2).
Vamos considerar, hipoteticamente, duas populações de pessoas: diabéticas (DIAB) e não diabéticas (NAO DIAB) e que as funções densidade de probabilidade para a variável glicose em 2 horas em um teste de tolerância à glicose para as duas populações sejam como mostradas na figura 12.15.
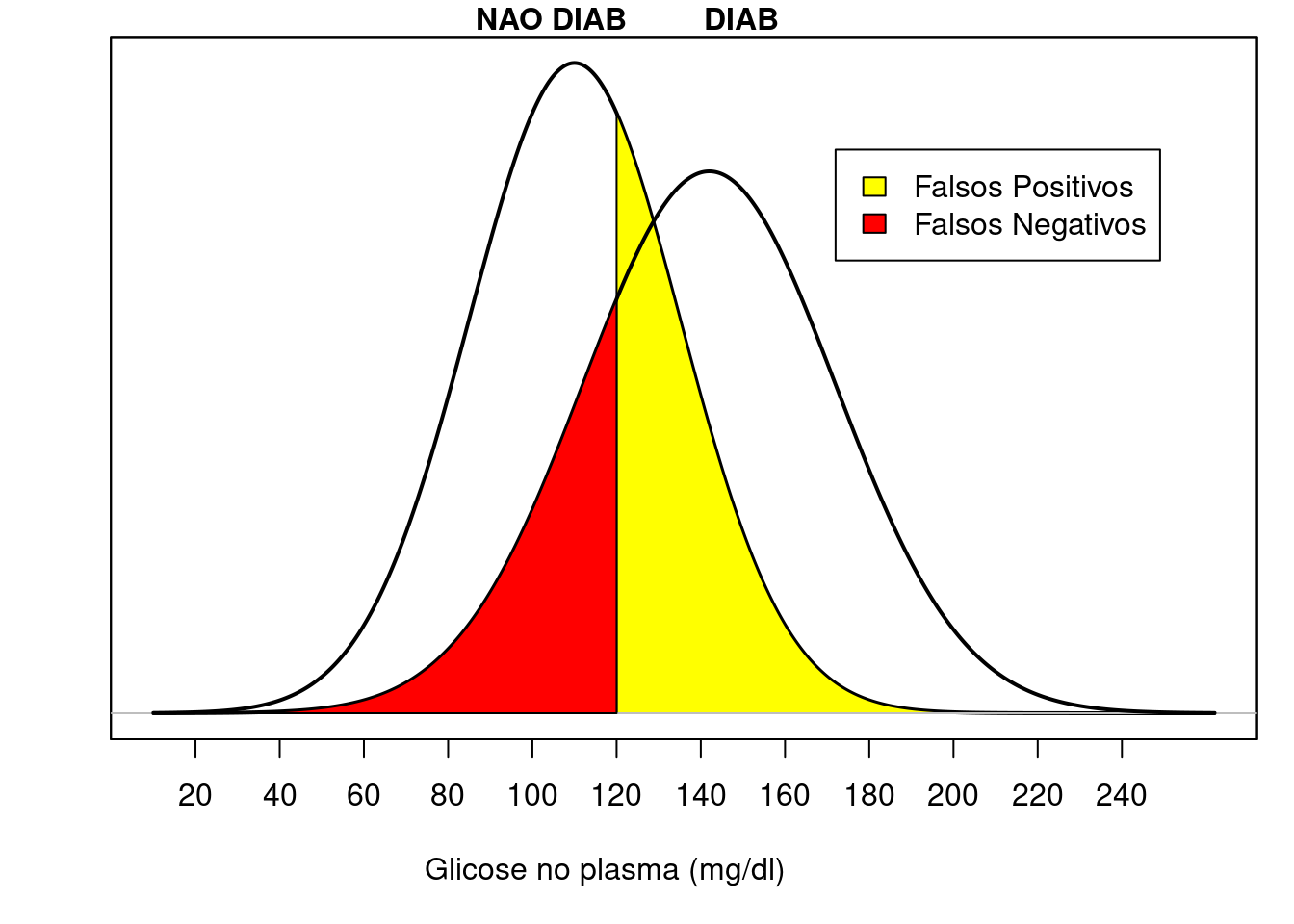
Figura 12.15: Funções densidade de probabilidade da variável glicose em 2 horas em um teste de tolerância à glicose em duas populações: diabéticos (DIAB) e não diabéticos (NAO DIAB). A área em amarelo indica a proporção de falsos positivos e a área em vermelho indica a proporção de falsos negativos, quando o valor 120 mg/dl é escolhido como ponto de corte.
Suponhamos que tenhamos escolhido o ponto de corte do teste igual a 120 mg/dl e consideramos como positivo os resultados acima e negativo os resultados abaixo de 120 mg/dl. Esse ponto divide o gráfico da função densidade das pessoas não diabéticas (NAO DIAB) em duas regiões. A área em amarelo indica a proporção de pessoas não diabéticas que possuem valores de glicose acima de 120 mg/dl. Essas pessoas serão os falsos positivos do teste e a área em amarelo representa a probabilidade de o teste dar positivo em pessoas não diabéticas (P(T+|\(\bar{D}\))). A área sob a curva das pessoas não diabéticas abaixo do ponto de corte representa os verdadeiros negativos ou a especificidade. Analogamente o ponto de corte divide o gráfico da função densidade das pessoas diabéticas (DIAB) em duas regiões. A área em vermelho indica a proporção de pessoas diabéticas que possuem valores de glicose abaixo de 120 mg/dl. Essas pessoas serão os falsos negativos do teste e a área em vermelho representa a probabilidade de o teste dar negativo em pessoas diabéticas (P(T-|D)). A área sob a curva das pessoas diabéticas acima do ponto de corte representa os verdadeiros positivos ou a sensibilidade.
A aplicação Curva ROC (figura 12.16) mostra o efeito sobre a sensibilidade e especificidade quando variamos o ponto de corte de uma variável de teste contínua.
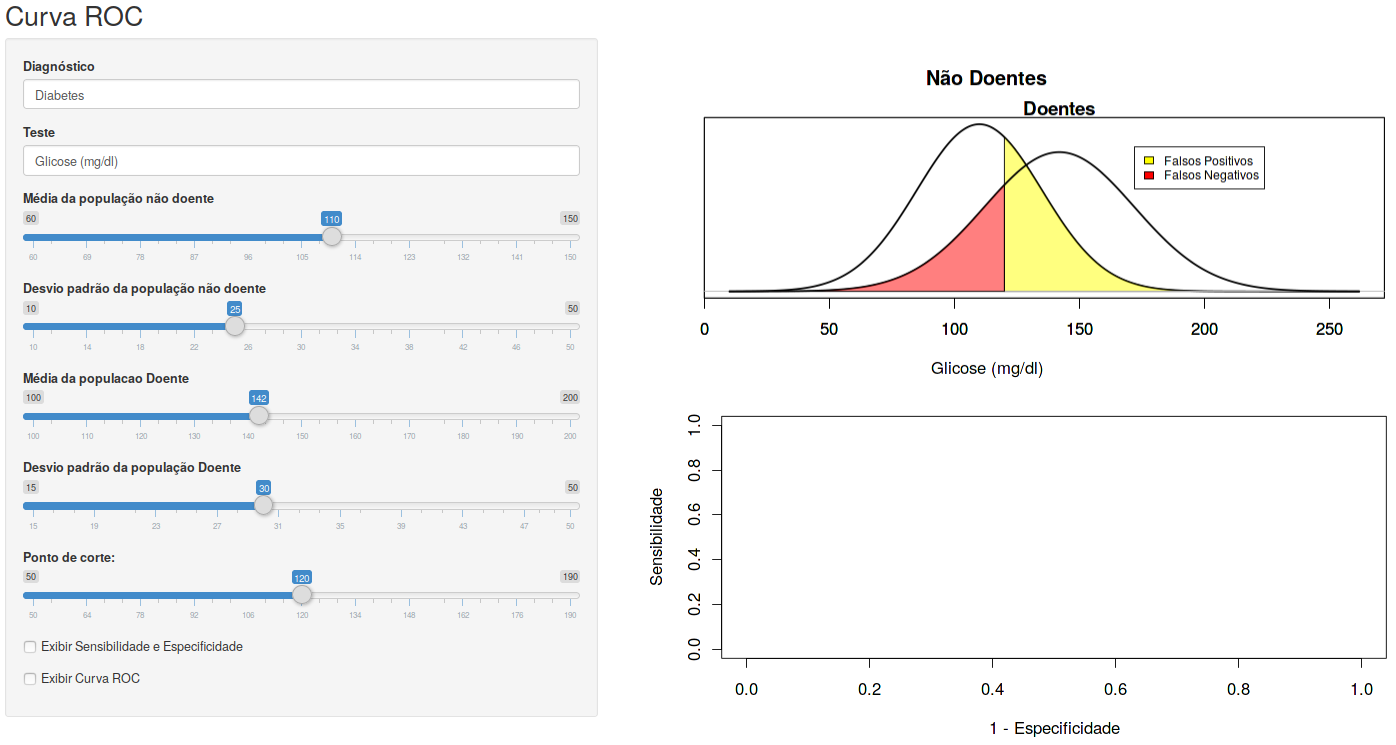
Figura 12.16: Aplicação que permite ao usuário visualizar a construção da curva ROC e a influência do ponto de corte sobre os valores de sensibilidade e especificidade.
Ao marcarmos a caixa de seleção Exibir Sensibilidade e Especificidade, o ponto (azul) correspondente aos valores de sensibilidade e especificidade definidos pelo ponto de corte selecionado será mostrado no gráfico da parte inferior (figura 12.17). O eixo X nesse gráfico corresponde aos valores de 1 - Especificidade e o eixo Y aos valores de Sensibilidade. Para cada ponto de corte, teremos valores correspondentes de especificidade e sensibilidade.
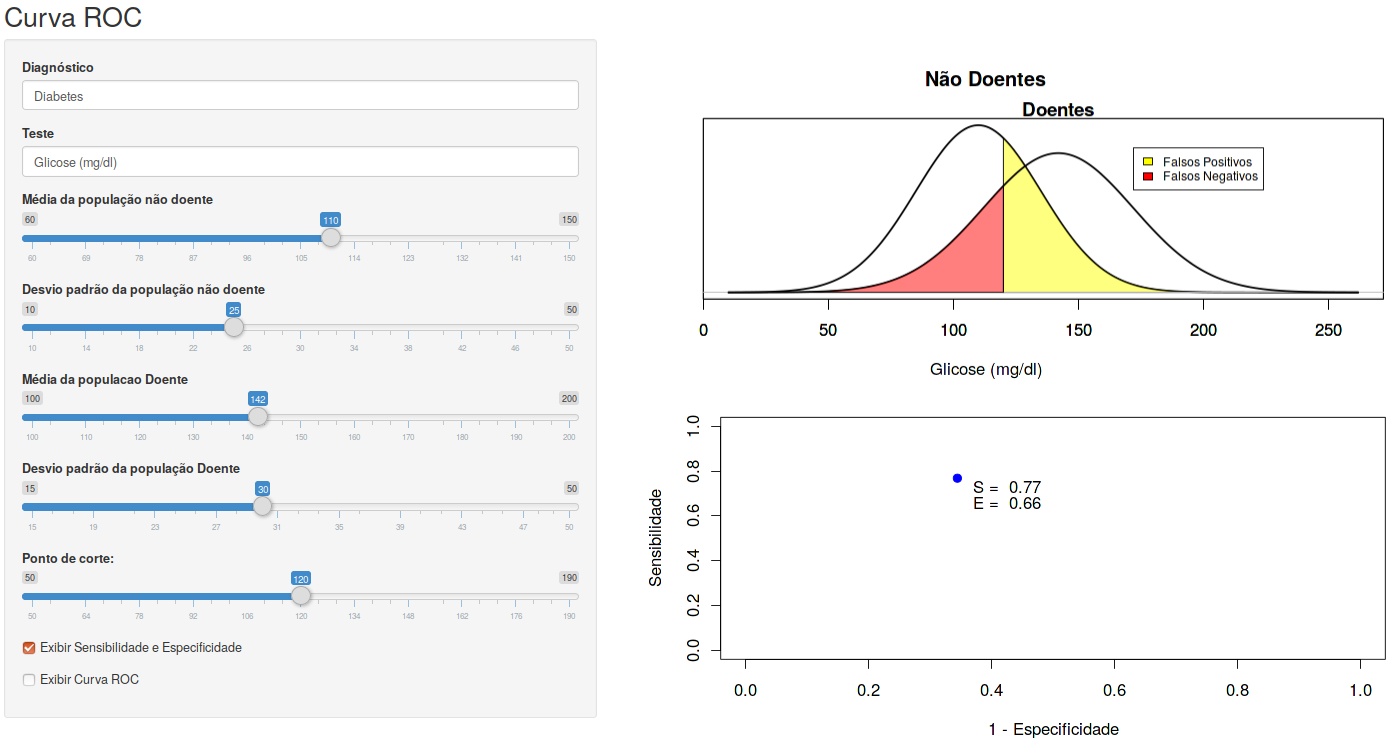
Figura 12.17: Valores da sensibilidade e especificidade para o ponto de corte escolhido na aplicação da figura 12.16.
Ao aumentarmos o ponto de corte, a sensibilidade diminui e a especificidade aumenta. O inverso ocorre se o ponto de corte for diminuído. Se unirmos os pontos cujas coordenadas são (1 – especificidade, sensibilidade) ao variarmos o ponto de corte, obteremos uma curva denominada curva ROC (figura 12.18). Essa curva pode ser visualizada ao marcarmos a caixa de seleção Exibir Curva ROC na aplicação. O termo ROC significa Receiving Operating Characteristics e originou na área de telecomunicação.
O usuário pode variar os parâmetros das duas funções densidades de probabilidade (doentes e não doentes) e o ponto de corte e observar os efeitos sobre a curva ROC.
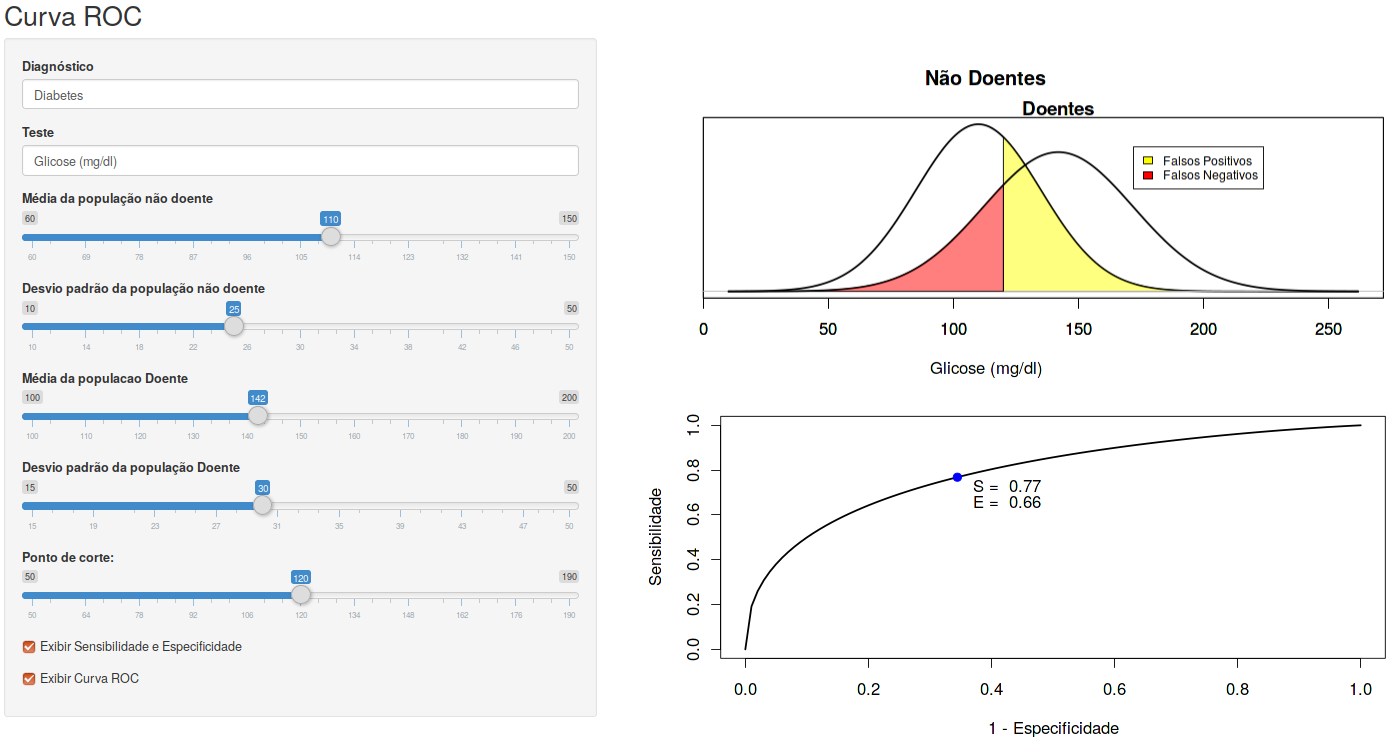
Figura 12.18: Curva ROC gerada a partir da variação do ponto de corte utilizado para classificar o teste como positivo ou negativo.
12.4.2 Comparação de testes
Quando houver dois testes diagnósticos cujas variáveis de teste sejam contínuas, como proceder para compará-los, já que os valores de especificidade e sensibilidade dependem do ponto de corte escolhido? Um critério bastante utilizado é comparar as áreas sob cada uma das curvas ROC. A área sob a curva ROC (AUC - Area Under Curve, em inglês) é a área compreendida entre a curva ROC e o eixo X. Essa área pode variar de 0 a 1. Quanto mais próxima a curva ROC do canto superior esquerdo do gráfico, mais próxima de 1 é a área sob a curva e melhor é o desempenho do teste.
A aplicação Curvas ROC para dois testes (figura 12.19) mostra as curvas ROC de dois testes para o diagnóstico da diabetes (o primeiro usa a glicemia em 2 horas no teste de tolerância à glicose e o segundo o índice de massa corporal). A curva em preto é a curva ROC da glicemia e a curva em azul corresponde ao IMC. Para os parâmetros selecionados na figura 12.19, as curvas ROC não se interceptam e a curva ROC da glicemia possui a maior área. Assim, para este caso, a glicemia é melhor para discriminar os diabéticos pois, para cada valor de especificidade, a glicemia possui maior sensibilidade do que o IMC.
Deve ser observado que ambas as medidas, glicemia e IMC, devido às características de suas curvas ROC, não devem ser usadas isoladamente para estabelecer um diagnóstico de diabetes.
O usuário pode selecionar os parâmetros das funções de probabilidade dos doentes e não doentes para cada teste e verificar as alterações nas respectivas curvas ROC.
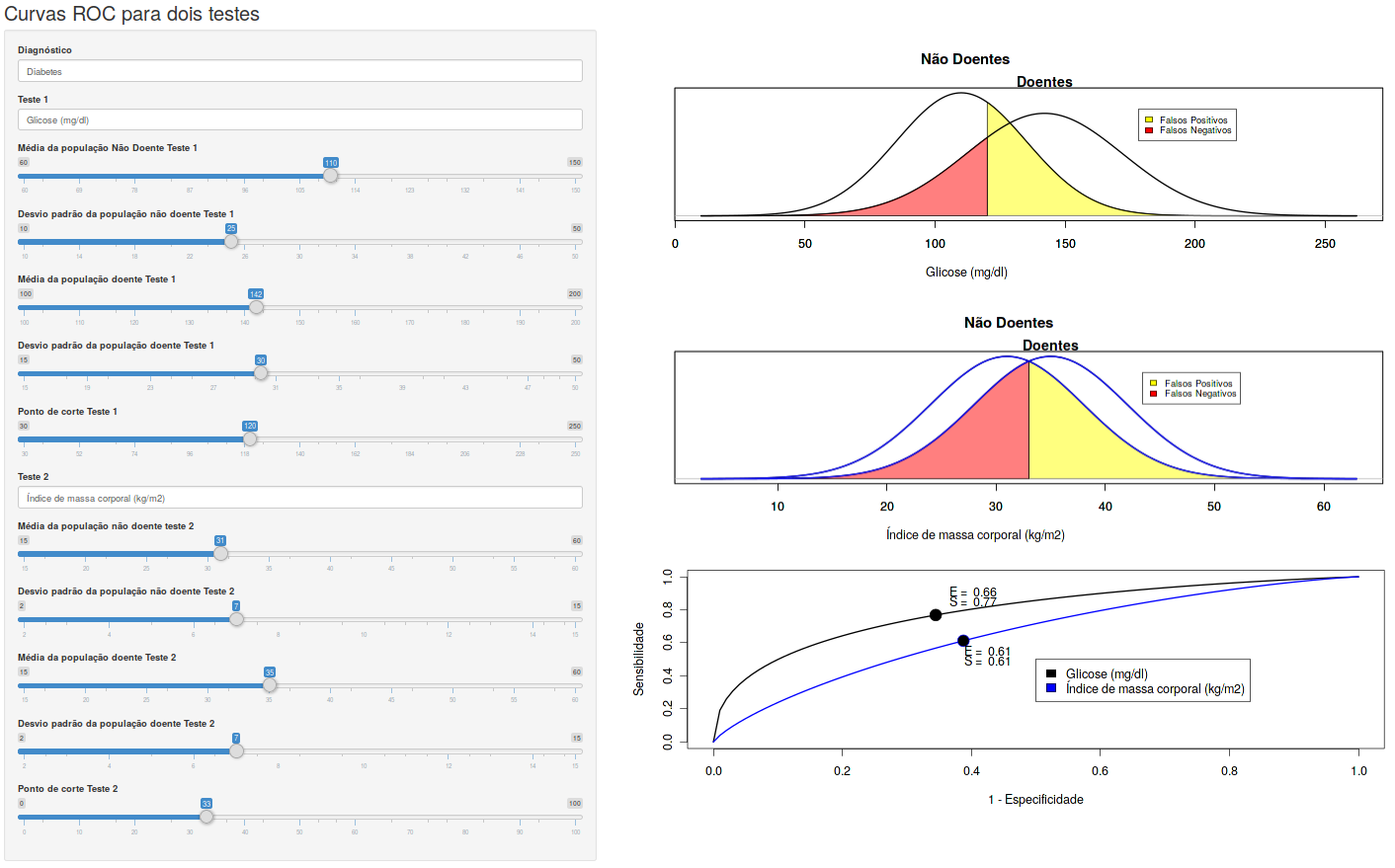
Figura 12.19: Aplicação que permite ao usuário comparar as curvas ROC de dois testes diagnósticos diferentes. A curva ROC preta corresponde ao teste 1 e a azul ao teste 2.
Nem sempre, porém, as curvas ROC se diferenciam como no parágrafo anterior. A figura 12.20 mostra um exemplo de dois testes cujas curvas ROC se interceptam. Nesse caso, a área sob a curva ROC pode não ser o melhor critério para selecionar o melhor teste, pois, à esquerda do ponto de interseção das duas curvas, o teste 2 é melhor, mas o teste 1 é melhor à direita da interseção das duas curvas. Outros fatores terão que ser levados em conta na escolha do melhor teste, tais como: custos, riscos de se tratar pessoas que não possuem a doença (falsos positivos), riscos de não se tratar pessoas que são doentes (falsos negativos), etc.
Outro ponto a ressaltar na comparação de dois testes diagnósticos por meio das respectivas curvas ROC é que as curvas obtidas em um determinado estudo são dependentes da amostra de pacientes do estudo e, portanto, podem variar de amostra para amostra. Assim a comparação de testes diagnósticos cujos resultados são expressos por uma variável numérica deve levar em conta também os intervalos de confiança das diferenças das áreas sob a curva ROC e/ou testes estatísticos que comparam as respectivas curvas ROC, para avaliar tanto a relevância clínica quanto a significância estatística das diferenças observadas.
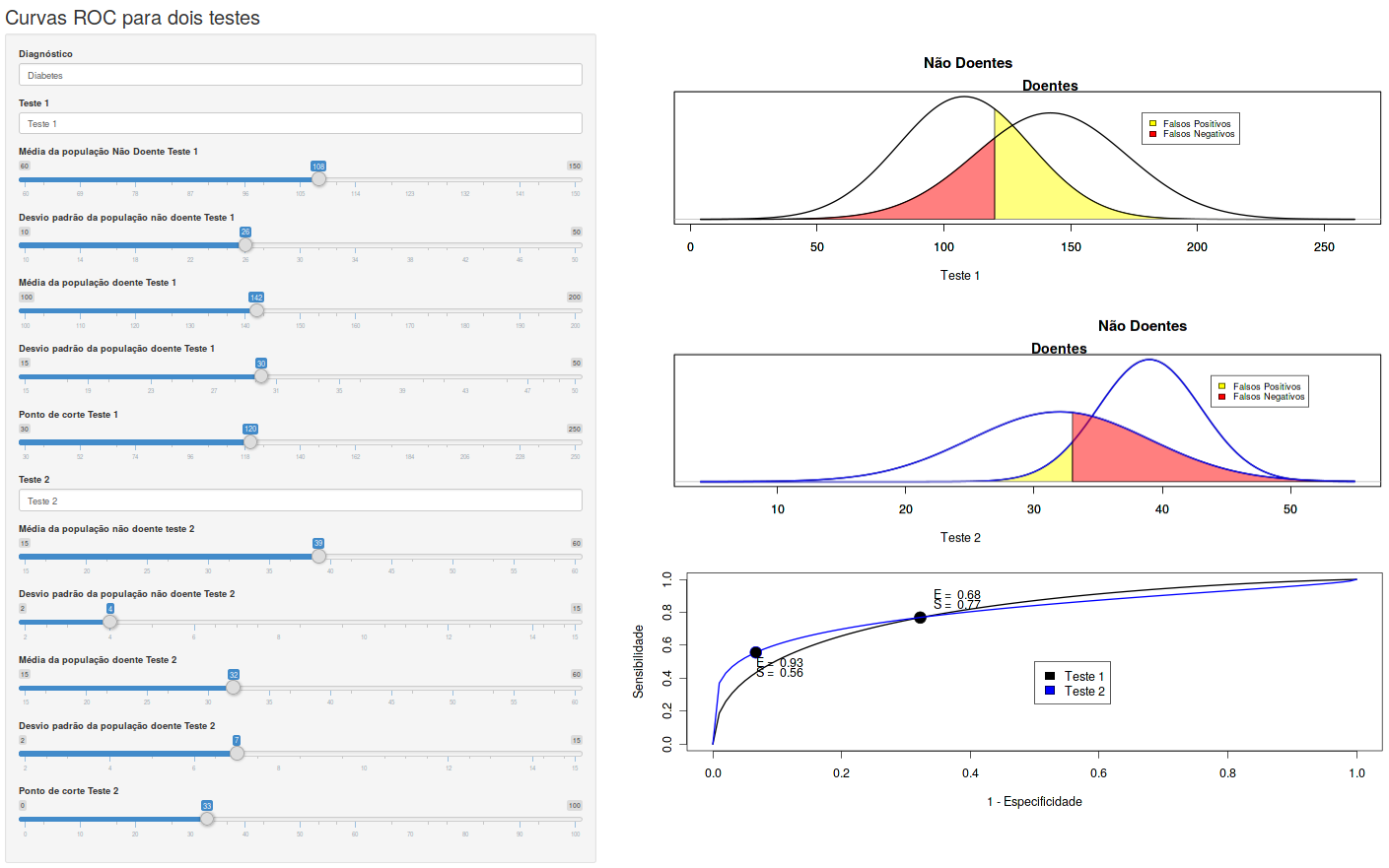
Figura 12.20: Exemplo de dois testes cujas curvas ROC se interceptam. Nesse caso, a área sob a curva ROC pode não ser o melhor critério para selecionar o melhor teste.
12.4.3 Uso da razão de verossimilhança em testes com variáveis contínuas
O conteúdo desta seção pode ser visualizado neste vídeo.
De modo análogo ao caso de uma variável de teste categórica com mais de duas categorias de resultados possíveis, pode-se também usar a razão de verossimilhança em um teste cuja variável é contínua. Para isso, divide-se os limites dos valores possíveis da variável de teste em faixas e calcula-se a razão de verossimilhança para cada faixa. Isso evita a necessidade de se estabelecer um ponto de corte, fazendo com que cada faixa de resultado tenha sua própria influência sobre a probabilidade de doença, quando se estima as chances de que uma determinada doença esteja presente. A tabela 12.7 mostra o cálculo da razão de verossimilhança para a glicemia em 2 horas em um teste de tolerância à glicose para discriminar diabéticos de não diabéticos para diversas faixas de valores, a partir dos mesmos dados da seção 12.4.1.
| Glicose (mg/dl) | Número de pessoas diabéticas (%) | Número de pessoas não diabéticas (%) | Razão de Verossimilhança |
|---|---|---|---|
| (40 - 60] | 0 (0) | 4 (0,8) | 0 |
| (60 - 80] | 2 (0,75) | 36 (7,2) | 0,10 |
| (80 - 100] | 16 (6,0) | 151 (30,3) | 0,20 |
| (100 - 120] | 53 (19,9) | 152 (30,6) | 0,65 |
| (120 - 140] | 63 (23,7) | 94 (18,9) | 1,25 |
| (140 - 160] | 49 (18,4) | 42 (8,5) | 2,18 |
| (160 - 180] | 48 (18,0) | 12 (2,4) | 7,47 |
| (180 - 200] | 35 (13,2) | 6 (1,2) | 10,9 |
| Total | 266 | 497 |
A aplicação Razão de Verossimilhança para Variáveis Contínuas (figura 12.21) mostra os valores da razão de verossimilhança para cada intervalo em que foram distribuídos os valores da variável de um teste diagnóstico. O usuário pode alterar os valores dos parâmetros das funções densidade de probabilidade entre os doentes e não doentes e o número de intervalos em que a variável de teste será dividida. Para cada intervalo, a razão de verossimilhança é calculada dividindo-se a área sob a curva dos doentes (probabilidade de se obter valores no intervalo entre os doentes) pela área sob a curva dos não doentes (probabilidade de se obter valores no intervalo entre os não doentes) no respectivo intervalo.
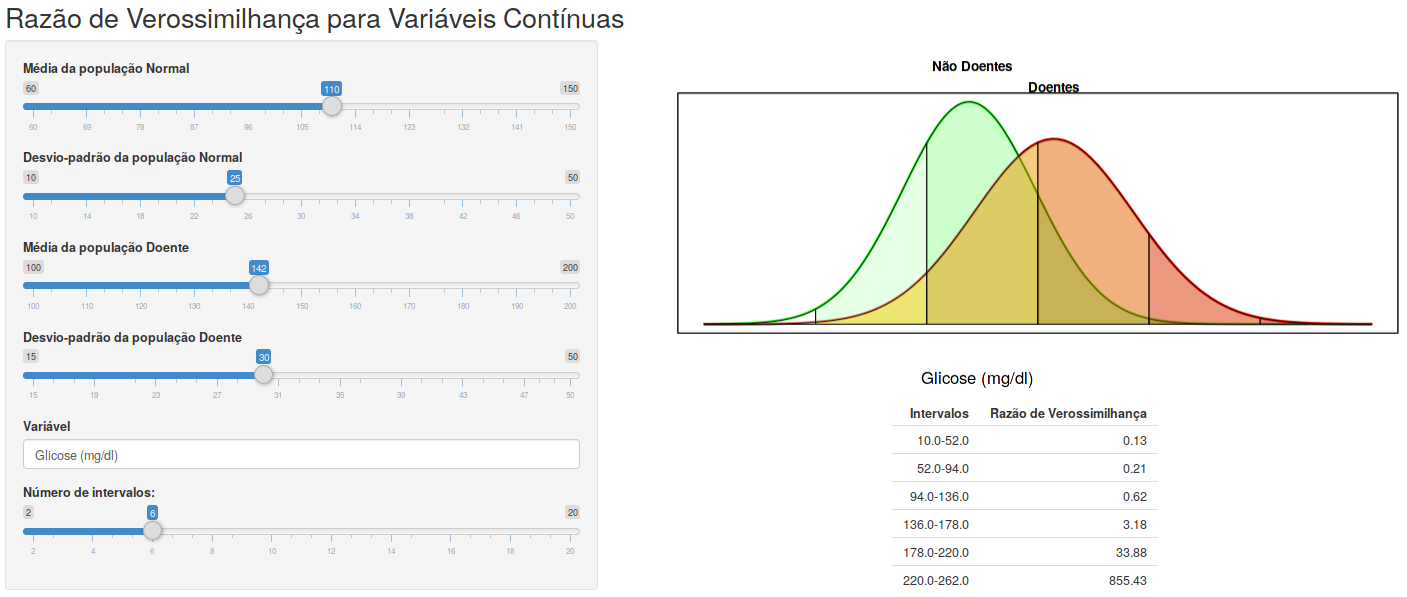
Figura 12.21: Construção da tabela de valores da razão de verossimilhança para cada intervalo em que foi dividida a variável de teste.
12.5 Análise de testes diagnósticos no R
O conteúdo desta seção pode ser visualizado neste vídeo.
Diversos pacotes do R podem ser utilizados para analisar dados relativos à avaliação de testes diagnósticos. Vamos utilizar nesta seção os pacotes epiR (também utilizado no capítulo 8) e o RcmdrPlugin.ROC (GPL-2 | GPL-3). Vamos continuar a utilizar o conjunto de dados PimaIndiansDiabetes2, do pacote mlbench (Leisch and Dimitriadou 2010) (GPL-2).
Inicialmente, vamos ler o conjunto de dados. Para isso, precisamos instalar o pacote mlbench:
Em seguida, carregamos o pacote mlbench e o conjunto de dados PimaIndiansDiabetes2:
Para visualizar a descrição desse conjunto de dados, utilize o comando:
Vamos trabalhar com três variáveis do conjunto de dados PimaIndiansDiabetes2:
- glucose: concentração de glicose no plasma em 2 horas em um teste de tolerância à glicose (mg/dl);
- diabetes: variável dicotômica, pos - diabética, neg - não diabética;
- mass: índice de massa corporal (kg/m2).
Vamos verificar as métricas para glucose como variável de teste diagnóstico de diabetes mellitus gestacional. Para calcular os valores de sensibilidade, especificidade e razão de verossimilhança para o resultado positivo/negativo, vamos inicialmente utilizar o pacote epiR. Como a variável glucose é contínua, temos que estabelecer um ponto de corte. Vamos supor que escolhamos o valor 120 mg/dl como ponto de corte. Então temos que montar uma tabela 2 x 2, que relaciona o teste positivo (glucose > 120 mg/dl) com o verdadeiro status da doença.
Inicialmente, vamos criar uma variável dicotômica, glucose_bin, que assumirá os valores:
- Positivo, caso glucose > 120 mg/dl;
- Negativo, caso glucose \(\le\) 120 mg/dl.
Para criar essa variável, vamos recodificar a variável glucose, utilizando a seguinte opção no R Commander:
\[\text{Dados} \Rightarrow \text{Modificação var. conj. dados} \Rightarrow \text{Recodificar variáveis}\]
A tela para recodificação no R Commander deve ser preenchida como mostra a figura 12.22. Nessa tela, o nome da variável recodificada é glucose_bin, a opção Faça de cada nova variável um fator foi marcada para que a nova variável seja da classe factor. As instruções para recodificação são:
- 0:120 = “Negativo” -> indica que os valores de glucose menores ou iguais a 120 mg/dl serão recodificados para Negativo na variável glucose_bin;
- 121:hi = “Positivo” -> indica que os valores de glucose maiores ou iguais a 121 mg/dl serão recodificados para Positivo na variável glucose_bin.
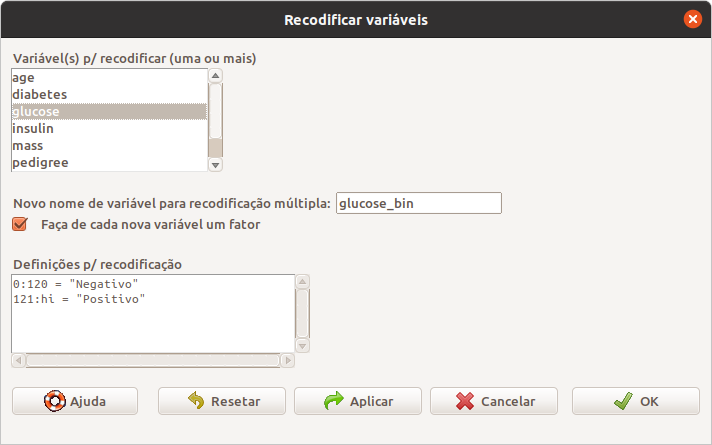
Figura 12.22: Configuração da tela do R Commander para transformar a variável glucose em uma variável dicotômica.
O comando executado é mostrado a seguir:
PimaIndiansDiabetes2 <- within(PimaIndiansDiabetes2, {
glucose_bin <- car::Recode(glucose, '0:120 = "Negativo"; 121:hi = "Positivo"',
as.factor=TRUE)
})Agora, temos que montar uma tabela 2 x 2, que relaciona o resultado do teste (glucose_bin) com o status da doença (diabetes) e obter as métricas de avaliação do teste. A seguinte sequência de comandos obtém as medidas desejadas:
library(epiR)
PimaIndiansDiabetes2$glucose_bin = ordered(PimaIndiansDiabetes2$glucose_bin,
levels=c("Positivo", "Negativo"))
PimaIndiansDiabetes2$diabetes = ordered(PimaIndiansDiabetes2$diabetes,
levels=c("pos", "neg"))
tab = table(PimaIndiansDiabetes2$glucose_bin, PimaIndiansDiabetes2$diabetes)
epi.tests(tab, conf.level = 0.95)## Disease positive Disease negative Total
## Test positive 195 154 349
## Test negative 71 343 414
## Total 266 497 763
##
## Point estimates and 95 % CIs:
## ---------------------------------------------------------
## Estimation Lower CI Upper CI
## Apparent prevalence 0.457 0.422 0.494
## True prevalence 0.349 0.315 0.384
## Sensitivity 0.733 0.676 0.785
## Specificity 0.690 0.647 0.731
## Positive predictive value 0.559 0.505 0.612
## Negative predictive value 0.829 0.789 0.864
## Diagnstic accuracy 0.705 0.671 0.737
## Likelihood ratio of a positive test 2.366 2.036 2.748
## Likelihood ratio of a negative test 0.387 0.314 0.476
## ---------------------------------------------------------A primeira função acima carrega a biblioteca epiR. Os dois comandos seguintes ordenam os níveis das variáveis glucose_bin e diabetes para que as células da tabela 2x2 do teste possam ser apresentadas corretamente pelo epiR. Esse procedimento é semelhante ao utilizado no capítulo 8.
Em seguida, a função table cria a tabela 2x2 correspondente ao ponto de corte selecionado e a função epi.tests apresenta a tabela e os valores das medidas procuradas com os respectivos intervalos de confiança.
Os valores preditivos positivo e negativo apresentados são calculados, supondo-se que a prevalência da doença seja a mesma apresentada no teste (266/763 = 34,9%). Para outras prevalências, esses valores teriam que ser calculados por meio das expressões (12.4) e (12.6) da seção 12.2.2.
Em seguida, vamos construir a curva ROC que relaciona a diabetes com a variável de teste glucose. Para isso, vamos utilizar o plugin RcmdrPlugin.ROC. Caso o plugin não esteja instalado, use a seguinte instrução para instalá-lo:
Após a instalação, vamos carregar o plugin RcmdrPlugin.ROC, a partir da opção do menu:
\[\text{Ferramentas} \Rightarrow \text{Carregar plugins do Rcmdr}\]
Na tela mostrada na figura 12.23, selecionamos o plugin RcmdrPlugin.ROC e clicamos em OK. Em seguida, aparece uma janela solicitando a reinicialização do R Commander. Clicamos em Sim.
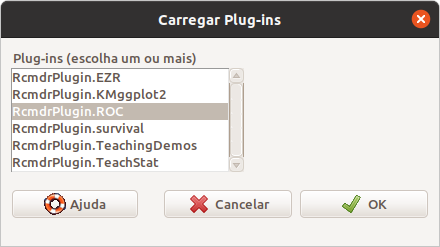
Figura 12.23: Seleção do plugin RcmdrPlugin.ROC para carregamento no R Commander.
Após a reinicialização do R Commander, ativamos novamente o conjunto de dados PimaIndiansDiabetes2, clicando no botão indicado pela seta verde na figura 12.24 e selecionando PimaIndiansDiabetes2 na tela seguinte (figura 12.25).
Figura 12.24: Botão do R Commander para selecionar um conjunto de dados ativo.
Figura 12.25: Seleção de PimaIndiansDiabetes2 como o conjunto de dados ativo no R Commander.
Para construir a curva ROC, vamos acessar a seguinte opção no menu do R Commander:
\[\text{ROC} \Rightarrow \text{pROC} \Rightarrow \text{plot ROC curve for data...}\]
A figura 12.26 mostra a primeira aba da caixa de diálogo para configurar os parâmetros da curva ROC que será exibida. Nessa aba, selecionamos a variável de teste (glucose) e a variável de desfecho (diabetes). Na aba seguinte (figura 12.27), não vamos mexer nas opções previamente selecionadas. Na terceira aba (AUC), as opções padrões também não serão alteradas (figura 12.28).
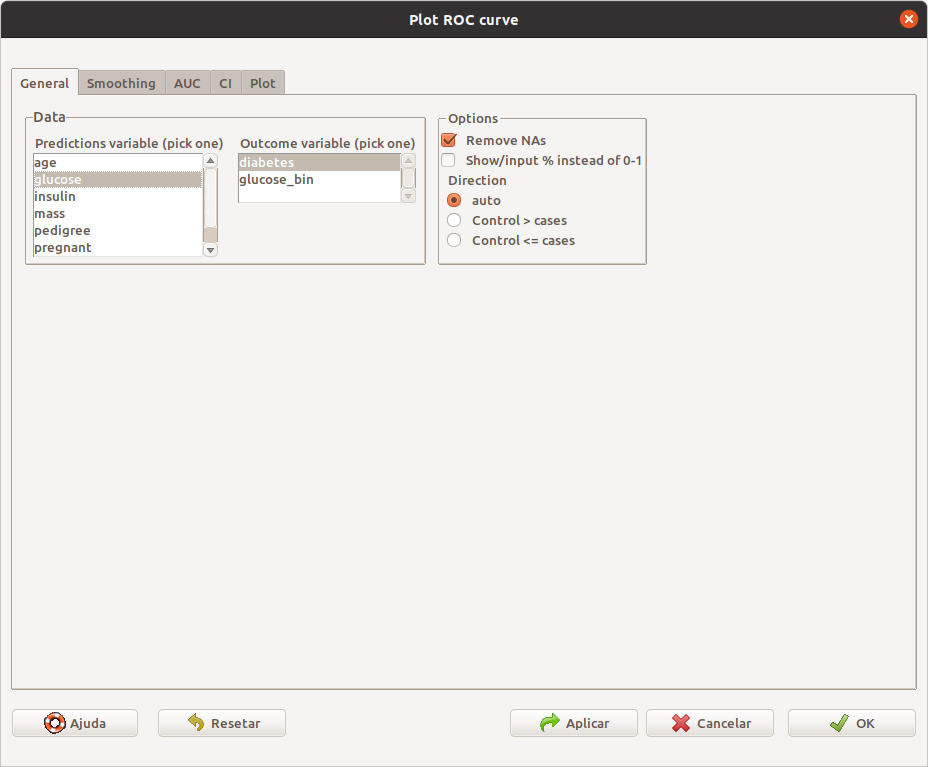
Figura 12.26: Diálogo para configurar a curva ROC: seleção das variáveis.
Figura 12.27: Diálogo para configurar a curva ROC: seleção de métodos para alisamento da curva. Não iremos mexer nestas configurações.
Figura 12.28: Diálogo para configurar a curva ROC: cálculo da área sob a curva ROC. Não iremos mexer nestas configurações.
Na figura 12.29, configuramos que intervalos de confiança serão mostrados e como serão calculados. Vamos marcar a opção se (sensibilidade) e deixar as demais opções padrões.
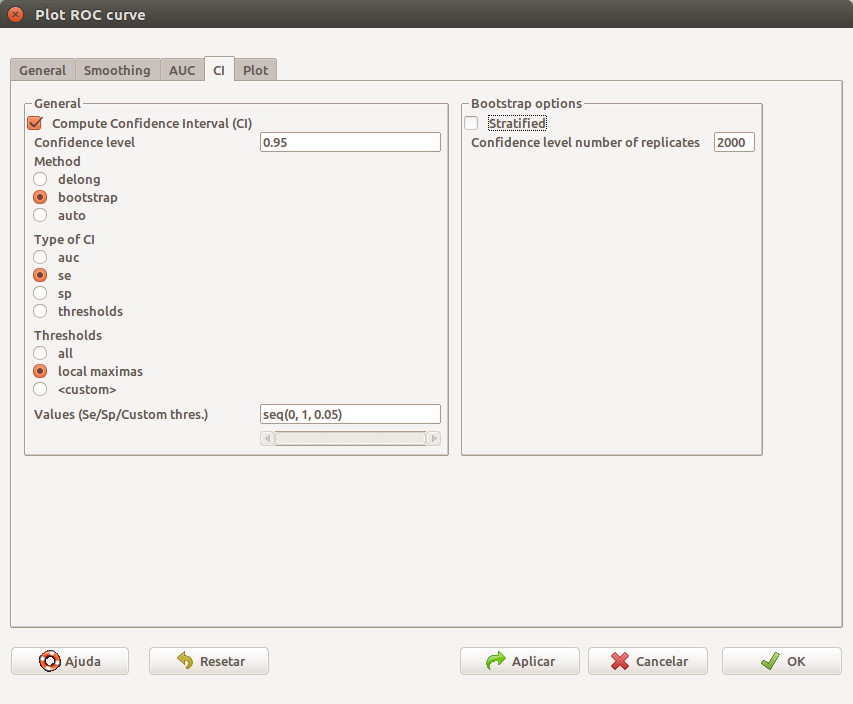
Figura 12.29: Diálogo para configurar a curva ROC: exibição dos intervalos de confiança.
Na figura 12.30, configuramos as opções de plotagem. Vamos marcar as opções Display confidence interval, AUC e best: max(Sum(Sp+Se)), e bars em CI plot type. Também vamos especificar os rótulos que irão ser exibidos nos eixos x e y. A opção AUC vai exibir no gráfico o valor da área sob a curva e o respectivo intervalo de confiança. A opção best: max(Sum(Sp+Se)) vai mostrar na curva ROC o ponto de corte onde é máxima a soma dos valores de especificidade e sensibilidade.
Figura 12.30: Diálogo para configurar a curva ROC: configuração do que será plotado.
Ao pressionarmos o botão OK, o gráfico será exibido (figura 12.31). Observem as barras que delimitam os intervalos de confiança para os valores da sensibilidade. Prestem atenção também que, ao contrário do exibido nas curvas ROC anteriores, o eixo x mostra a especificidade (e não 1 – especificidade) e que o valor 1 está no ínicio do eixo X e o valor 0 no final.
A área sob a curva ROC é igual a 0,79, com o intervalo de confiança ao nível de 95% variando de 0,76 a 0,83. A soma da especificidade e sensibilidade é máxima para o valor de glicose igual a 123,50. Nesse ponto de corte, a sensibilidade é igual a 0,73 e a especificidade é igual a 0,71.
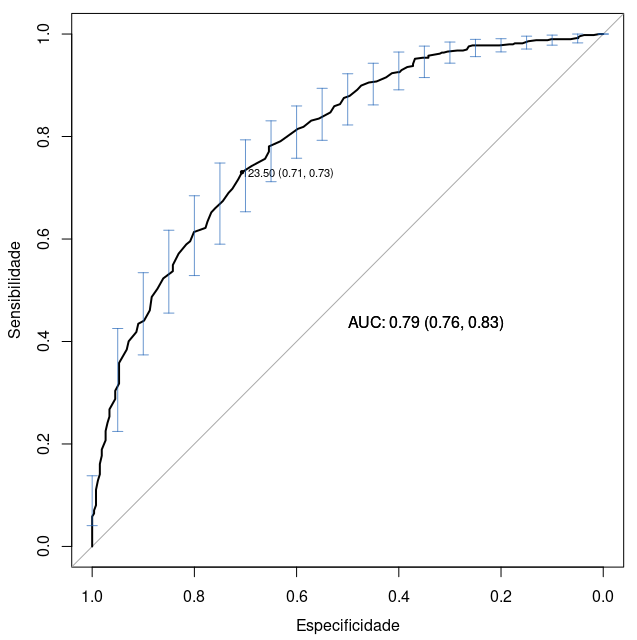
Figura 12.31: Gráfico da curva ROC de diabetes x glicose a partir das configurações estabelecidas nas figuras 12.26 a 12.30.
Ao gerar a curva ROC para o conjunto de dados PimaIndiansDiabetes2, o R Commander utilizou uma série de comandos. Um deles cria um objeto que será utilizado em outros comandos. Esse objeto (roc.obj) contém uma série de dados para construir a curva ROC. Depois de exibir o gráfico, o R Commander remove este objeto, de modo que ele não estará mais acessível. O comando para a criação do objeto é mostrado a seguir:
roc.obj <- pROC::roc(diabetes ~ glucose, data=PimaIndiansDiabetes2,
na.rm=TRUE, percent=FALSE,
direction='auto', partial.auc=FALSE, ci=TRUE,
partial.auc.focus='specificity', conf.level=0.95,
partial.auc.correct=FALSE, auc=TRUE, plot=FALSE,
of='auc', ci.method='bootstrap', boot.n=2000,
boot.stratified=FALSE)Vamos executar esse comando novamente e utilizar o objeto roc.obj para calcular a sensibilidade para diferentes valores de especificidade. Após a execução do comando, o objeto roc.obj estará acessível e o comando abaixo irá calcular os valores de sensibilidade para valores de especificidade entre 0 e 1, com intervalos de 0,05 (figura 12.32):
Observem que, além dos valores de sensibilidade, os intervalos de confiança também são mostrados.
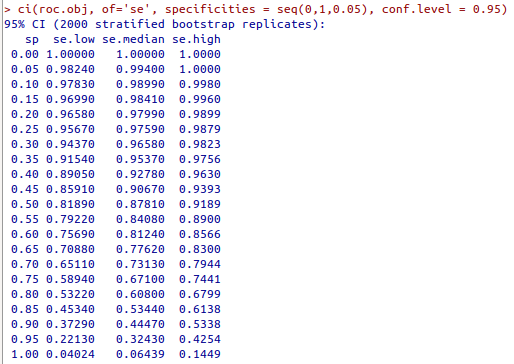
Figura 12.32: Sensibilidades e respectivos intervalos de confiança para diferentes valores de especificidade para glicose x diabetes no conjunto de dados PimaIndiansDiabetes2.
O comando abaixo irá calcular os valores de especificidade para valores de sensibilidade entre 0 e 1, com intervalos de 0,05 (figura 12.33):
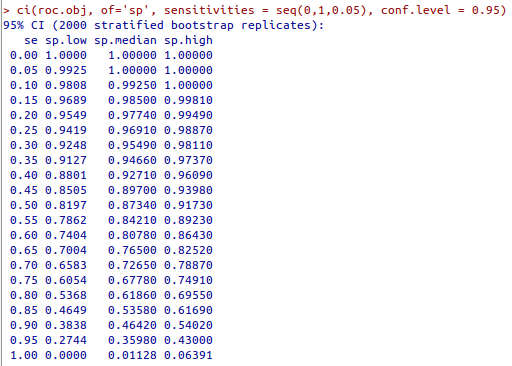
Figura 12.33: Especificidades e respectivos intervalos de confiança para diferentes valores de sensibilidade para glicose x diabetes no conjunto de dados PimaIndiansDiabetes2.
Se, na figura 12.30, tivéssemos selecionado a opção shape em CI plot type (figura 12.34), a curva ROC seria exibida como na figura 12.35.
Figura 12.34: Diálogo para configurar a curva ROC: configuração do que será plotado. Agora vamos selecionar a opção shape em CI plot type.
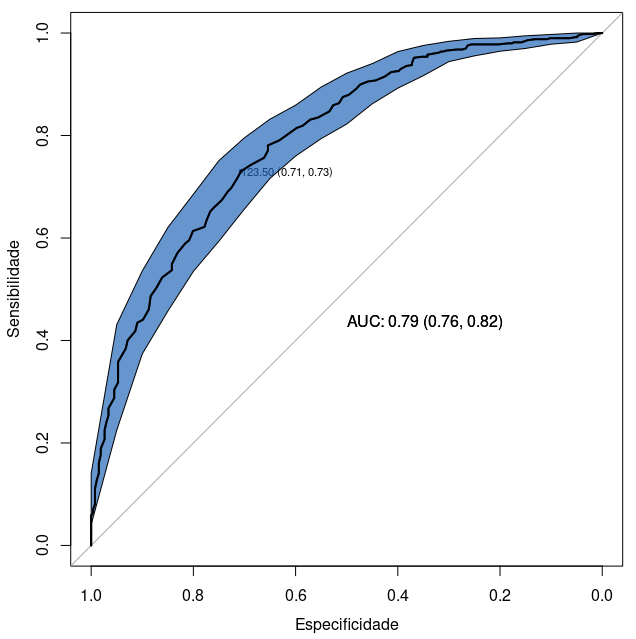
Figura 12.35: Gráfico da curva ROC de diabetes x glicose, dessa vez com os intervalos de confiança desenhados como uma figura sólida.
Para comparar as curvas ROC das variáveis glicemia de 2 horas no teste de tolerância à glicose (glucose) e o índice de massa corporal (IMC - mass), vamos acessar a seguinte opção no menu do R Commander:
\[\text{ROC} \Rightarrow \text{pROC} \Rightarrow \text{Unpaired ROC curves comparison...}\]
Na aba General (figura 12.36), selecionamos as variáveis glucose como variável de predição 1, mass como variável de predição 2 e diabetes como variável de desfecho para as duas curvas, mantendo as demais opções como sugeridas pelo programa.
Figura 12.36: Configurações gerais para a construção de duas curvas ROC, relacionando duas variáveis numéricas com uma doença.
Vamos manter as configurações originais nas abas Smoothing, AUC e CI. Na última aba, Plot, além das opções que já estão selecionadas, vamos marcar as opções Display confidence interval, Display values (Se, Sp e Thresholds), AUC, Test p value e best: max(Se + Sp) (figura 12.37). Ao clicarmos em OK, as duas curvas são mostradas na figura 12.38.
Figura 12.37: Configurações de plotagem para a construção de duas curvas ROC, relacionando duas variáveis numéricas com uma doença.
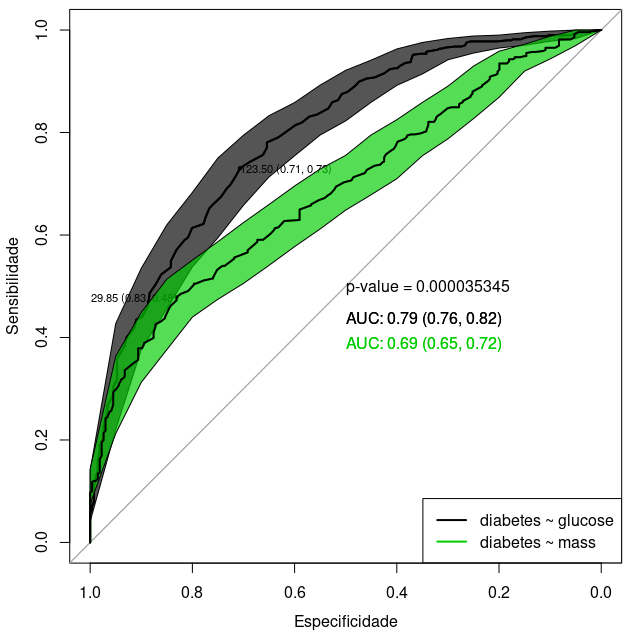
Figura 12.38: Curvas ROC de diabetes x glicose e de diabetes x IMC.
São exibidos os valores da áreas sob a curva e a sensibilidade e a especificidade no ponto onde é maior a soma da especificidade e sensibilidade para cada uma das curvas. Visualmente, vemos que a curva ROC da glicose está mais acima do que a curva ROC do IMC, o que é confirmado pelos valores de AUC para cada curva, os respectivos intervalos de confiança e o valor de p do teste estatístico que compara as áreas das duas curvas. Nesse conjunto de dados, a glicose é melhor preditora de diabetes mellitus gestacional do que o IMC.
Este endereço contém diversos exemplos de curvas ROC que podem ser construídas.
12.6 Exercícios
O gráfico abaixo (figura 12.39) foi extraído do artigo: “The Mini-Addenbrooke’s Cognitive Examination (M-ACE) as a brief cognitive screening instrument in Mild Cognitive Impairment and mild Alzheimer’s disease” (Miranda, Brucki, and Yassuda 2018).
- Descreva em linhas gerais como os autores construiram as curvas ROC apresentadas na figura.
- Em cada curva, qual o valor aproximado da sensibilidade correspondente à especificidade igual a 60%? E os respectivos valores da razão de verossimilhança para um teste positivo?
- Julgando somente pela figura, que teste você considera mais acurado para distinguir a doença de Alzheimer do comprometimento cognitivo leve ou sem comprometimento cognitivo? Justifique.
- Que outras informações você considera necessárias para comparar estatisticamente os dois instrumentos?
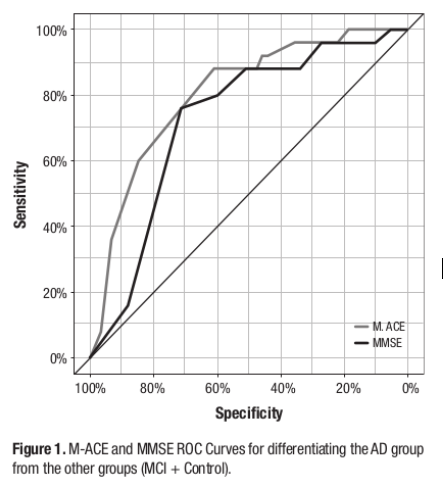
Figura 12.39: Figura 1 do artigo de (Miranda, Brucki, and Yassuda 2018) (CC BY).
- Quais as vantagens de se usar a razão de verossimilhança em relação à sensibilidade e especificidade?
A figura 12.40, mostra a distribuição de valores planimétricos da substância negra entre portadores de Parkinson (PD) e portadores de outras doenças (NPD), respectivamente. Suponha que a linha vermelha seja o ponto de corte (~22) utilizado como critério diagnóstico da doença. Abaixo do ponto de corte, a pessoa seria identificada como negativa e acima, positiva. Responda às questões abaixo.
- Mostre no gráfico a área correspondente aos falsos positivos.
- Mostre no gráfico a área correspondente aos falsos negativos.
- Se aumentarmos o ponto de corte para 28, o que acontece com a sensibilidade? E com a especificidade? Qual a implicação disso em termos clínicos?
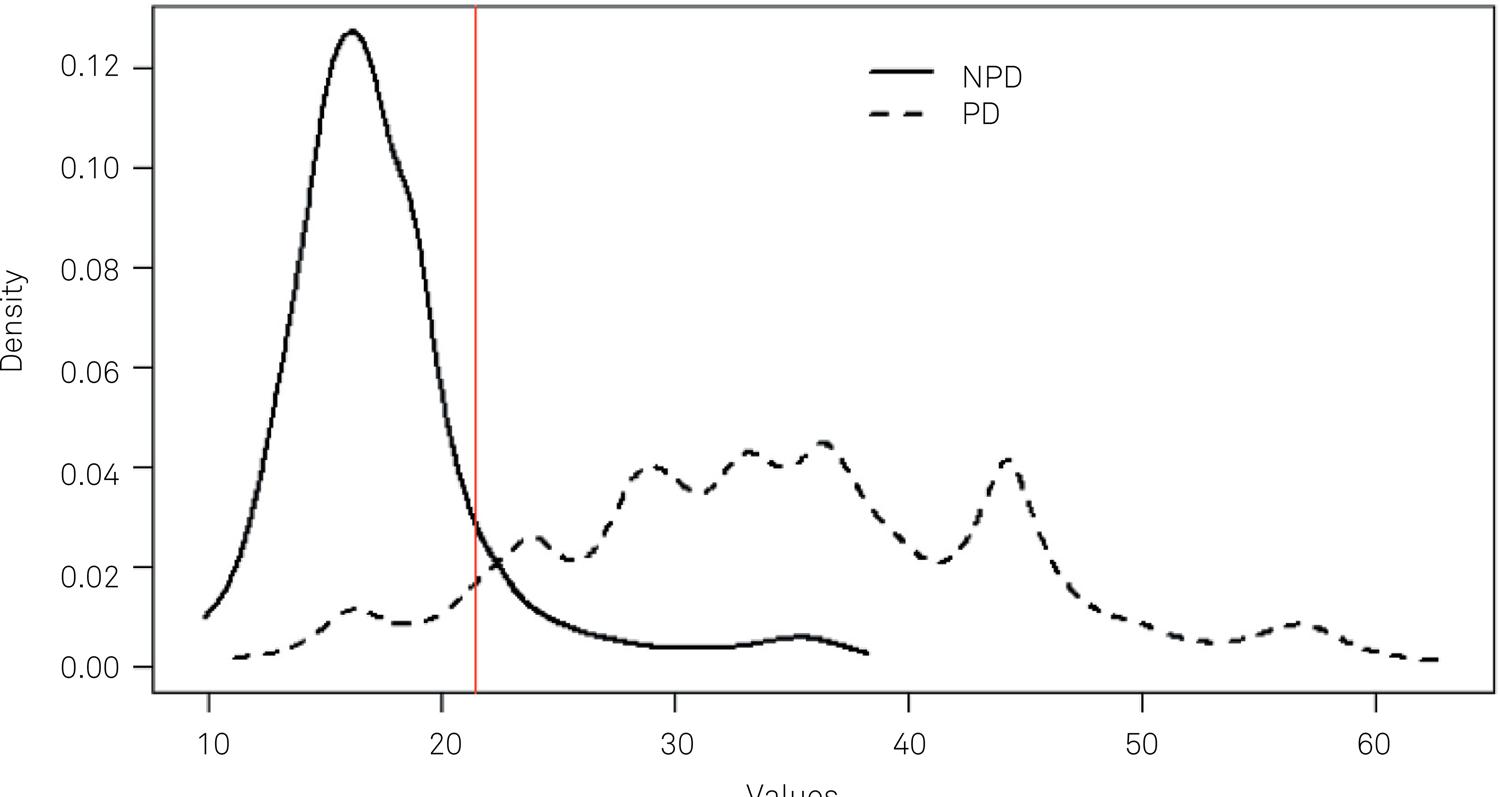
Figura 12.40: Distribuição de valores planimétricos da substãncia negra entre portadores de Parkinson (PD) e portadores de outras doenças (NPD), respectivamente. Fonte: figura 3 do artigo de (Grippe et al. 2018) (CC BY).
Considerando novamente o artigo da questão anterior, a figura 12.41 mostra a tabela 4 desse artigo. Responda às questões abaixo.
- Use o R para calcular as medidas de sensibilidade, especificidade e as razões de verossimilhança para os resultados positivo e negativo do TCS para o diagnóstico da doença de Parkinson, usando um ponto de corte de 20 mm2 (números que não estão entre parênteses), e os respectivos intervalos de confiança.
- Quais são as interpretações dos intervalos de confiança para a especificidade e para a razão de verossimilhança para resultado negativo?
- O que você tem a comentar sobre a precisão dos intervalos de confiança calculados no item a?
- Quais os valores preditivos positivo e negativo do teste, supondo uma prevalência da doença de 1%?
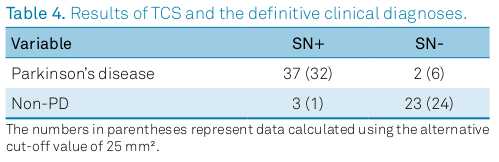
Figura 12.41: Tabela 4 do artigo de (Grippe et al. 2018) (CC BY).
Considere o artigo “Diagnóstico rápido da síndrome do desconforto respiratório por aspirado bucal em recém-nascidos prematuros” (Ribeiro et al. 2019). A figura 12.42 abaixo mostra a figura 3 desse artigo. Responda às questões abaixo.
- Comparem na figura as curvas ROC dos testes das microbolhas estáveis no aspirado bucal e no aspirado gástrico para o diagnóstico do desconforto respiratório. É possível apontar um dos aspirados como mais acurado? Considerem também os valores e o intervalo de confiança para as áreas sob a curva na legenda da figura.
- Indiquem na figura os pontos correspondentes às sensibilidades e especificidades indicadas no parágrafo abaixo da figura 3 no artigo.
- Comente sobre a precisão dos intervalos de confiança para a sensibilidade e especificidade apresentados no parágrafo abaixo da figura.
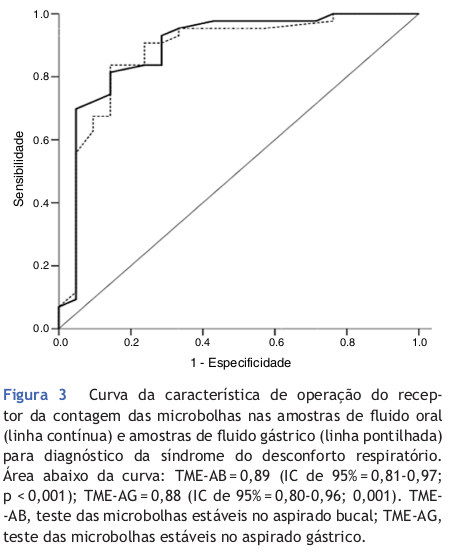
Figura 12.42: Figura 3 do artigo de (Ribeiro et al. 2019) (CC-BY-NC-ND).
Carregue o conjunto de dados elastase do pacote GsymPoint (GPL-2 | GPL-3) do R.
- Instale o pacote GsymPoint.
- Verifique a ajuda do conjunto de dados elastase.
- Converta a variável status para fator.
- Construa a curva ROC para avaliar a utilidade clínica da determinação da elastase leucocitária no diagnóstico da doença arterial coronariana (DAC).
- Discuta os resultados.